
案例介绍
1.创建项目
2.新建任务
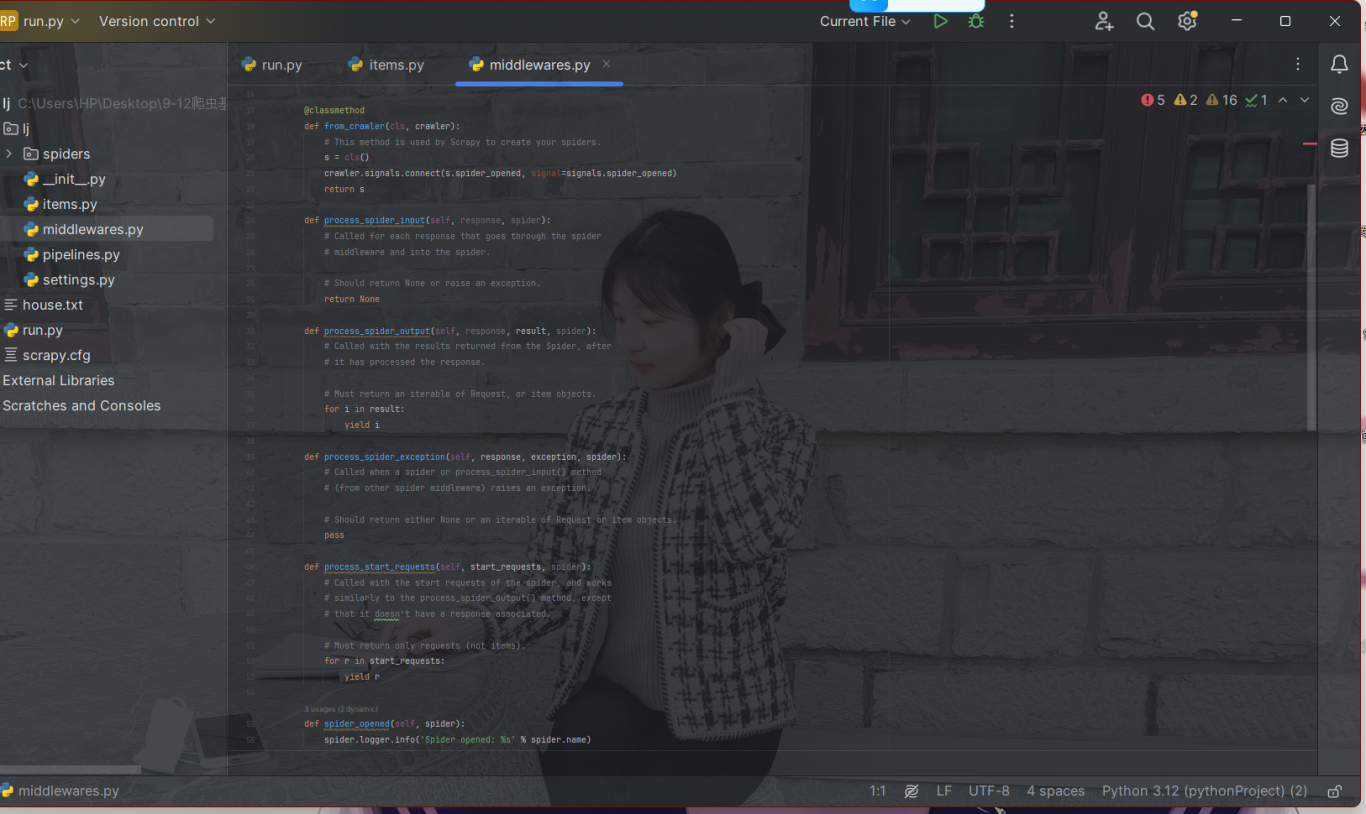
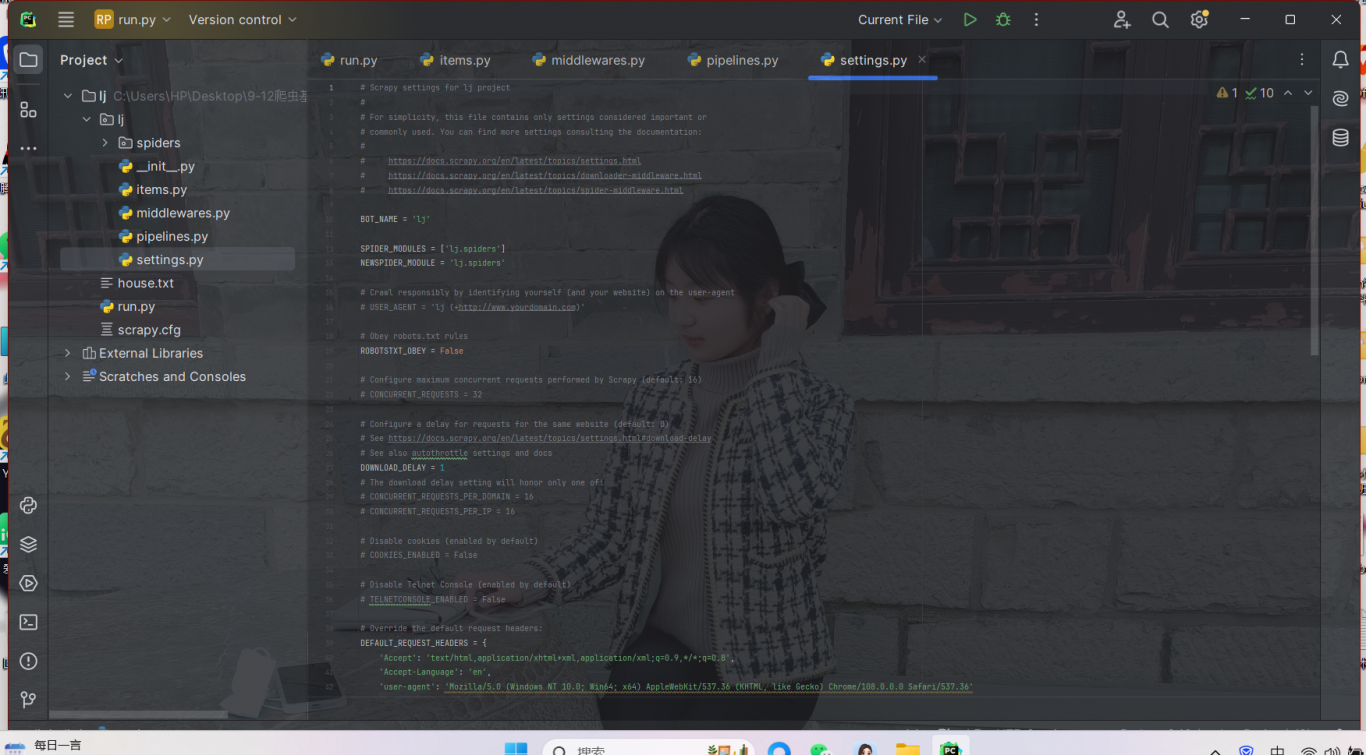
3.修改配置文件 [setting.py]
只需要用到4个配置数据 [1.UA伪装 2.robot协议 3.并发数量 4.管道保存]
# UA
# 爬虫君子协议
# 开启并发,多任务爬取
# 管道保存,自定义保存方
4.设置爬取内容 [items.py]
# category:类别 subcategory:子类 article:文
5.编写爬虫
# 在主页里获取到大类/小类的标题/链接
# 大类
()
# 小类)
# 创建文件夹 --> 遍历大类/小类
# 下一步获取小类主页里的数据
# 接着调用另一个函数[sub_parse] meta参数为传参,把item数据交给函数继续使用
# 解析小类页面里的内容 [提取主页里的文章信息.]
# 偷懒办法.先获取所有a标签.再筛选
urls = res.xpath('//a/@href').getall()
