
案例介绍
网页爬取工具作品介绍
作品概述
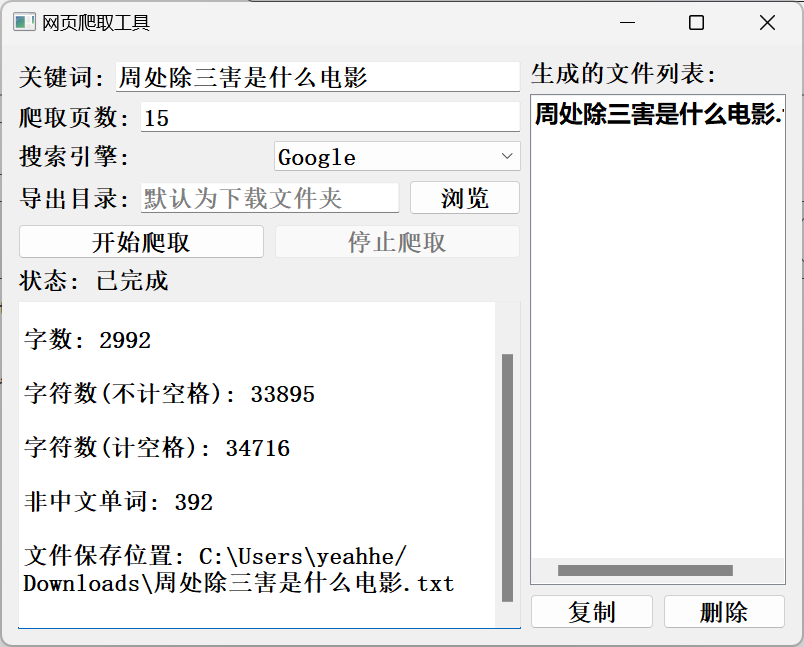
这是一个基于 Python PyQt5 开发的图形界面网页爬取工具。它能够从指定的搜索引擎(例如 Google、Bing、百度、搜狗、DuckDuckGo 等)抓取指定关键词的搜索结果,并提取网页中的文字内容、链接和按钮信息。工具支持多线程并发爬取,并提供友好的用户界面进行交互操作。
主要功能
关键词搜索: 用户可以输入关键词,并选择搜索引擎进行搜索。
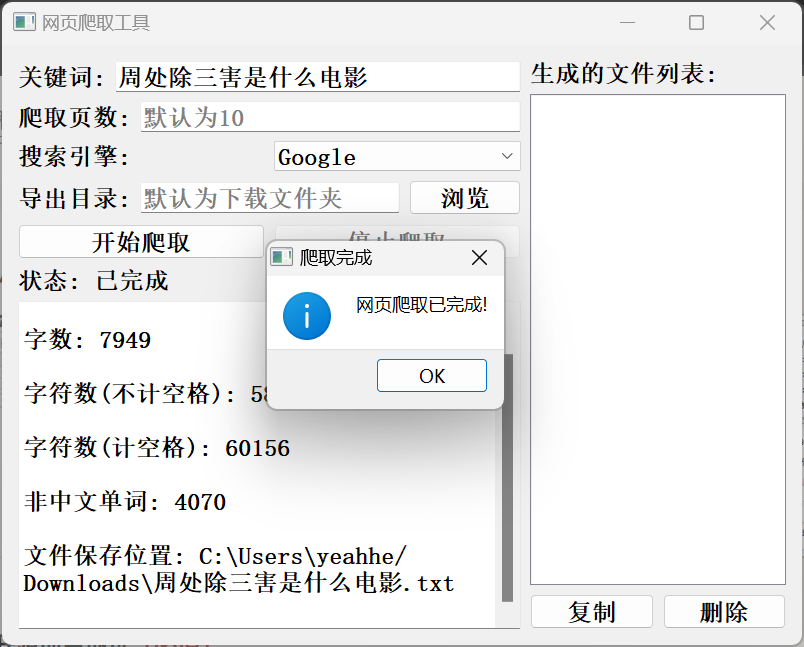
多页爬取: 支持设置爬取页数,并进行多线程并发爬取。
信息提取: 提取网页中的文字内容、链接和按钮信息。
结果导出: 将爬取到的信息导出到文本文件中,并自动复制到剪贴板。
文件管理: 用户可以查看生成的文件列表,并进行复制或删除操作。
状态显示: 实时显示爬取进度和状态信息。
技术栈
PyQt5: 用于构建图形界面。
requests: 用于发送 HTTP 请求并获取网页内容。
BeautifulSoup: 用于解析 HTML 页面。
concurrent.futures: 用于实现多线程并发爬取。
logging: 用于记录日志信息。
pyperclip: 用于复制内容到剪贴板。
我的角色
我作为开发者,负责了整个项目的架构设计、代码编写、测试和调试。我熟悉 PyQt5、网页爬虫技术和并发编程,并能够根据用户需求进行功能扩展和优化。
应用场景
该工具可以用于各种需要从网页上获取信息的场景,例如:
信息收集: 收集特定主题的新闻、文章、博客等信息。
数据分析: 爬取特定网站的数据进行分析和处理。
竞争情报: 收集竞争对手的信息,例如产品、价格、市场策略等。
未来展望
未来可以进一步扩展工具的功能,例如:
支持更多搜索引擎: 扩展支持更多的搜索引擎,例如 Yandex、Naver 等。
自定义提取规则: 允许用户自定义提取规则,以满足个性化需求。
数据可视化: 将爬取到的数据进行可视化展示,例如图表、词云等。
数据存储: 将爬取到的数据存储到数据库或云平台,方便后续分析和使用。
总结
这个网页爬取工具能够高效地从网页上获取信息,并提供友好的用户界面和丰富的功能。它可以帮助用户快速收集和分析数据,提高工作效率。
案例图片
相似案例推荐
其他人才的相似案例推荐
-

RMBG便携式自动抠图模型
超准抠图:RMBG通过其精细的分割技术,能够精确移除背景,即
-

佐糖
项目角色:前端工程师 主要功能: 1.在线抠图,通过人工
-

基于FPGA开发的压电台控制程序
### 1. 硬件设计 - **压电台**: 选择适合的压
-

设备控制及数据处理程序
1. 数据采集卡(DAQ)数据实时分析的GUI设计 基本
-

自动训练平台
只需小样本,就能高效完成现行业场景中各类视频、图 像、文本
-

悠言
元初app版,集 AI 聊天,AI 图画,AI 小说 ,和好
-

千灯环卫管理系统
这是个关于垃圾投放站点,中转站监控,环卫车监控跟踪的系统。帮
-

苏州市相城区一网通办
这是一个微信嵌入h5的小程序,主要是服务于广大人民各事项办件
-

法国Inria Alpha,Coq工具
Coq主要是用来辅助对程序定理进行证明的非常强大的工具,Al
-

法国Inria AlphaZ,
AlphaZ is an open source tool-
-

法国Inria Alpha,
AlphaZ is an open source tool-
-

法国Inria Alpha,
AlphaZ is an open source tool-
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

