桌面级自动朗读ocr系统

案例介绍
桌面级自动朗读OCR系统是一款集成了光学字符识别(OCR)和文本转语音(TTS)技术的桌面应用程序,旨在帮助视力受限用户或需要语音辅助的人士更便捷地获取和理解屏幕上的文字信息。该系统能够自动识别屏幕截图中的文字,并将其转换为语音输出,极大地提高了信息的可访问性。
在我的角色中,我担任了项目的主要开发者,负责整个系统的设计、开发和测试。我使用了Python语言进行开发,集成了百度OCR API来实现高精度的文字识别功能,以及pyttsx3库来实现文本到语音的转换。此外,我还利用了PIL库来处理图像,以及keyboard库来监听键盘事件,从而实现快捷键触发朗读的功能。
系统的主要功能包括:
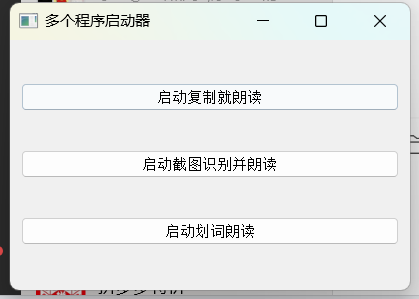
屏幕截图识别:用户可以通过快捷键或手动选择截图区域,系统将自动识别截图中的文字。
自动朗读:识别出的文字将通过TTS技术转换为语音输出,用户可以实时听到文字内容。
语音定制:用户可以根据个人喜好调整语音的语速、音调和音量。
多语言支持:系统支持多种语言的文字识别和语音输出,满足不同用户的需求。
键盘监听:系统能够监听键盘事件,用户可以通过特定按键快速触发朗读功能。
桌面级自动朗读OCR系统以其高效、易用和多功能的特点,受到了目标用户的广泛好评。通过这个项目,我不仅提升了自己的软件开发能力,也为推动信息无障碍做出了贡献。
案例图片
相似案例推荐
其他人才的相似案例推荐
-

pytest实现的自动化测试框架
该程序时使用pytest和allure,实现的接口自动化框架
-

Excel编辑与生成软件
python相关 1.可以进行各种数据的统计,整理,编辑等
-

XXX取证软件
使用C/C++ 语言进行开发,软件具备多种功能,包括文件系统
-

逆向分析二次开发
对未提供源代码的动态链接库进行深入分析,以识别其接口。通过反
-

企业办公软件
作为外包提供商,为企业提供从原型设计、UI设计、交互设计、前
-

跨境电商ERP
跨境ERP系统开发 项目简介: 我负责设计并实现了一个本
-

智慧水务综合管理平台
负责web前端开发和ui设计,主要参与项目设计功能确立,资料
-

某厂内部管理平台
负责web前端开发和ui设计,主要参与项目设计功能确立,资料
-

佳会
负责app的整体开发以及上架 主要设计功能登陆 音视频会
-
")
综合性虚拟按键模拟(类按键精灵项目)
1.功能: ①:驱动级按键模拟点击。 ②:图像识别(配合
-

多媒体操控台软件
1.功能: ①媒体播放:可接收拖拽播放多种格式的图片、视频
-

IM办公协同平台
安卓,IOS,WEB,PC多端互通的办公协同平台,基于实时通
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

接收人才推送

联系需求方端客服