# 筛选条件 1.后缀为.shtml 2.是否为新浪网站,第三方不爬取 [是否携带了大类别的网址]
# 满足条件的数据就放入到文章链接里. 并调用文章解析函数.
# 解析文章内容 [标题/网址/内容
# 提取文章标题
# 提取文章内容 不同的文章主页class/id不一样
# 使用xpath的or语句.识别多种情况 contains判断值是否为XX
# 有的网站文章正文用的id叫article 有的网站正文用的是class叫artibody
# 把文章标题/内容添加到item里
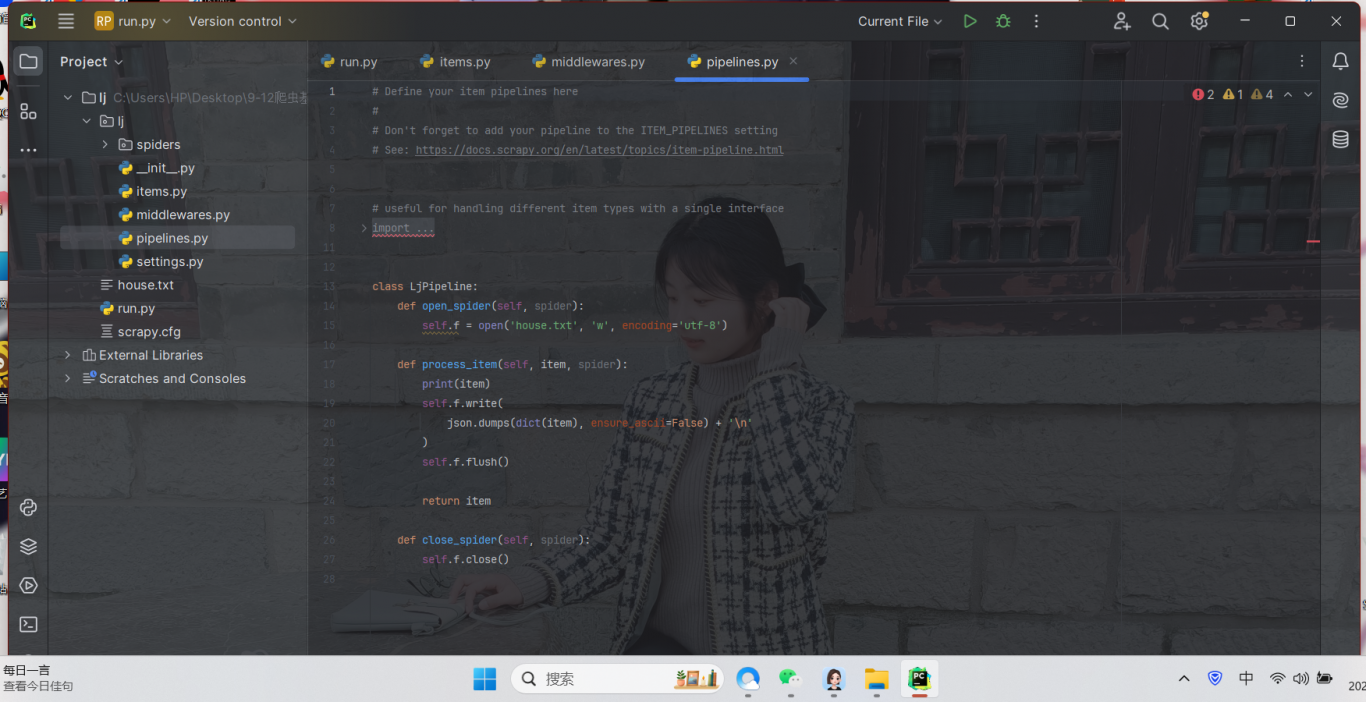
6.编写项目管道
案例图片
相似案例推荐
其他人才的相似案例推荐
-

自动大屏开发
活动大屏:年刊活动的数据(物流 、书刊库存 、客户)支持;6
-

积分制培训实施系统
项目名称:积分制培训实施系统 项目时间:2022年6月
-

移动学习系统
项目名称:移动学习系统 项目时间:2021年6月至20
-

建远学堂
建远学堂是一个多品种类别的职业技能提升站点,兼顾到多方面的职
-

个人主页
制作的个人主页 浏览器里直接使用方便高效 便捷 稳定 代码量
-

spug二次开发
批量执行: 主机命令在线批量执行 在线终端: 主机支持浏览
-

在线考试系统
学生系统功能 模块 介绍 登录 用户名、密码 注册 年
-

isc学院
60的ISC学院项目是一个专注于数字安全教育的综合服务平台,
-

isc学院
360的ISC学院项目是一个专注于数字安全教育的综合服务平台
-

开课
开课,使用的在线实践教学服务平台与创新环境,为高校和企业的实
-

江苏西医住培
江苏西医是为江苏省住院医师规范化培训所设计的医疗服务APP。
-

视频课程管理系统
该项目是一个视频课程管理系统,用户端为一个app,实现了用户
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

