
案例介绍
这个项目旨在从某电影网站 抓取最新电影的下载链接和电影名称,并将其保存到本地的 JSON 文件中。项目实现了以下主要功能:
网页内容获取:
通过发送 HTTP 请求,从指定的 URL 获取网页源码。
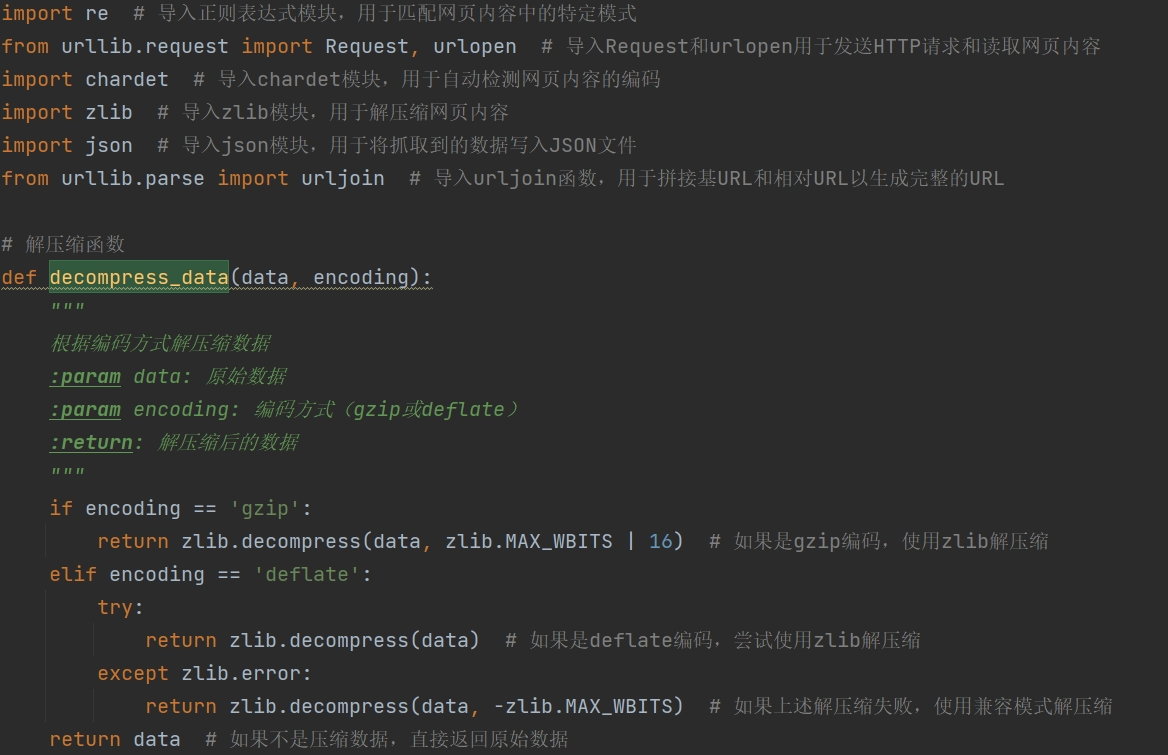
处理服务器可能返回的压缩内容,自动识别并解压缩 gzip 和 deflate 编码的数据。
编码处理:
使用多种编码方式解码网页内容,优先尝试 GB2312 编码,如果失败则使用 chardet 检测实际编码,最后尝试其他常见编码(如 utf-8、gbk、big5)。
确保能够正确解码网页内容,避免出现乱码问题。
数据解析:
使用正则表达式匹配网页源码中的特定内容,提取电影的下载链接和名称。
利用 urljoin 拼接基 URL 和相对 URL,生成完整的电影下载链接。
数据存储:
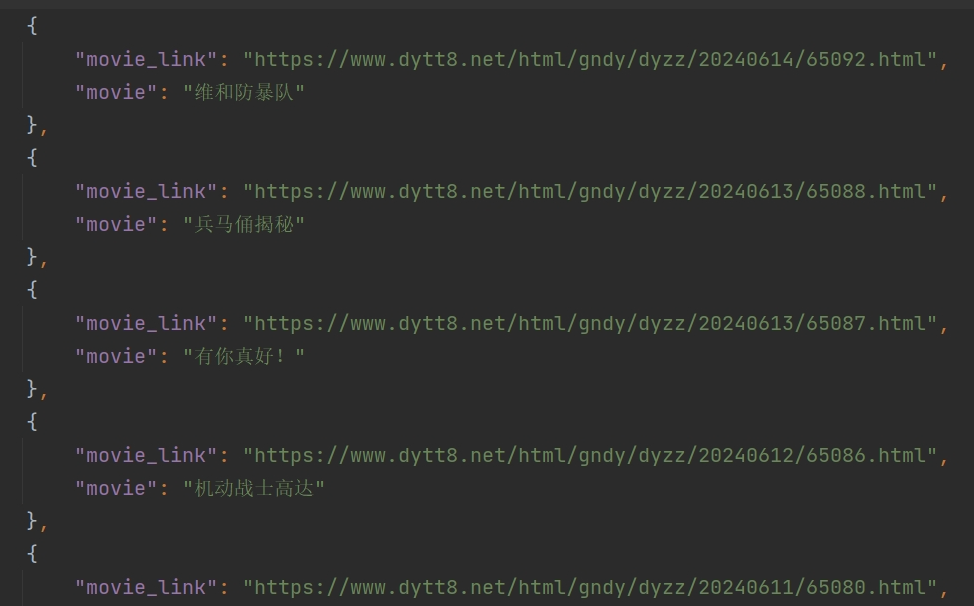
将解析出的电影下载链接和名称保存到 JSON 文件中,便于后续查看和使用。
生成的 JSON 文件格式化良好,支持中文字符显示。
错误处理:
在获取和解析网页内容过程中添加异常处理,确保程序在发生错误时能够输出有用的错误信息,便于调试和改进。
项目实施细节
模块使用:
re: 用于正则表达式匹配,精准提取电影下载链接和名称。
urllib.request: 发送 HTTP 请求,获取网页源码。
chardet: 自动检测网页内容编码,提升解码成功率。
zlib: 解压缩压缩网页内容。
json: 将解析结果保存为 JSON 文件。
urllib.parse: 拼接基 URL 和相对 URL。
编码处理:
优先尝试常见编码 GB2312,自动检测编码并尝试其他常见编码,确保解码成功。
正则表达式:
