
案例介绍
项目介绍:小红书数据爬虫
项目简介:
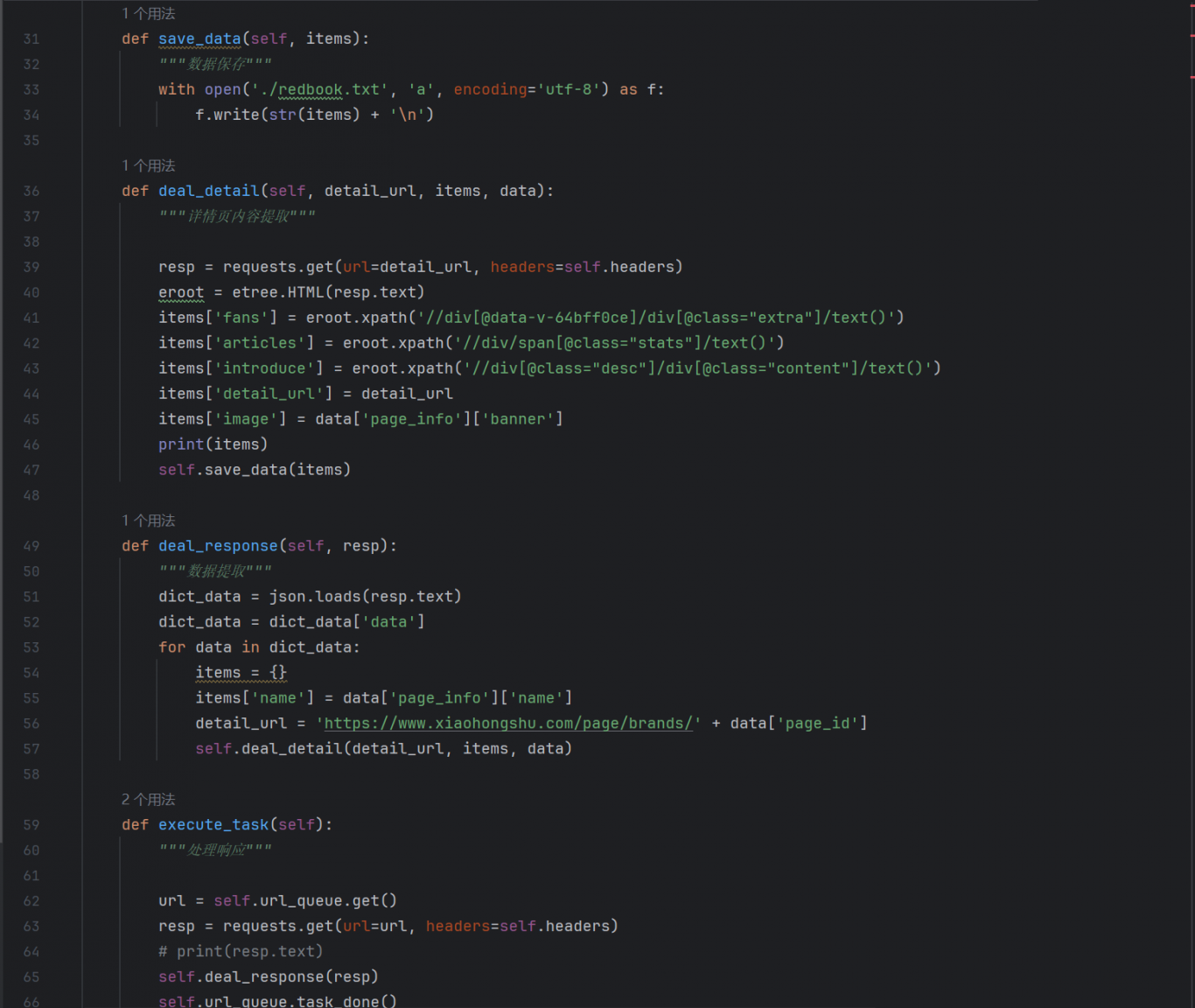
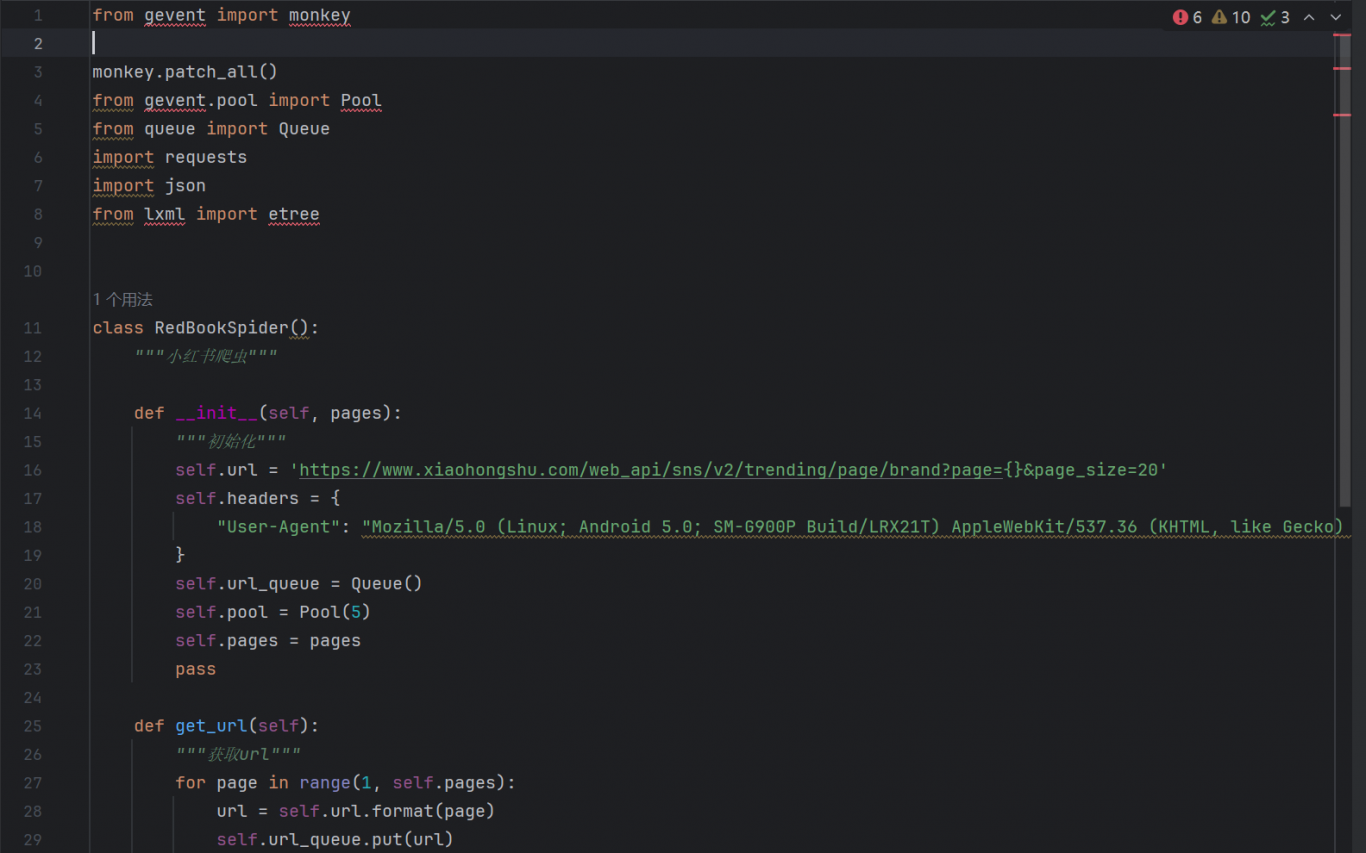
这是一个使用Python编写的网络爬虫项目,旨在抓取小红书网站上的品牌页面数据。项目通过模拟用户请求,获取品牌页面的基本信息、粉丝数量、文章数量、品牌介绍以及相关图片等数据。
主要功能:
1. 多页数据抓取:通过传入参数指定需要抓取的页面数量,爬虫将自动访问并抓取每一页的数据。
2. 异步处理:利用gevent库实现异步请求,提高爬虫的效率和响应速度。
3. 数据解析:使用lxml库对HTML页面进行解析,提取出所需的数据信息。
4. 数据存储:将解析后的数据以文本格式保存到本地文件中,便于后续分析和使用。
技术亮点:
异步请求:通过gevent库的monkey.patch_all()方法,使得requests库支持异步操作,从而提高爬虫的并发性能。
数据解析:利用lxml库的XPath功能,准确提取页面中的各类数据。
数据存储:将抓取的数据以JSON格式存储,便于后续的数据处理和分析。
在项目中的角色:
项目负责人:负责整体项目的设计和规划,确保项目按时完成并达到预期目标。
主要开发者:负责编写核心代码,包括网络请求、数据解析和数据存储等关键功能。
测试与优化:对爬虫进行测试,确保其在不同网络环境下都能稳定运行,并根据测试结果进行优化。
项目成果:
