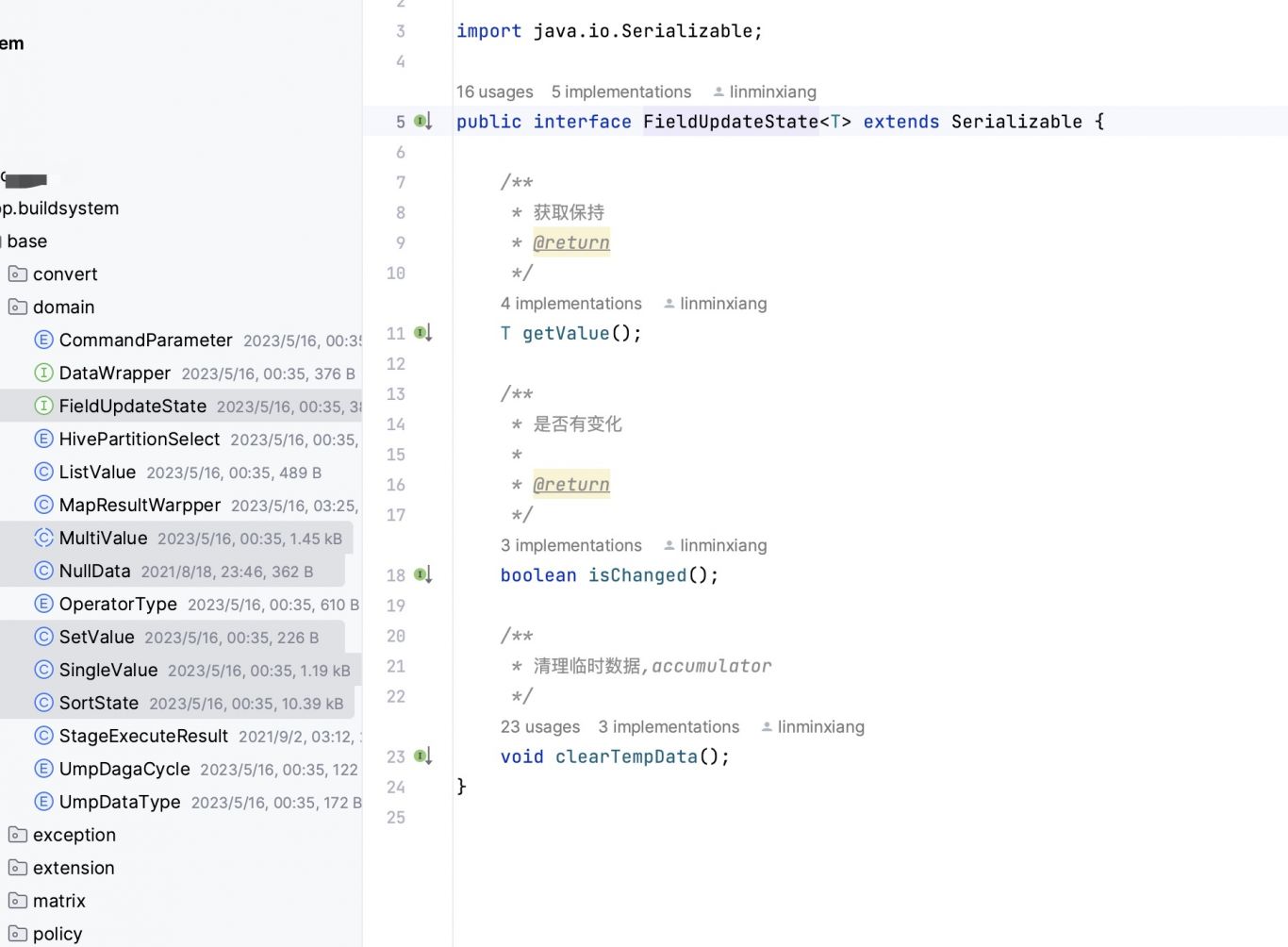
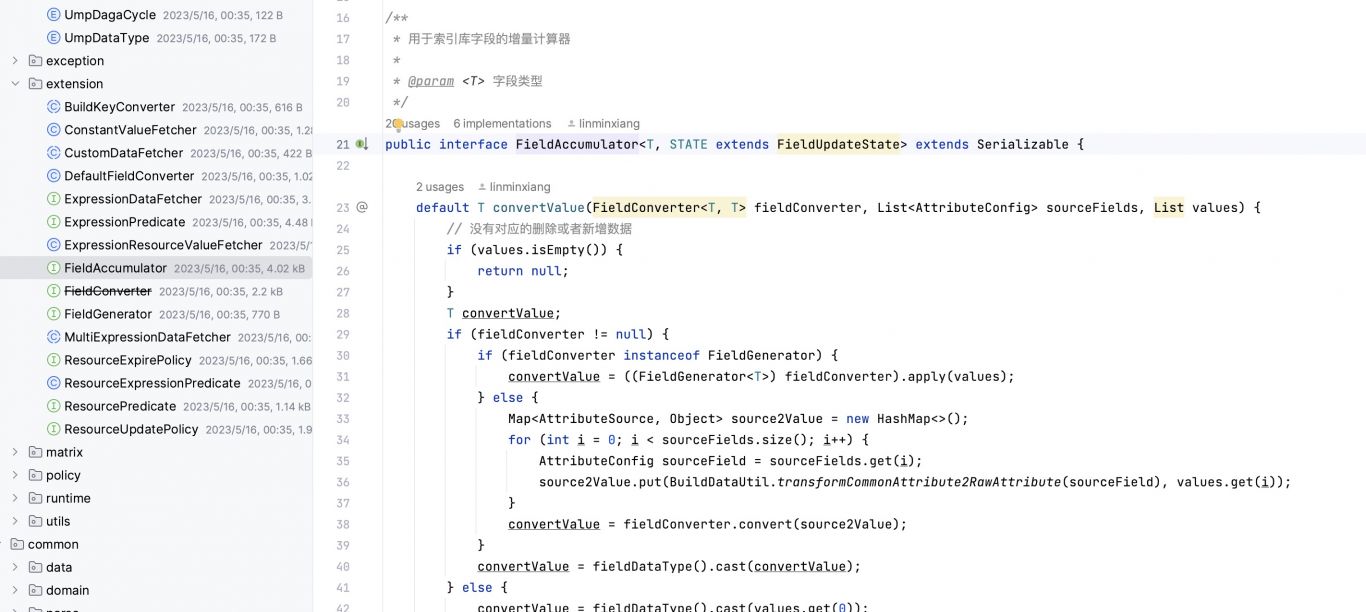
秒级超大规模数据聚合计算模型

