
案例介绍
手写数字识别项目
项目简介
本项目是一个基于卷积神经网络(CNN)的手写数字识别系统,通过深度学习技术识别和分类手写数字。手写数字识别是一项经典的图像分类任务,在光学字符识别(OCR)等领域有着广泛的应用。本项目利用Python编程语言和深度学习框架TensorFlow/Keras,实现了一个高效的手写数字识别模型。
项目功能
数据集
MNIST数据集:使用了广泛应用的MNIST手写数字数据集,该数据集包含60000张训练图片和10000张测试图片,每张图片为28x28像素的灰度图像,数字标签为0到9。
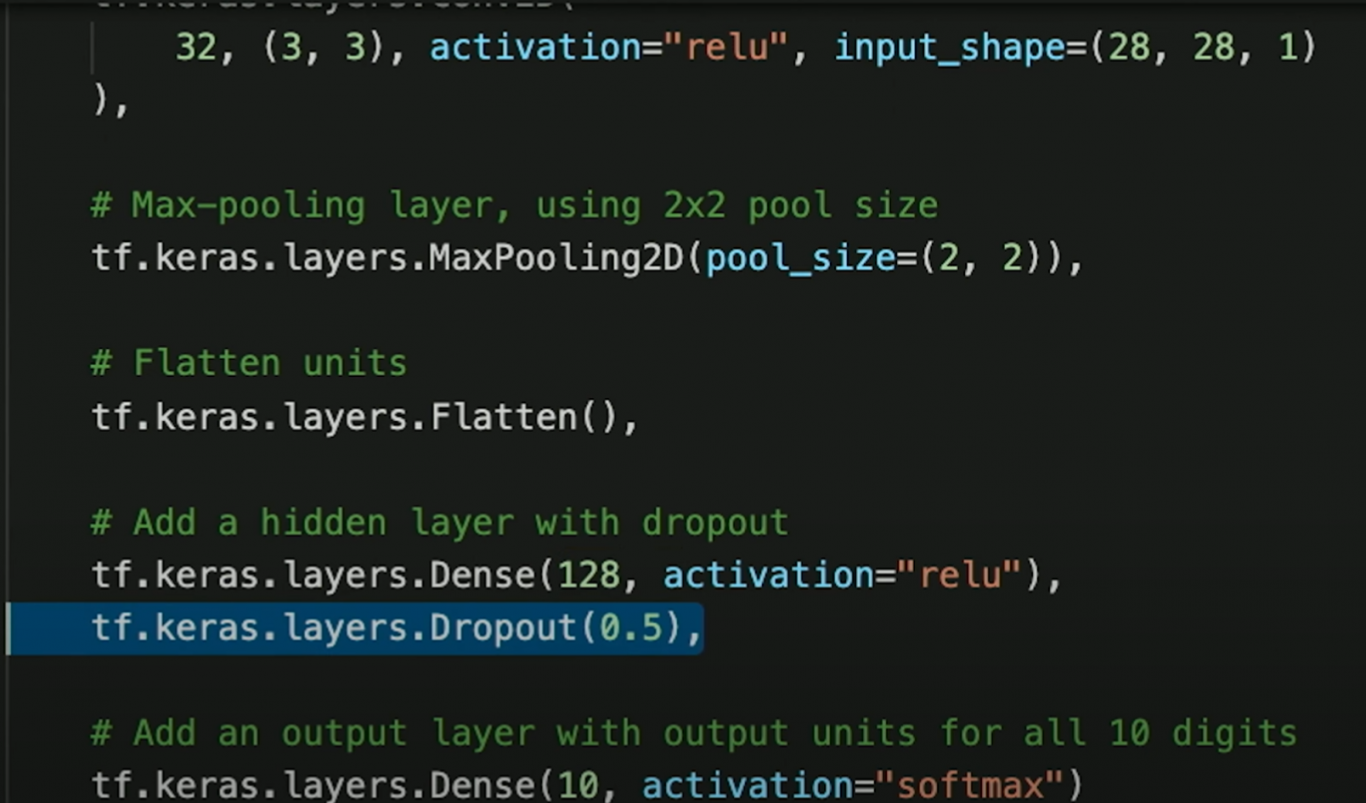
模型架构
卷积层:两个卷积层,用于提取图像中的特征。每个卷积层后面跟着一个ReLU激活函数和池化层(MaxPooling)。
