
案例介绍
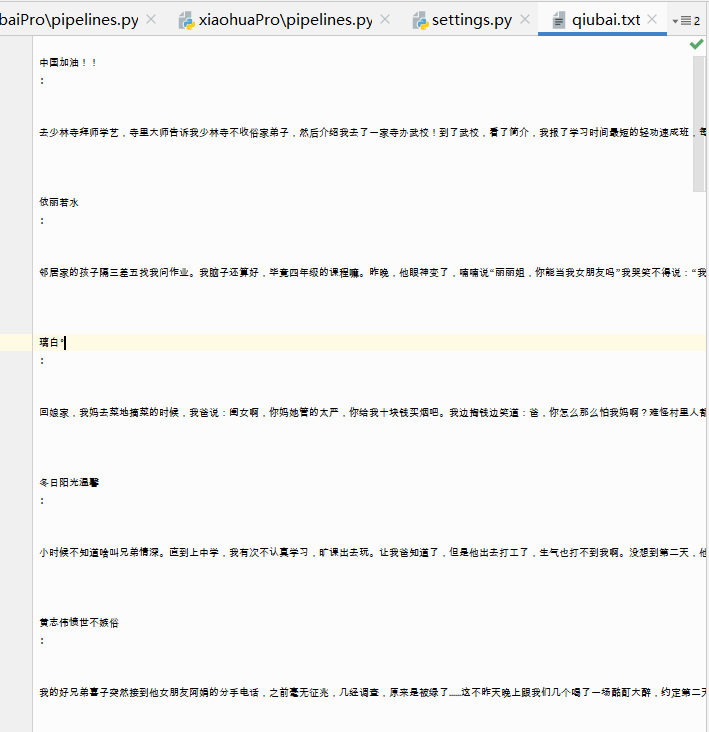
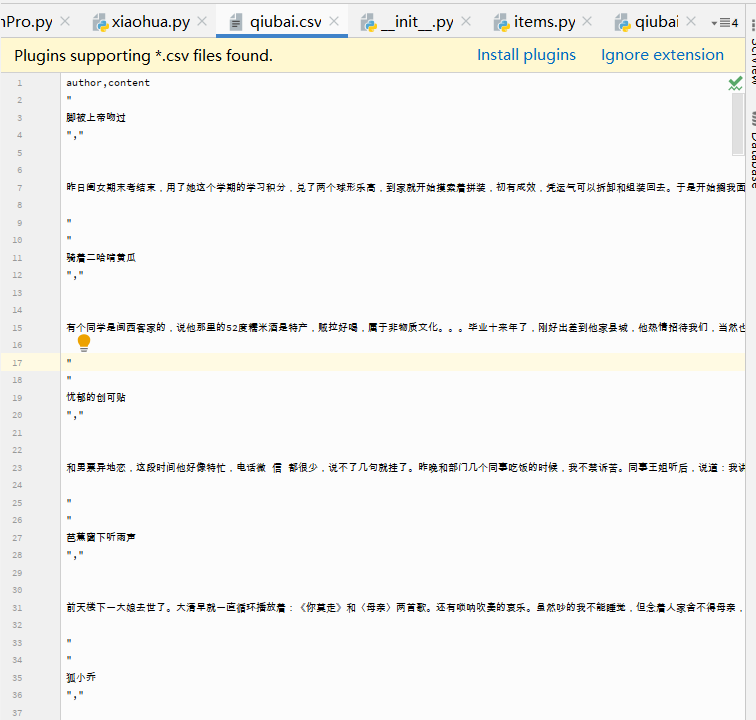
本实验应用scrapy框架和xpath爬取糗事百科的作者及内容,并将其存储到csv文件及txt文件中。
原理:
(1)scrapy概述:
框架是一个集成了很多功能并且具有很强通用性的一个项目模版。Scrapy框架是爬虫中封装好的一个框架。Scrapy的功能:高性能的持久化存储,异步的数据下载,高性能的数据解析。
(2)scrapy框架的基本使用:
windows环境的安装:
①pip install wheel
②下载twisted
③安装twisted
④pip install pywin32
⑤pip install scrapy
构建工程
①创建糗事百科工程:scrapy startproject qiubaiPro
②进入到工程目录,在spider子目录中创建爬虫文件
scrapy genspider qiubai https://www.qiushibaike.com/text/
③执行工程 scrapy crawl qiubai
案例图片
相似案例推荐
其他人才的相似案例推荐
-

建站系统
本方案面向广大企业和相关单位机构,提供企业网站建设等信息化基
-

go语言爬虫
GO爬虫,目前纯命令行版,可与scrapy等框架的pytho
-

PLM 项目集成 ES 搜索引擎
项目名称:舜宇光学科技(集团)PLM 项目集成 ES 搜索引
-

电商分销平台
订单系统 企业级订单系统,支持多维度查单、生产、结算、分析,
-

JDE系统的基于房地产的工单录入
本次开发是基于JDE系统提供的平台进行开发,满足用户将分散于
-

JDE系统的基于房地产的工单录入
本次开发是基于Oracle JDE提供的自带的开发平台,对J
-

爬取数据
我们选择网站作为数据来源,目标是获取该网站上的古诗数据,包括
-

爬取数据
我们选择简历网站作为数据来源,目标是获取该网站上的古诗数据,
-

python数据抓取
每日产生大量快递面单,抽取每天面单数据,存储到excel文件
-

手机取证产品功能
1、实现手机电子数据信息通过无线、USB等方式提取并解析手机
-

计算机数据快取并解析
1、实现通过镜像方式对计算机数据进行快速备份到硬件设备功能
-

后台管理系统
该项目为通用后台管理设计,主要负责进行商家管理(账号管理、子
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

