
案例介绍
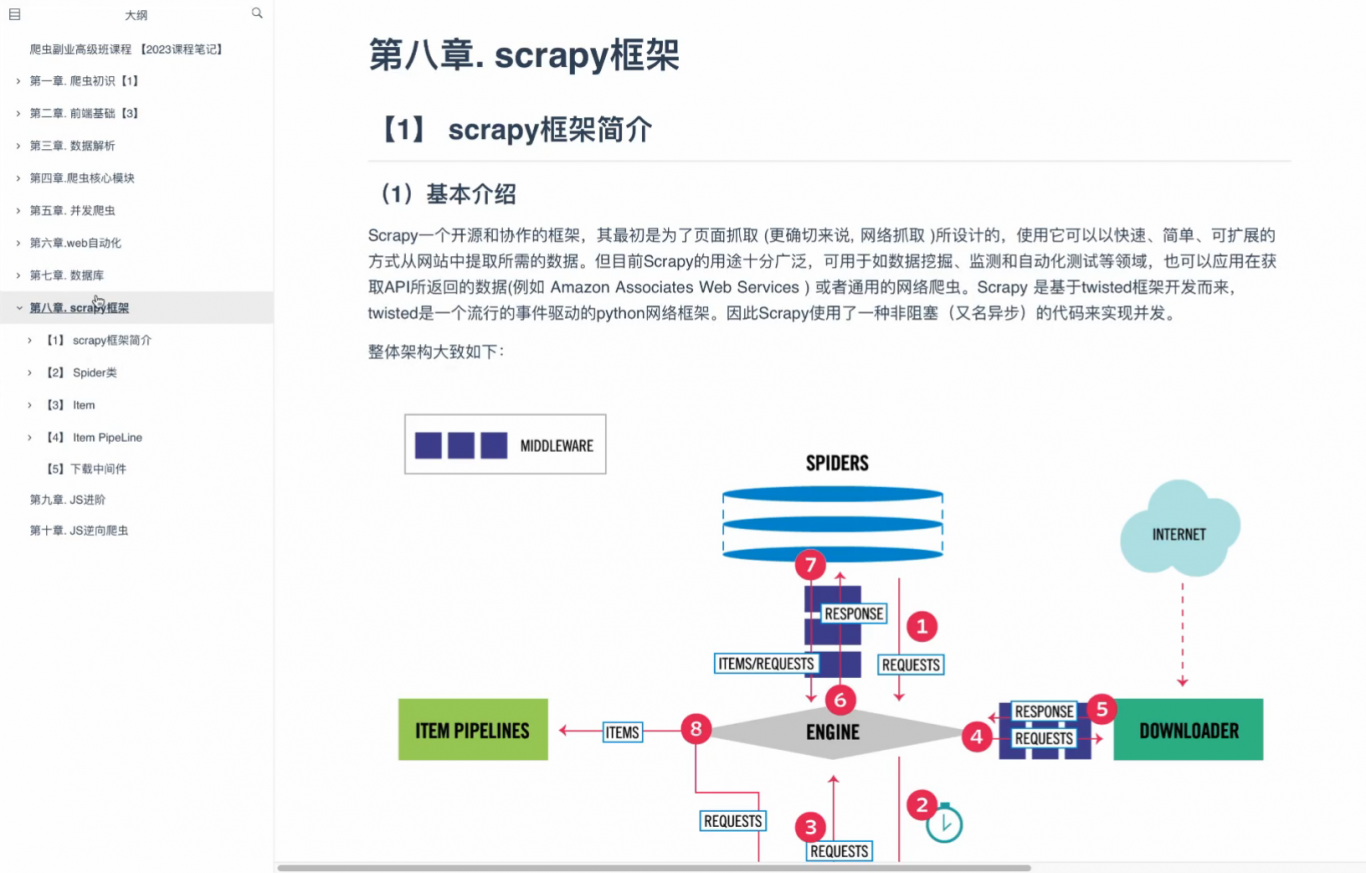
(1)基本介绍
Scrapy一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,使用它可以以快速、简单、可扩展的方式从网站中提取所需的数据。但目前Scrapy的用途十分广泛,可用于如数据挖掘、监测和自动化测试等领域,也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy 是基于twisted框架开发而来,twisted是一个流行的事件驱动的python网络框架。因此Scrapy使用了一种非阻塞(又名异步)的代码来实现并发。
(2) Spider类
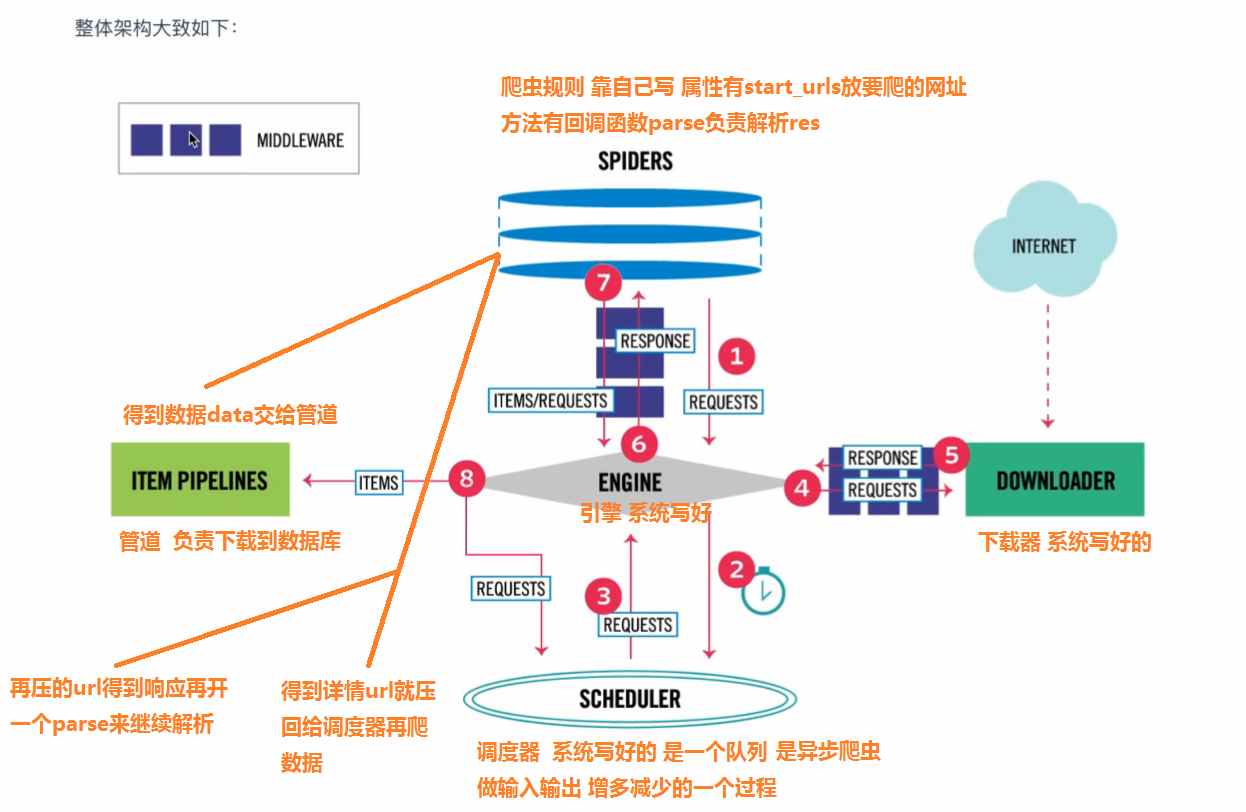
Spiders是定义如何抓取某个站点(或一组站点)的类,包括如何执行爬行(即跟随链接)以及如何从其页面中提取结构化数据(即抓取项目)。换句话说,Spiders是您为特定站点(或者在某些情况下,一组站点)爬网和解析页面定义自定义行为的地方。