全连接层:两个全连接层,用于对提取的特征进行分类。最后一层使用Softmax激活函数输出分类结果。
Dropout层:在全连接层之间加入Dropout层,以防止过拟合。
训练与测试
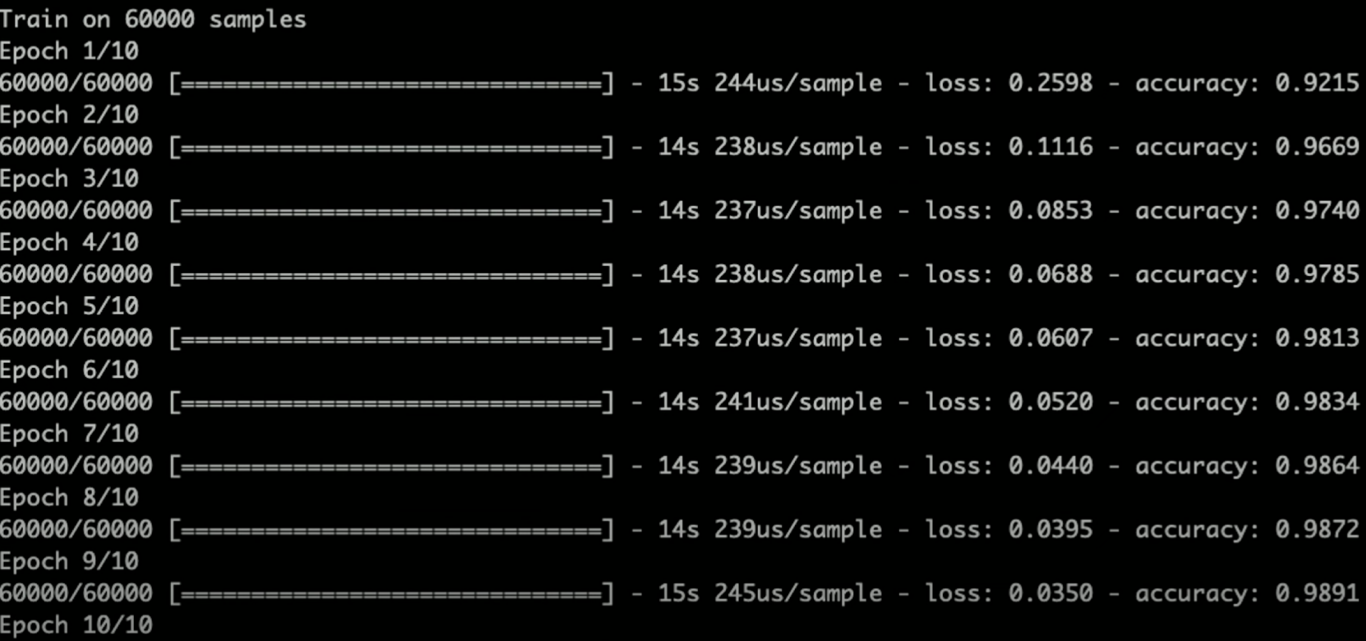
训练:使用交叉熵损失函数和Adam优化器对模型进行训练。模型在训练过程中自动调整参数,以最小化训练误差。
验证:在每个训练周期后,使用验证集评估模型性能,调整超参数以提高模型准确性。
测试:使用测试集对最终模型进行测试,评估模型的识别准确率和泛化能力。
结果与性能
准确率:模型在测试集上的准确率超过99%,表现优异。
混淆矩阵:生成混淆矩阵以分析模型在不同类别上的表现,识别出哪些数字容易混淆。
学习曲线:绘制训练和验证损失曲线,观察模型的训练过程和收敛情况
案例图片

