
案例介绍
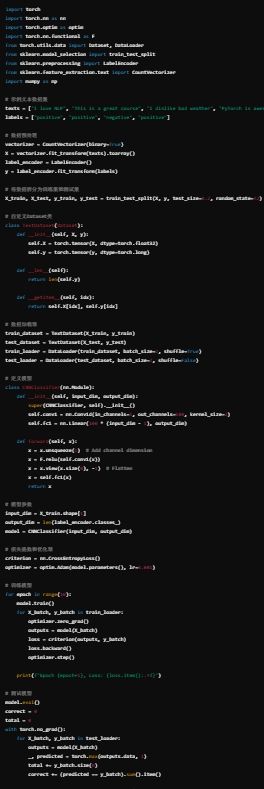
代码解释:
文本数据预处理:
使用 CountVectorizer 将文本转换为特征向量(Bag of Words表示)。
使用 LabelEncoder 将标签转换为数值。
Dataset 和 DataLoader:
定义了 TextDataset 类来处理数据加载,将数据转换为 PyTorch tensor。
使用 DataLoader 来迭代训练集和测试集。
CNN 模型:
定义了一个简单的 CNN 模型,包括一个1D卷积层和一个全连接层。
Conv1d 是 PyTorch 中的1D卷积层,适合处理文本序列。
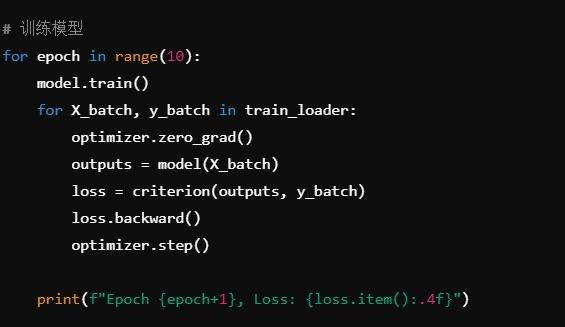
训练:
使用交叉熵损失函数和 Adam 优化器来训练模型。
训练10个 epoch,并打印每个 epoch 的损失。
测试:
在测试集上评估模型的准确性。
案例图片
相似案例推荐
其他人才的相似案例推荐
-

影像文字识别
影像文字识别是把银行进出口单、海关单、原交易对话单、税收凭证
-

向量知识库
向量数据库是专为处理高维数据和执行相似性搜索而设计的数据库系
-

Golang错误日志
根据团队平时开发习惯,为了标准化日志输出规范,使用Golan
-

Golang错误日志
根据团队平时开发习惯,为了标准化日志输出规范,使用Golan
-

python代码混淆
为防止打包过的代码被他人逆向破解,反编译,结合学习到的技术以
-

未来智停e
1.针对汽车路边停车 ,共享停车 ,路边停车对接使用地磁感应
-

永锋钢铁厂远程智能计量系统
我主要负责的模块是远程智能计量系统的全部模块的测试任务分配和
-

视觉检测系统
一款视觉检测系统的设计开发维护,主要负责视觉检测业务,上下位
-

智能好停车saas平台
系统中整合了项目中的所有硬件,并提供了一站式的智慧停车综合管
-

公安内部大数据分析系统
公安大数据系统包含了业务支撑,领导决策,个人案情研判,数据资
-

工作流agent
负责AI相关的部分,与接口开发对接,完成agent的流程编排
-

RAG智能客服
通过对原始套餐文档的结构化提取后,存入图数据库(neo4j)
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