1、 生成初始的Requests来爬取第一个URLS,并且标识一个回调函数
第一个请求定义在start_requests()方法内默认从start_urls列表中获得url地址来生成Request请求,
默认的回调函数是parse方法。回调函数在下载完成返回response时自动触发
2、 在回调函数中,解析response并且返回值
返回值可以4种:
包含解析数据的字典
Item对象
新的Request对象(新的Requests也需要指定一个回调函数)
或者是可迭代对象(包含Items或Request)
3、在回调函数中解析页面内容
通常使用Scrapy自带的Selectors,但很明显你也可以使用Beutifulsoup,lxml或其他你爱用啥用啥。
4、最后,针对返回的Items对象将会被持久化到数据库,
通过Item Pipeline组件存到数据库或者导出到不同的文件
案例图片
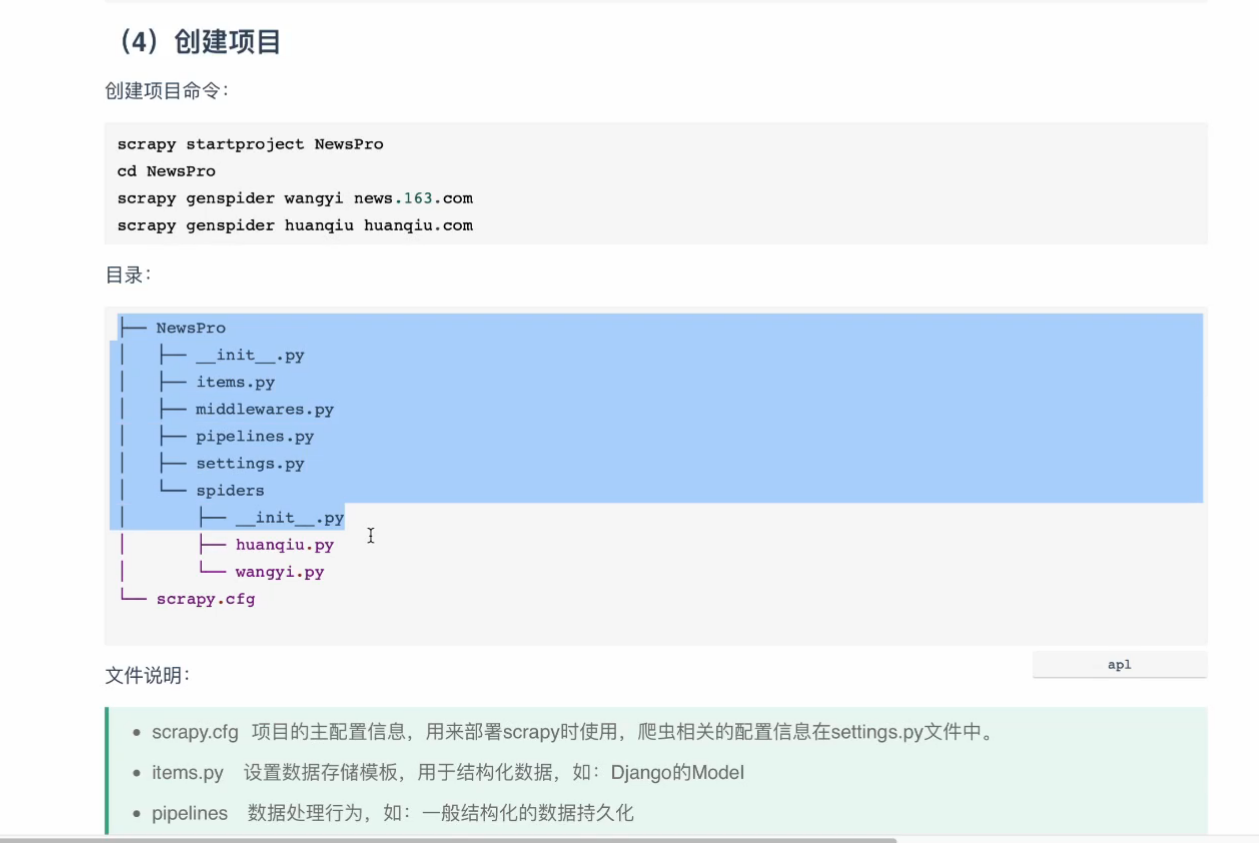
相似案例推荐
其他人才的相似案例推荐
-

