
案例介绍
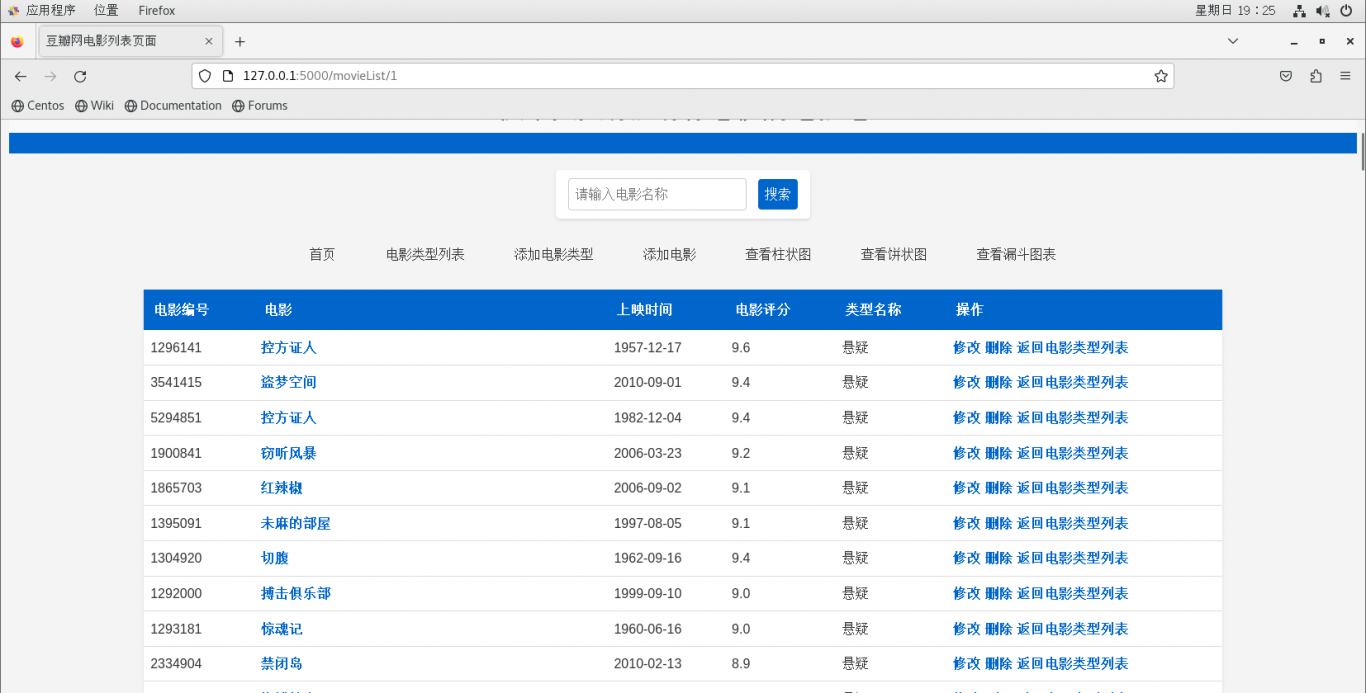
开发一个完整的小说数据平台,涵盖数据抓取、清洗、存储与Web展示的全流程。项目中使用Requests库从多个小说网站抓取数据,包括小说名称、作者、章节内容等,并通过自定义的爬虫策略应对网站反爬机制。抓取的数据经过Pandas进行清洗和格式化处理,确保内容的完整性与一致性。处理后的数据通过PyMySQL存储到MySQL数据库中,确保高效的数据查询和管理。
在平台后端,使用Flask框架构建API接口,实现数据的动态请求与交互,确保前后端分离的设计。前端则通过HTML、CSS以及部分JavaScript实现小说内容的展示,包括搜索、分类浏览和分页功能,确保用户体验流畅。此外,平台还支持数据的增删改查,结合API实现前端的实时更新,构建了一个高效、可扩展的小说数据管理平台。
案例图片

相似案例推荐
其他人才的相似案例推荐
-

信锐icare项目
1、该项目对销售订单进行项目售后服务和跟进 2、该项目对售
-

渠道业务导入
该项目整合了渠道的数据,从历史成交客户信息,渠道中标客户信息
-

通信服务工具
通信服务工具:基于bhf协议、物联网协议等,将数据进行编解码
-

cms系统
jeecgjeecgjeecgjeecgjeecgjeecg
-

cms系统
111111111111111111111111111111
-

爬虫工程师
从电商网站抓取商品价格和评价信息,为企业制定营销策略提供数据
-

查控平台
结合数据仓库,按照各类要求如监管要求给出特定数据,筛选、优化
-

辖区大师
本人在项目中主要负责设计/进行技术沟通/前后端开发/数据库设
-

项目详情管理系统
此项目是我本人全程从设计到开发上线完成的 ⚫ 涉及技术:V
-

“炭指南”小程序
此小程序已上线 ⚫ 涉及技术: UniApp + uVie
-

企业saas服务
参与低代码平台的核心功能开发,使用框架和工具实现业务逻辑。
-

数据查询CRUD
本程序是独立开发写的单机查询,数据库采用sqlite..使用
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

