
案例介绍
项目介绍:微博内容爬取项目
项目背景
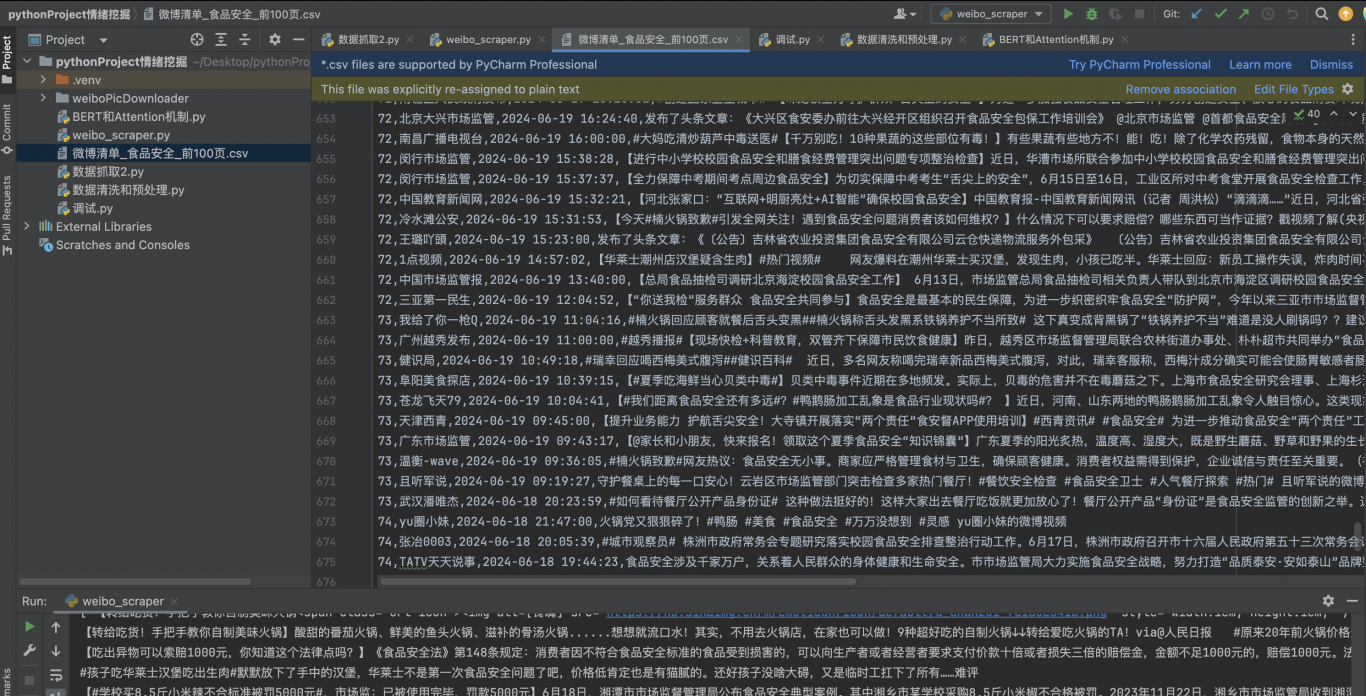
本项目旨在从新浪微博平台抓取指定关键字的微博内容,整理并保存为结构化的数据文件(CSV格式),以便进行后续的数据分析和处理。微博作为中国最大的社交媒体平台之一,包含大量用户生成的文本内容,对情绪挖掘、舆情分析等研究具有重要意义。
项目功能
1. 关键字搜索:用户可以输入任意关键词,程序将基于该关键词在微博平台上进行搜索。
2. 多页抓取:用户可以指定需要抓取的页数,程序会自动抓取指定页数内的微博内容。
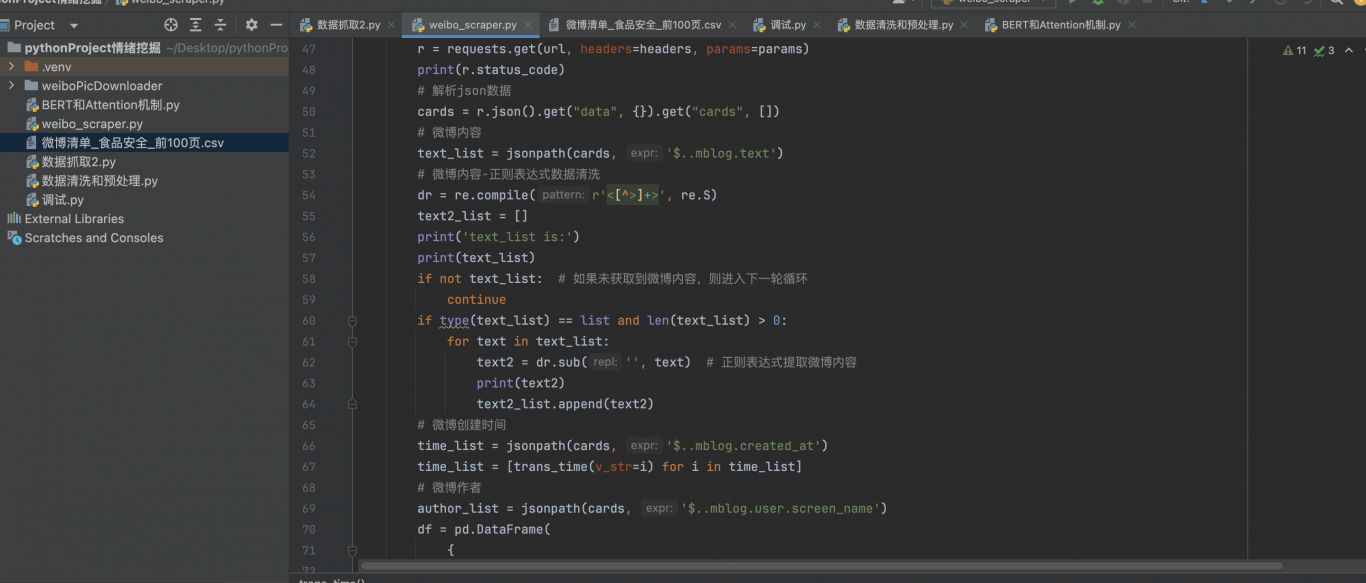
3. 数据清洗:程序会自动清洗抓取到的微博内容,去除HTML标签等冗余信息。
4. 数据存储:所有抓取到的微博内容会以CSV文件格式进行存储,方便后续的分析与处理。
技术栈
• 编程语言:Python
• 第三方库:requests(HTTP请求)、pandas(数据处理)、fake_useragent(生成随机User-Agent)、jsonpath(解析JSON数据)、urllib3(HTTP库)
• 数据格式:CSV(Comma-Separated Values)
案例图片
相似案例推荐
其他人才的相似案例推荐
-

音约app
以音乐为钥匙,打开社交大门。音约的灵感来自音乐节现场以共同的
-

创业人格测试
项目背景:帮助调研参与者的创业者指数 技术: vue +
-

火聚
火聚APP是一款趣味生活类产品,在这里,每天更新着海量的特色
-

篮球社区
作品描述:本项目为个人设计与开发,旨在设计并实现一个专注于篮
-

萌派视界
系统架构设计,协助产品上架应用商店。 1.完成短视频模
-

志愿时系统
一、志愿者人员管理 志愿时系统提供了一套完善的志愿者人员管
-

社交聊天APP直播语音交友界面设计
社交聊天APP开发定制直播语音交友在线论坛同城相亲小程序软件
-

你问我答
1、消息界面 如图能看到界面上的功能,进入到对应的功能界面
-

你问我答
1、消息界面 如图能看到界面上的功能,进入到对应的功能界面
-

生日祝福互动
设计一场前端生日祝福互动,我们将充分利用HTML5、CSS和
-

我的博客
我的简历我的简历我的简历我的简历我的简历我的简历我的简历我的
-

人格MBTI测评
通过uniapp实现抖音小程序,对接三方题库进行问答收集 最
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

