
案例介绍
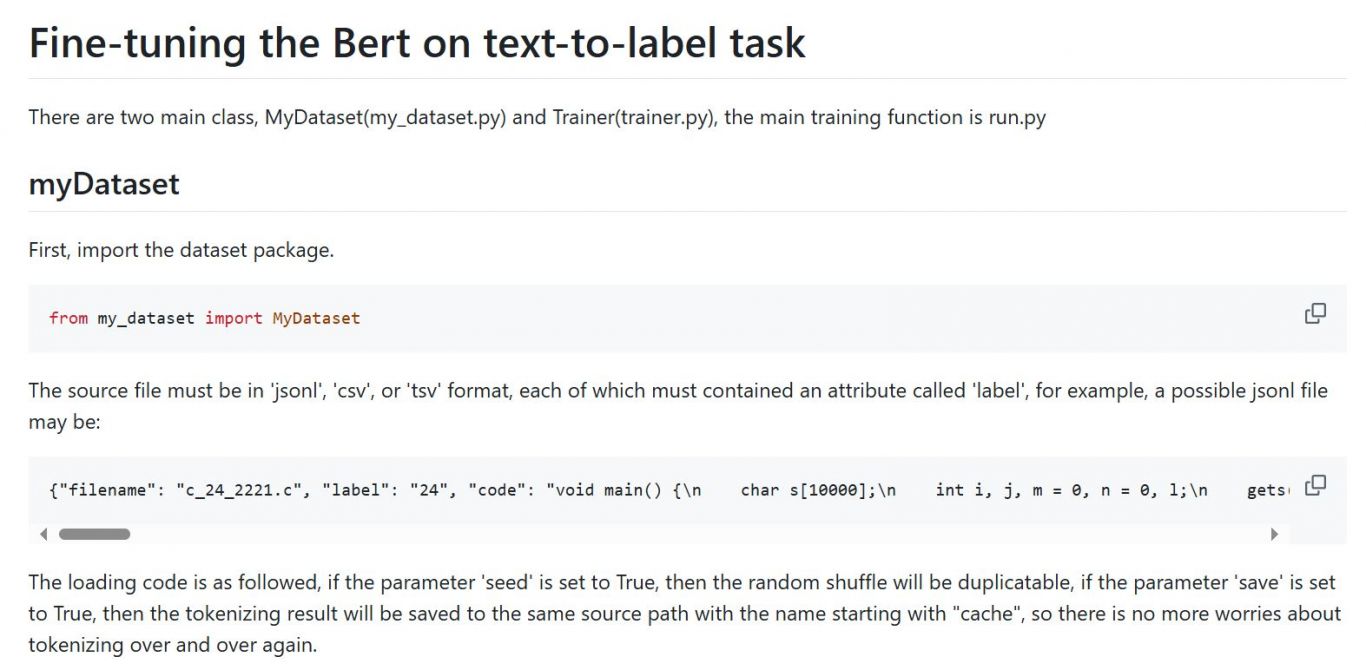
在微调BERT模型进行文本到标签的任务中,主要涉及两个类,`MyDataset`(位于my_dataset.py)和`Trainer`(位于trainer.py),主要的训练函数在run.py文件中。
数据源文件必须为'jsonl'、'csv'或'tsv'格式,每种格式的文件都必须包含一个名为'label'的属性。
加载代码如下,如果设置参数'seed'为True,则随机打乱将可复制;如果设置参数'save'为True,则token化结果将保存到与源路径相同的位置,文件名以"cache"开头,因此不必担心需要重复进行token化
加载源文件后,运行tokenize方法,输入tokenize的模型名称、选择要tokenize的属性和最大长度
最后,通过调用to_dataloader方法将数据集转换为Dataloader,提供批量大小和是否打乱的选项,通常训练时shuffle=True,评估和测试时shuffle=False
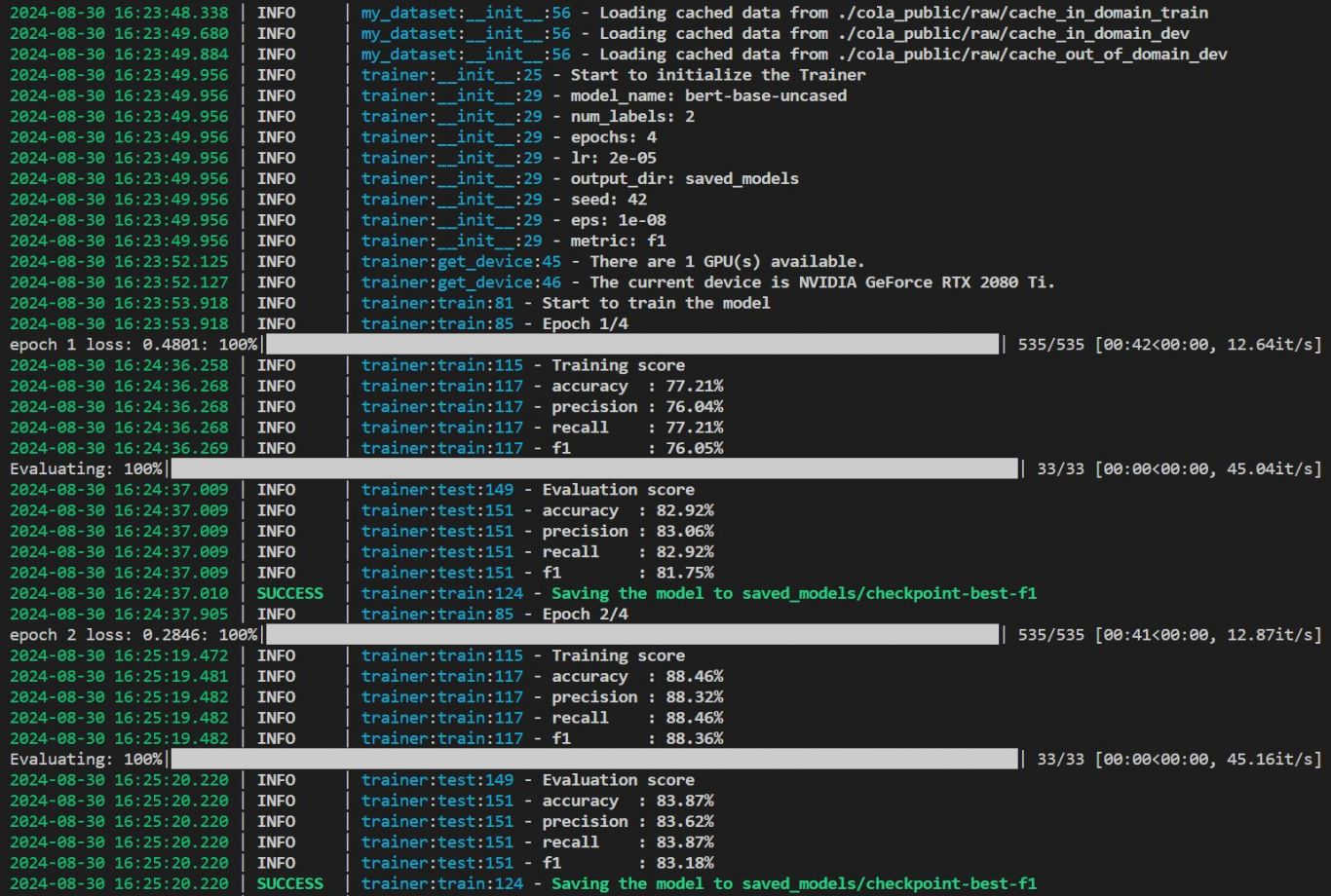
为了简化训练过程,构建了一个`Trainer`类
然后训练模型,输入train_dataloader,如果提供eval_dataloader,每个epoch将在eval_dataloader中进行测试