成功抓取了指定页面的品牌数据,包括品牌名称、粉丝数量、文章数量、品牌介绍和相关图片等。
通过异步处理技术,显著提高了爬虫的运行效率,减少了等待时间。
将数据以文本格式存储,方便了后续的数据分析和处理。
案例图片
相似案例推荐
其他人才的相似案例推荐
-

科大讯飞重庆教育直播装备展
作品包括直播活动banner图、直播详情的展示、展会演讲嘉宾
-

北京国际人才网
北京国际人才网是一个专门为海外人才提供就业机会和信息的平台。
-

商城
内容: 1、小程序实现对商品的浏览,加入购物车,下单。
-

商城
内容: 1、小程序实现对商品的浏览,加入购物车,下单。
-

仿bilibili移动端
1. 用户管理 用户注册:允许用户通过手机号或邮箱注册,设
-

pdf批量处理
批量读取文件夹中所有pdf文件,将全部pdf页面合并后,最终
-

四川省法规规章规范性文件数据库
四川省法规规章规范性文件数据库主要为四川省内各部门政府文件的
-

在线考试app
在线考试app是根据企业要求每个员工每年需要参与及完成的课程
-

测试结果
1. 测试结果总概况 项目名称:MMS 总用例数:200
-

数据大屏
综合数据大屏: 包括电子商务、产业品牌、电商培训、物流体系
-

Super宠物管理网,有风旅游网
网站包含功能涉及:1.用户登录登出 2.用户账户管理(修改信
-

so.com
360搜索引擎的后台开发,角色:后台开发专家,做了在线服务,
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

