
案例介绍
多模态数据检索技术针对检索结果属于不同媒体类型的场景,当用户对一种
模态的查询词进行检索时,它能返回与之匹配的其他模态的检索结果。这种技术
能够有效地提高平台多模态数据的利用率,提升用户的使用体验。为此,本文采
用了视觉语义嵌入(VSE)模型来进行图像文本检索,并通过自适应优化目标和
损失函数对其进行优化。
图像预处理方面:本文首先采用随机裁剪进行数据增强,通过双线性插值方
式将裁剪后的图像缩放到目标尺寸,将缩放后的图像进行随机水平翻转、随机颜
色调整,增加图像的多样性。文本预处理方面,首先针对文本中包含的 HTML
标签、特殊字符、URL 等进行数据清洗,接着剔除掉对文意贡献较小的停用词,
最后通过分词得到文本的关键信息。
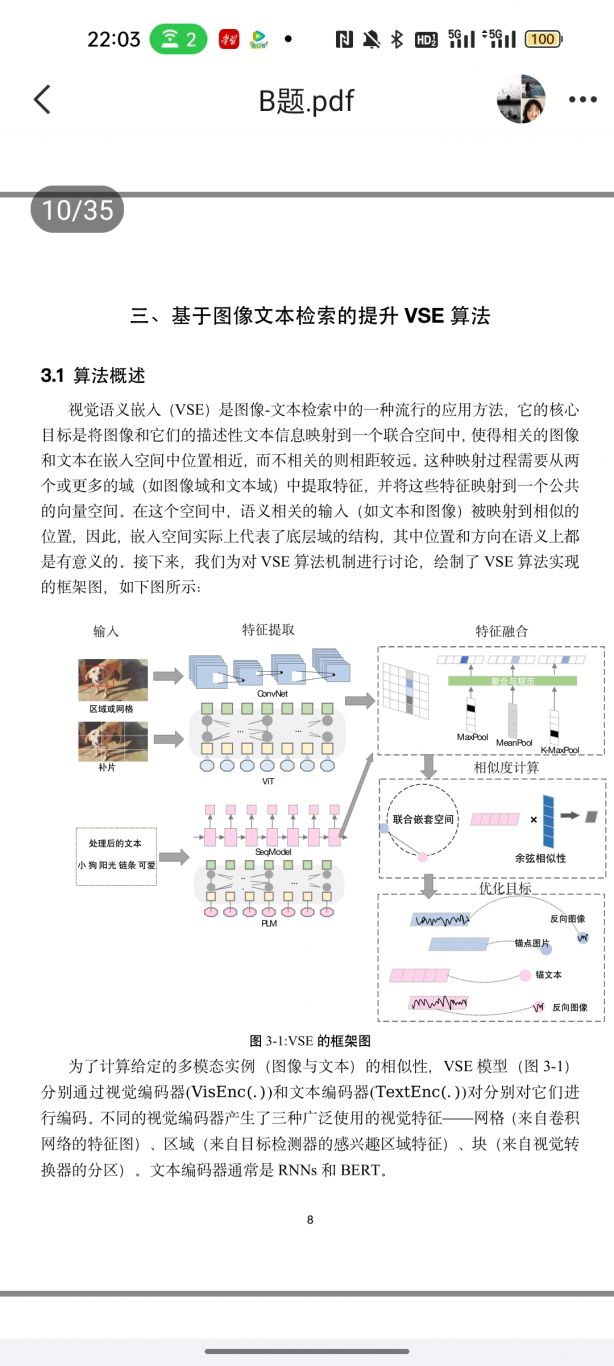
模型训练方面:我们结合了 ResNet50 和 ViT 两种网络结构,分别提取图像
的局部和全局特征。为了充分利用图像和文本的全局和局部信息,我们采用了
Token-level 和 Embedding-level 两种池化策略,并将这两种池化后的特征向量进
行融合。模型采用了余弦相似度作为相似度度量方式,能够更好地处理图像文本
之间的语义关系。此外通过自适应优化目标(ADOPT)方法能够根据当前模型
的训练状态动态调整负样本的数量,从而提高训练效率和收敛速度。将训练好的
模型对附件 2 和附件 3 样本进行测试,结果表明优化后的 VSE 模型检索出相关
性最高的十个图像(文本)与待检索的文本(图像)的内容具有很强的匹配度。
计算出文本检索和图像检索测试集 R@5 结果为 55.48%和 54.97%;R@10 的结
果为 62.9%和 62.67%。从对错误检索样本的分析中可以发现模型的检索结果与
待检索对象有很强的匹配度。但是由于图像(文本)与之相匹配的信息有很多,
表意不唯一。且加上待匹配的样本数量大,符合信息的样本多,因此可能无法检
索到唯一的匹配样本。
文末对模型的优缺点进行总结,本文采用的提升 VSE 算法有一定的准确性
和现实意义,可以作为图像文本检索的有效模型。同时展望了未来的研究方向,
包括如何提高模型的泛化能力、如何结合更多的监督信号来优化模型以及如何将
本文提出的模型和方法应用到更多的跨模态任务中。
案例图片



相似案例推荐
其他人才的相似案例推荐
-

和生活爱辽宁
服务于辽宁移动,是一个中国移动的网上营业厅主要分为5个模块
-

碳资产集中管控平台
碳资产集中管控平台主要围绕排放核算、甲烷监测、履约交易、碳绩
-

大港油田安眼可视化大屏
大港油田安眼可视化大屏集齐了综合展示、生产监管、作业监管、视
-

自动化运维平台
自动化运维平台通过丰富的运维脚本库和灵活的作业编排能力,将日
-

python爬虫python数据爬取
项目作品: 【房地产市场洞察】- 开发自动化房价爬虫,
-

python爬虫python望月数据爬取
项目作品: 【房地产市场洞察】- 开发自动化房价爬虫,
-

TCP卸载内核模块
我曾在Linux内核项目中,负责设计并实现了TCP卸载引擎的
-

中央空间报价软件管理系统
PHP开发的一个支持电脑和手机同步展示中央空调报价管理系统;
-

OA系统
项目概述:该项目是给第三方做的一个OA系统,主要用来管理公司
-

前端开发
数据分析呈现方面的后台管理系统,实现数据交互 权限管理 大图
-

彼岸图片网
彼岸图片的抓取结果,其中利用到异步协程库asyncio和异步
-

scrapy采集去哪儿旅游攻略
利用scrapy框架抓取去哪儿旅游攻略,其中设计scrapy
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