训练结束后,它将把最佳度量分数保存到output_dir.
案例图片
相似案例推荐
其他人才的相似案例推荐
-

自动化设备下单小程序
作品名称:自动化设备订单传输小程序 开发工具:微信开发
-

驾驶人模拟理论考试系统
delphi、asp.net C# 开发,多个版本。数据库分
-

一休校园生活
围绕“教、学、研、管、服、评”等校园全场景、全流程,结合自研
-

菁彩校园
围绕“教、学、研、管、服、评”等校园全场景、全流程,结合自研
-

学堂在线
项目描述: 周末大课堂小程序是一个在线教育平台,提供免费和
-

公司官网
普通官网引流, 后端渲染seo,sitemap网站地图,
-

模具
大型零部件加工图。本人最擅长的是模具编程及出电极。熟练应用3
-

IC Design 商业网站
项目简介:ICDesign是一个以线上教育为主的商业网站,主
-

东莞市高训综合服务管理平台
负责项目主要开发人员,包含分基地业务、职业技能等级认定、在线
-

综合服务管理平台
微信小程序/支付宝小程序开发,主要有预约报名、预约查询、成绩
-
")
每阿教育(web)
项目描述: 美啊教育网站是一个在线学习平台,通过其平台,为
-

综合创业服务平台APP
集信息流资讯、线上教育培训、创业服务三大业务为一体的APP。
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