通过正则表达式匹配 <a> 标签中的下载链接和电影名称,并提取这些信息。
项目成果
JSON 文件输出:
成功抓取并保存了最新电影的下载链接和名称,生成的 JSON 文件结构清晰,便于查看和使用。
输出文件 movie2.json,包含最新电影的下载链接和名称。
扩展性:
项目可以扩展以抓取其他网页内容或处理更多不同编码的网页。
提供了良好的异常处理机制,便于在实际使用中应对各种网络和编码问题。
案例图片

相似案例推荐
其他人才的相似案例推荐
-

EPG电子节目指南
EPG是Electronic Program Guide的英
-

魔法表情
快手的魔法表情3D团队,支持各种3D魔法表情的玩法,渲染,优
-

某手直播回放视频导出工具
某手直播平台的直播回放视频只能看不能下载,通过协议分析,写了
-

视频生成软件
程序的功能是生成视频文件。根据excel配置文件,读取相关的
-

剧汇TV
剧汇TV(又名K365)是一个类似于爱奇艺、优酷、腾讯视频的
-

a站电影网视频pa虫
使用requests,json,BeautifulSoup,
-

体育比赛聚合网站
这是一个聚合了多种体育比赛的直播网站,包括直播回放高光等体育
-

好看视频服务端
作为服务端技术负责人 : 1. 主导并完成好看视频服务端整
-

做过二次开发,直播和录屏
微信 15396255806,对obs非常熟悉,可以联系我。
-

视频同步观看
该项目为chrome插件,功能是多人能同步观看在线视频。该项
-

影视监控管理
影视信息管理:用户可以搜索、新增、修改、删除影视信息,包括影
-

视频解析
我在此设计当中主要负责ui设计和代码框架编写以及测试,此代码
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