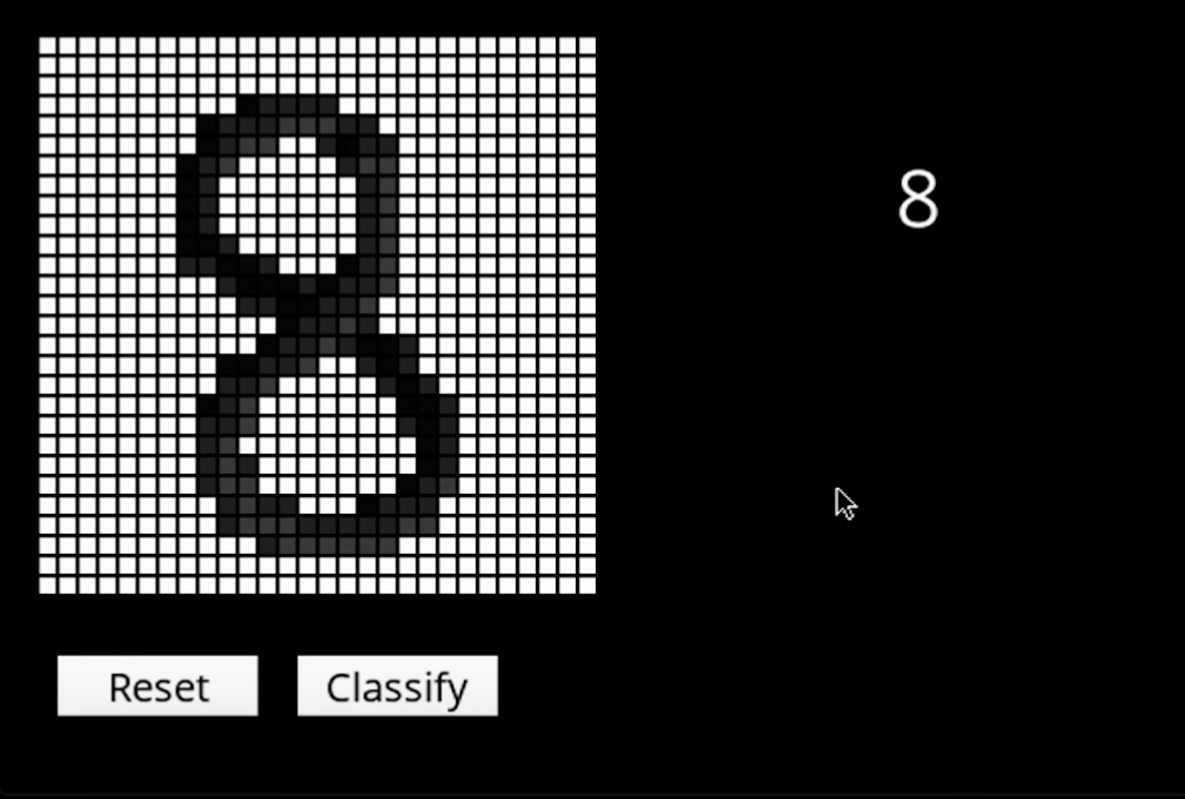
相似案例推荐
其他人才的相似案例推荐
-

xx云平台
管控车辆信息,涉及部分功能展示相关原型,希望理解,具体沟通时
-

xx车管家
此为app适配pad版,包含车辆基本信息及状态信息。具体内容
-

语音标注平台
独立开发,数据库设计、流程图编写、开发文档编写; 本地开发
-

医疗干燥设备程序自控系统
医疗干燥设备程序自控系统主要使用嵌入式技术,使用wince嵌
-

水源井控制系统
水源井控制系统,主要使用TCP通讯协议与PLC进行通讯,同时
-

基于YOLO算法的血细胞计数程序
加入颜色注意力机制(一个简单的FPN网络)的YOLOv5s模
-

LOL官方网站皮肤图片下载
通过requests库进行数据请求,获取LOL官方网站英雄皮
-

坦克大战游戏
利用python的pygame模块进行<<坦克大
-

中文图像摘要生成
项目功能:给定一张图像,自动生成其简短的中文描述,概述图像内
-

古建筑图像自动分类软件
设计实现了基于CNN最优训练轮次与Boosting分类器的混
-

基于Spark的手写数字图像分类
从0到1搭建大数据Hadoop集群,将图像数据存储在分布式文
-

基于YoloV3的茶青检测系统
针对某批茶叶进行多目标检测,方便之后进行茶叶的分类,评定对应
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