案例介绍
为满足业务需求,需要将十万级别的数据进行秒级聚合,并满足如下条件:
1、系统数据处理量平均在万/秒,峰值在30w/秒,整体数据时效性要求5分钟以内
2、保证数据的准确性,如果发生数据错误,需要在小时级恢复(3小时以内)
3、定期进行数据校准,并能恢复不一致的数据
基于flink和spark引擎,和doris、redis等存储中间件,实现了一套流批一体的lamda架构,实现百万级数据的秒级聚合处理,整体时效性控制在3分钟以内,同时能够进行快速数据回滚和天级的数据一致性校准能力。
整体架构和落地开发均由我独立完成,并顺利应对了当年线上最大的促销活动
案例图片
相似案例推荐
其他人才的相似案例推荐
-

多商购物系统
目前能抓取小红书、抖音、快手、B站、微博的视频、图片、评论、
-

申通快递数据参谋系统
项目介绍:该项目在申通快递公司开发的项目。为了解决省区多头看
-

美团管家
美团管家是一个面向商家的管理平台,旨在帮助商家提升运营效率和
-

电子商务
用户注册与登录 注册功能:用户可以通过手机号码、邮箱或
-

mall
项目环境:Windows, Spring, SpringBo
-

购物平台
1、负责商品开发组,前端页面开发、页面路由逻辑配置 2、独
-

移动端H5
本人负责全部的前端开发工作 作品功能是进入页面进行打卡,和
-

商城小程序
微信版女装小程序,商家个人版,UI简约精美,支持在线选品,购
-

saas进销存系统
经销商管理系统是以企业的销售渠道建设为重点,针对经销商的日常
-

多平台数据爬取
抖音、小红书 多个平台指定数据爬取 以及 自动关注 消息发送
-

草地市场
项目描述: 用spring boot(Java)+acti
-

NSWAP NFT交易平台
该平台主要是用于进行NFT交易的场所,类似海外著名平台Ope
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

接收人才推送

联系需求方端客服