
案例介绍
在本案例中,目标是使用Python语言中的pandas库、openpyxl库等来处理和整理导出的Excel表格数据。
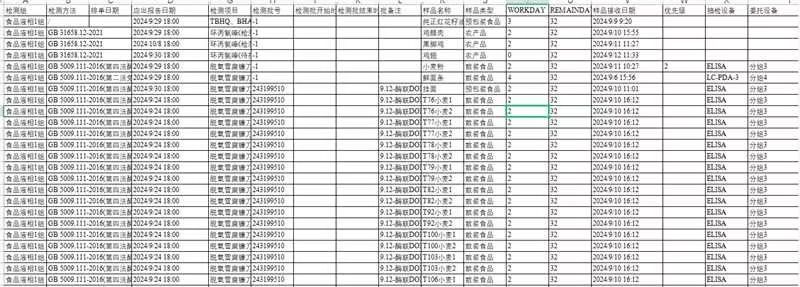
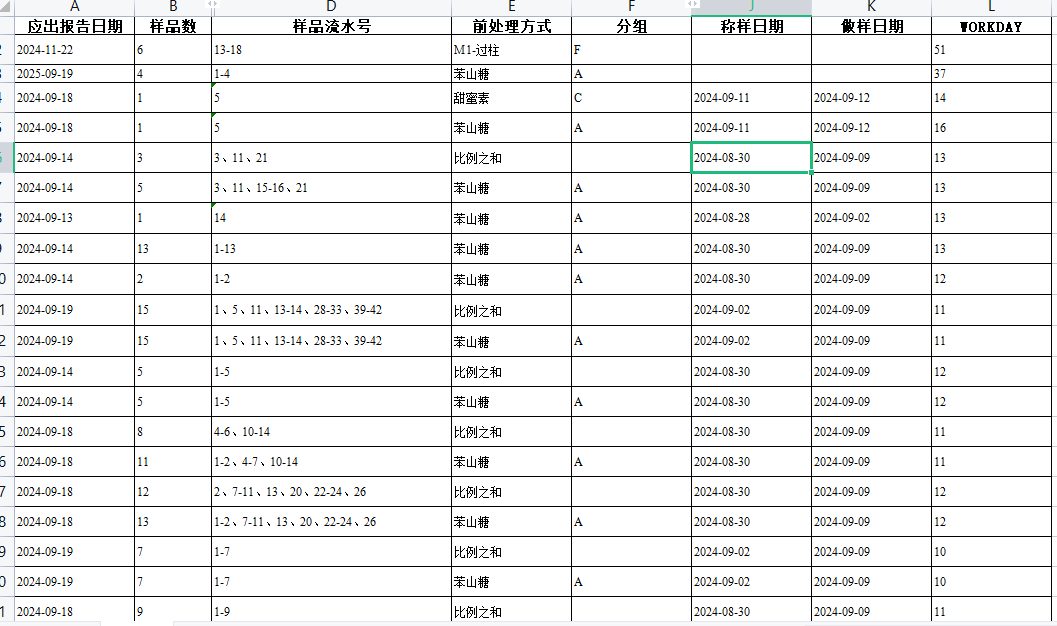
首先,我们需要使用pandas的read_excel函数来加载Excel文件。这个函数允许我们指定文件路径和工作表名称,以及需要读取的数据范围。接着,我们可以对数据进行预处理,比如清洗数据、转换数据类型、过滤不需要的行或列等。
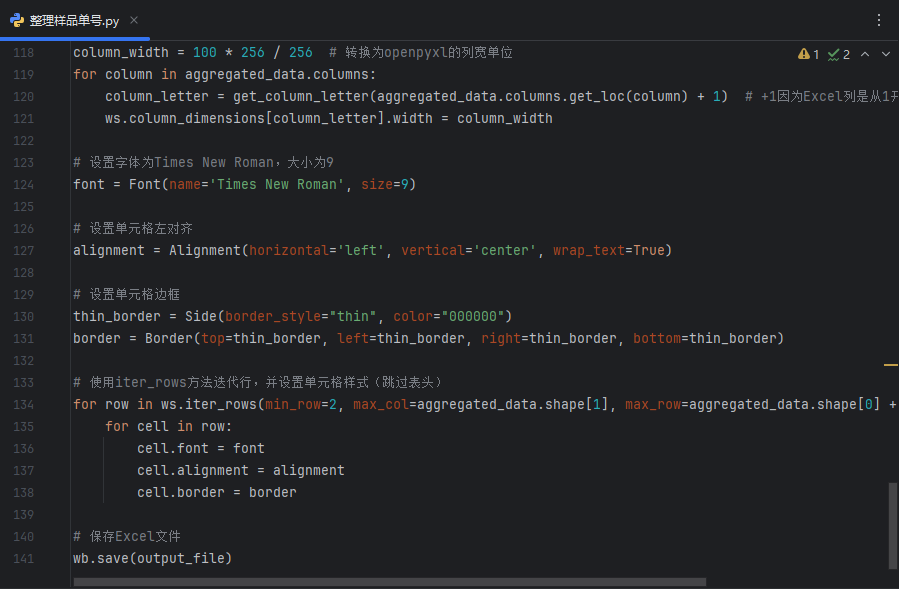
处理完数据后,我们可以使用pandas的to_excel函数将整理后的数据导出到新的Excel文件中。在这一步,我们可以利用openpyxl库来设置Excel文件的样式,比如设置单元格的字体、颜色、边框等,以满足客户的格式要求。
最后,我们将整理好的数据保存为一个新的Excel文件,确保所有的格式和数据都符合客户的要求。这个过程不仅提高了数据处理的效率,而且确保了数据的准确性和可读性,满足了客户对数据整理的特定需求。
案例图片

相似案例推荐
其他人才的相似案例推荐
-

人员客流密度统计系统
人员客流密度统计系统是地铁车站系统,该系统主要通过推理算法进
-

cjjtest
表结构设计 界面UI设计 与客户协商 主要功能实现
-

托娅低代码交付协助系统
该产品主要面向软件IT公司及软件行业开发人员。 跟现行市场
-

工程造价大数据平台
是一个提供工程造价相关服务的平台,主要功能包括品牌配置、材料
-

获取职位数据
详细功能:获取爱企查职位数据 负责的角色:敲代码的 应用
-

uniapp后台管理
运用uniapp搭建小程序,实现一套代码编译多端,使用了Un
-

数据管控平台
数据管控平台是新一代大数据平台建设中数据治理落地实施的有效方
-

在线客服系统TTalk
1. 负责TTalk在线客服系统的网关服务开发,包括实现We
-

GMA增长营销自动化平台
助力企业完成数字化转型,实现全终端触达和全场景运营。通过解放
-

脱贫攻坚项目
为了响应国家的号召,打赢脱贫攻坚战,安顺市紫云县政府开发了这
-

同步旺店通到用友财务的接口开发
同步网店通的采购单、销售单、商品、供应商信息到财务系统,使用
-

云协作文档系统
一个支持多人实时协作的在线文档系统,核心功能包括: 1
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

