
案例介绍
作品介绍:
OpenAI图像生成器前端应用是一个基于OpenAI的图像生成技术的前端展示工具。它允许用户通过简单的文本输入,生成与之匹配的创意图片,为创作者、设计师乃至普通用户提供了全新的创意空间和视觉体验。
1. 技术背景与原理:
该应用利用OpenAI强大的API,特别是结合DALL-E或后续模型,构建一个能够根据用户输入文本生成创意图片的工具。用户只需在前端界面输入一段描述性的文字,后端将通过OpenAI的API接口,调用图像生成模型,并返回生成的图片URL。前端再展示该图片,从而完成整个图像生成流程。
2. 界面设计与交互:
简洁明了的界面:应用界面采用简洁明了的设计风格,避免过多的干扰元素,确保用户能够专注于文本输入和图片生成。
直观的交互体验:用户可以通过输入框输入描述性文字,点击“生成图片”按钮后,界面将显示生成的图片。同时,应用还提供图片预览、下载等功能,方便用户进一步操作。
友好的错误处理:在请求失败或图片生成失败的情况下,应用将提供友好的错误提示,并引导用户重新输入或尝试其他描述。
3. 功能模块:
文本输入模块:允许用户输入描述性文字,为图片生成提供素材。
图片生成模块:通过调用OpenAI的API接口,根据用户输入的文本生成图片。
图片展示模块:展示生成的图片,并提供预览、下载等功能。
用户反馈模块:收集用户对生成的图片的评价和反馈,以便不断优化和改进应用。
4. 技术实现:
前端框架:采用React或Vue等前端框架进行开发,确保界面响应迅速且易于维护。
API接口调用:通过Fetch API或Axios等工具,调用OpenAI的API接口,实现图片生成功能。
状态管理:使用Redux或Vuex等状态管理工具,确保应用状态的一致性和可预测性。
错误处理:采用try-catch语句和错误边界组件等技术,实现友好的错误处理和用户引导。
5. 应用价值:
该应用不仅为用户提供了全新的创意空间和视觉体验,还为创作者、设计师等提供了便捷的图片生成工具。同时,它也展示了OpenAI图像生成技术的强大潜力和广泛应用前景。未来,随着技术的不断进步和应用的不断完善,该应用有望在广告、海报、封面等创意内容生成领域发挥更大的作用。
案例图片
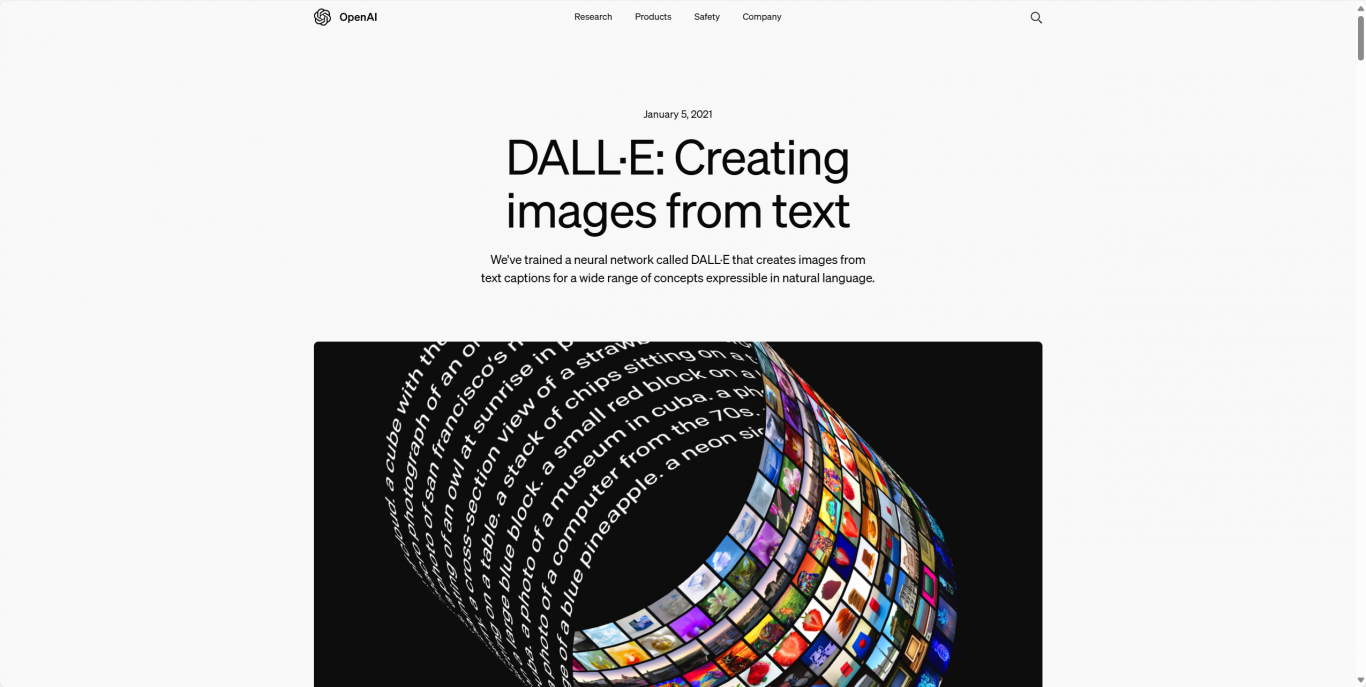
相似案例推荐
其他人才的相似案例推荐
-

骆宝宝
微信小程序“骆宝宝”、相关智能硬件服务器、后台管理系统、数据
-

车联网平台
此项目主要是给工程车提供硬件,版本升级,设备定位、添加、事件
-

对讲机
该项目完成的内容: 1、自主读懂原理图与电路图 2、手动
-

通信终端开发
FreeRTOS/UCOS III/BareMetal开发
-

上位机视觉开发
C#上位机应用开发是指在工业生产中,通过计算机软件实现对生产
-

Agv小车
项目描述:本次项目主要是基于ESP32芯片为基础来对小车进行
-

智途客服、云鹏水泥crm
1.工厂项目:产品出入库,小程序订单、web端订单,采用开源
-

防爆终端
此方案是一款应用在危险巡检领域的智能终端设备,具备防尘防溅水
-

扫描仪
扫描仪项目主要在华高扫描仪机器的基础上进行开发,APP的设计
-

智能自动售卖机
通过后台程序对售卖设备进行补货配货,修改价格,打折等配货信息
-

汽车诊断OBD座舱域控系统VMS
项目描述:负责车机应用架构设计和开发,输出新产品方案,负责汽
-

企业办公网络调优
项目名称:腾讯NDC场地网络维护 项目职责:负责整个场地
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

