
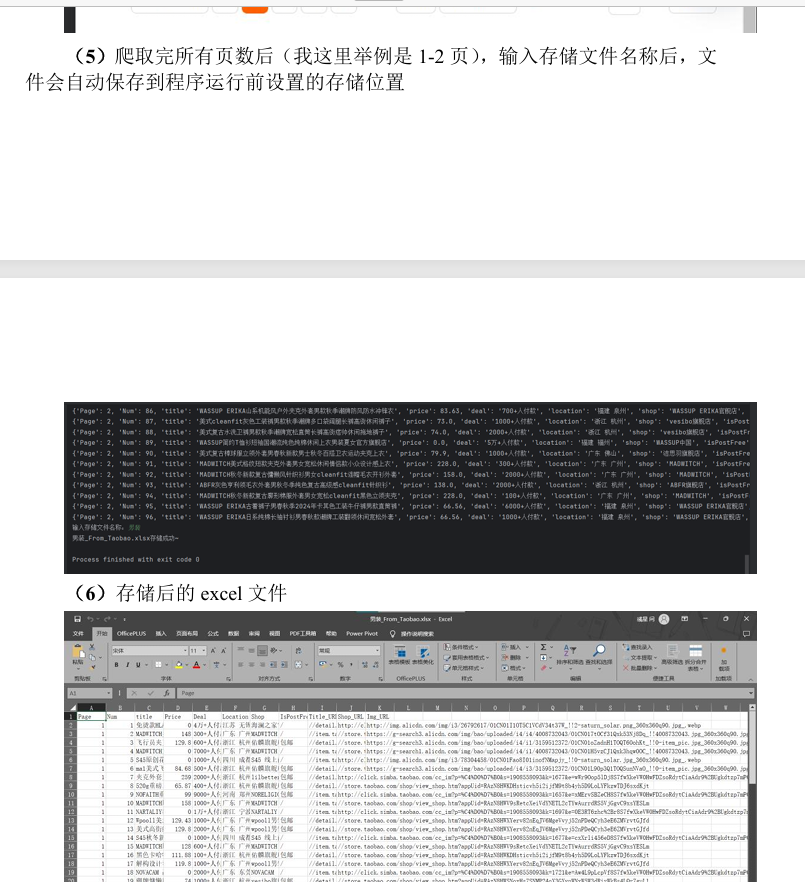
案例介绍
基于Selenium的淘宝网爬虫
该项目是一个自动化的网络爬虫,用于从淘宝网抓取商品信息,包括价格、销量、用户评价等关键数据。技术实现主要依赖于Python语言和Selenium库,模拟用户浏览器行为进行数据抓取。项目亮点包括:
高效的数据抓取:利用Selenium的WebDriver,实现了对JavaScript渲染页面的高效抓取。
反爬虫策略应对:通过代理IP池、动态更换User-Agent等技术手段,有效规避了淘宝的反爬虫机制。
数据清洗与分析:对抓取的数据进行清洗和分析,提取有价值的商业信息,为市场分析和决策提供支持。
分布式爬虫架构:设计了分布式爬虫架构,提高了数据抓取的效率和稳定性,同时降低了单点故障的风险。
案例图片

相似案例推荐
其他人才的相似案例推荐
-

售票微官网
演出售票微官网,可以定制化制作该页面的显示样式跟内容,可以提
-

云票务自营工具
万社云票务提供一站式云票务服务,客户无需开发和运维,可以像搭
-
")
舜和酒店管理(鸿蒙)
系统包含酒店预定、婚宴订房、美食团购、客人评价、会员等版块。
-

网络后台管理
个人职责:完成数据库表字段设计和索引构建,完成登录模块,注册
-

网络花店
项目名称:网络花店 开始时间:2022.10 项目技术栈
-

仓储wms管理系统
一个仓储管理系统,有后台和小程序两部分,后台vue框架,功能
-

商城网页
我最近完成了一个专注于电子设备销售的电商平台网页开发项目。这
-

独立站网页
我最近开发了一个宠物用品在线商城网页,专注于为宠物主人提供一
-

重百云购商城小程序
重百云购是重庆百货的线上商城电商小程序。我主要负责活动模块和
-

安逸花小程序
安逸花是马上消费金融公司推出的一款循环额度的信贷产品。应用内
-

teaShop
1. 搭建整体应用的框架,保证系统能够稳定运行,并且为其高扩
-

vue项目:网易云音乐Web
本项目采用Vue3框架,复写了网易云音乐的web网页,主要内
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