网页题目数据爬取与整理项目
网页题目数据爬取与整理项目 在教育资源收集和整理的需求下,
-

豆瓣电影信息采集
豆瓣电影 Top250 信息爬取与存储项目 在数据分析和电
-

个人博客
具体看博客,真实三年经验vue2,vue3、ts都完全没有问
-

物联网服务支撑平台
物联网服务支撑平台是设备接入平台和应用平台的中间层,由自己独
-

数据资产运营平台
数据资产运营平台为市县地方政府的数据资产运营管理部门(包括但
-

销售大盘统计
项目类型 :数据大盘; 项目技术 :Vue2.0、antd
-

文件解析系统
机台log文件-》文件提取-》数据解析-》汇总展现 主要分
-

招聘信息数据分析
对上万条招聘信息进行数据分析,提炼整合,制作出一张简洁明亮的
-

数据采集
可以对相应的网址进行采集, 并把采集后的数据按照不同的类型
-

项目1:沃太综合能源平台
项目1:沃太综合能源平台 项目描述:该平台是B/S架构,提
-

VPP交易平台
项目3:VPP交易平台 项目概述:是虚拟电厂项目,B/S架
-

可以查看江苏省企业信用公示平台
项目初期,我遭遇了仓库代码与生产环境代码不一致的严峻挑战,这
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

