
案例介绍
内容:
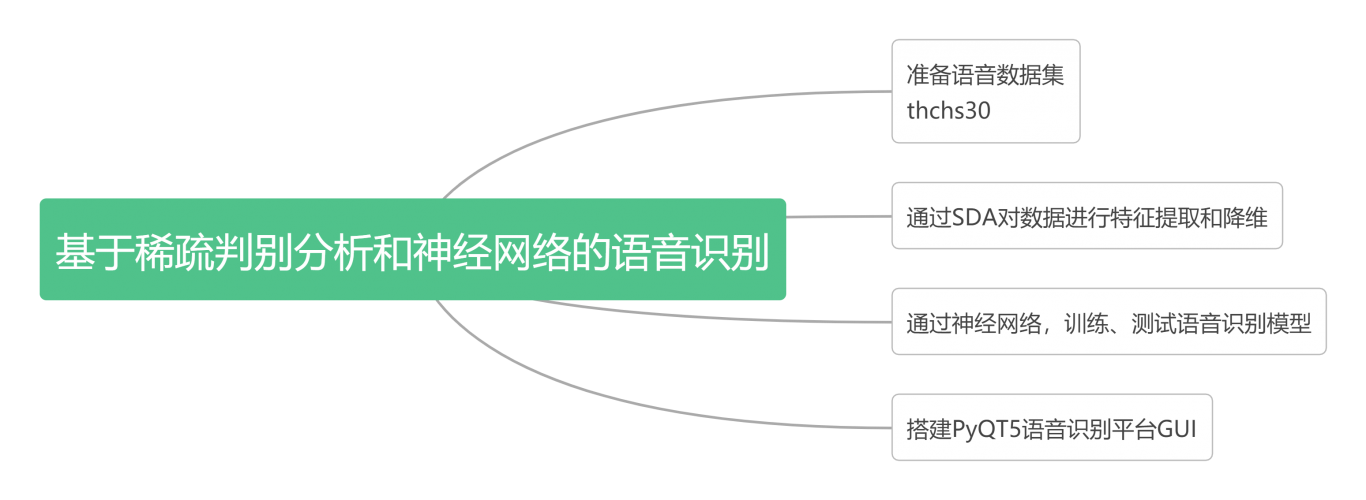
该项目提出了一种基于稀疏判别分析和神经网络的高精度语音识别技术。主要分为两
个方面,即语音识别中的特征提取和语音识别系统的搭建。主要具备的功能是对于语音识别模型的搭建、训练和测试,实现通过训
练完成的语音识别模型对传入的语音进行文字化的转化。
业绩:
在此项目中采用稀疏判别分析(SDA )来进行特征提取。相较于传统的线性判别分析(LDA),SDA 通过引入 L1正则化,限制模
型参数的大小和数量,得到更具有稀疏性、鲁棒性和可解释性的结果。
在语音识别模型训练和语音识别系统的搭建方面,采用 Tensorflow.keras 框架并通过 DNCC+CTC 模型来进行训练,以提高语音
信号的识别效果。
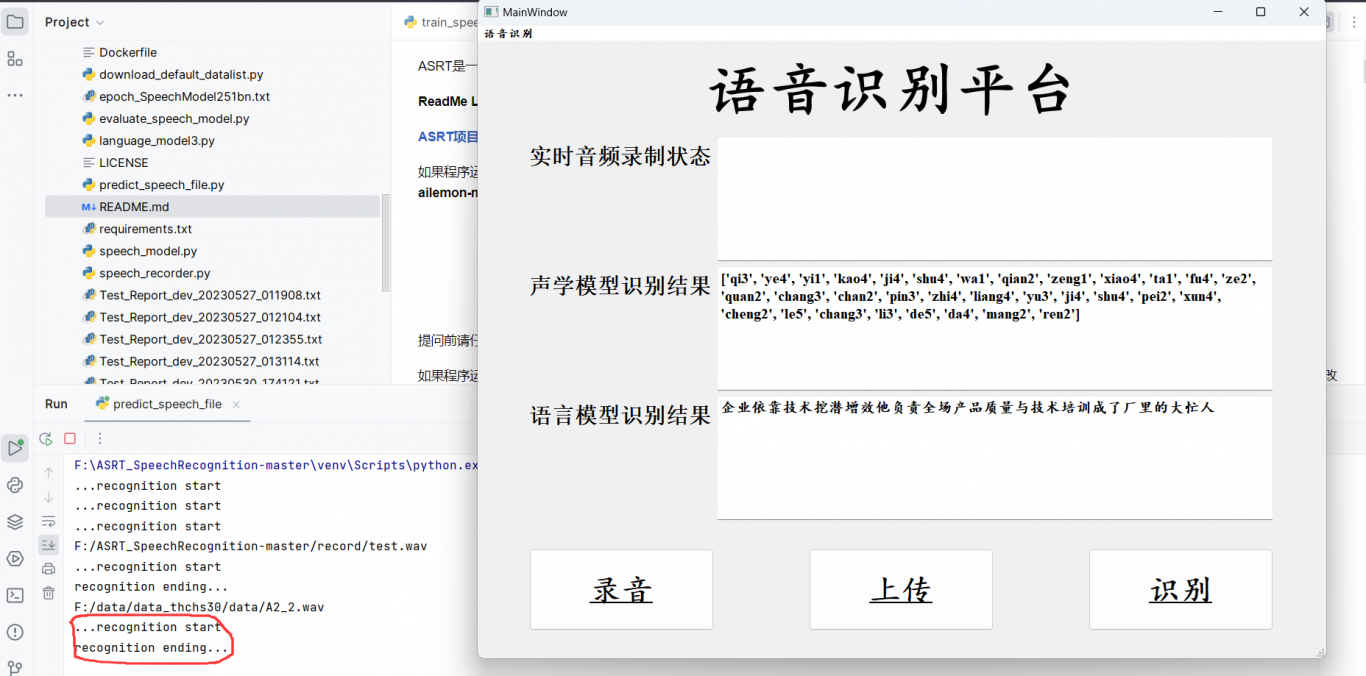
同时,为方便用户使用,采用 PyQT5实现 GUI 界面,使得语音识别技术更加易于操作。
案例图片
相似案例推荐
其他人才的相似案例推荐
-

私有化系统部署
项目通过ansible脚本封装, 能快速实现私有化部署mys
-

日志系统kibana日志二级排序
背景:之前搭建ELK时候经常听开发人员反馈说日志的数据和服务
-

统一存储服务系统
项目描述 连用大数据邮件归档系统是用于协助企业将全部的
-

餐厅管理系统
餐厅管理系统开发项目 项目描述:本项目是一个订餐网站
-

餐厅管理系统
餐厅管理系统 开发项目 项目描述:本项目是一个订餐网
-

自动爬取题干并从题库中筛选出正确答案
通过网页爬虫获取对应问题的题干,然后在题库中查找到对应的题目
-

机车监察系统
本系统的开发使用,可以为机务段统计工作人员,路局统计监察人员
-

绩效考核清算系统
本系统通过在每月初将上报的,和每月中下旬返回各局的两个机车报
-

机车监察系统
本系统的开发使用,可以为机务段统计工作人员,路局统计监察人员
-

绩效考核清算系统
本系统通过在每月初将全路上报的,和每月中下旬返回各局的两个机
-

易分析财务平台
易分析财务系统 web前端工程师 内容: 易分析财务平
-

资源开发ERP
项目名称:资源开发 ERP 项目描述:当前主要是建设公司的
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

