电商网站数据爬取与分析

案例介绍
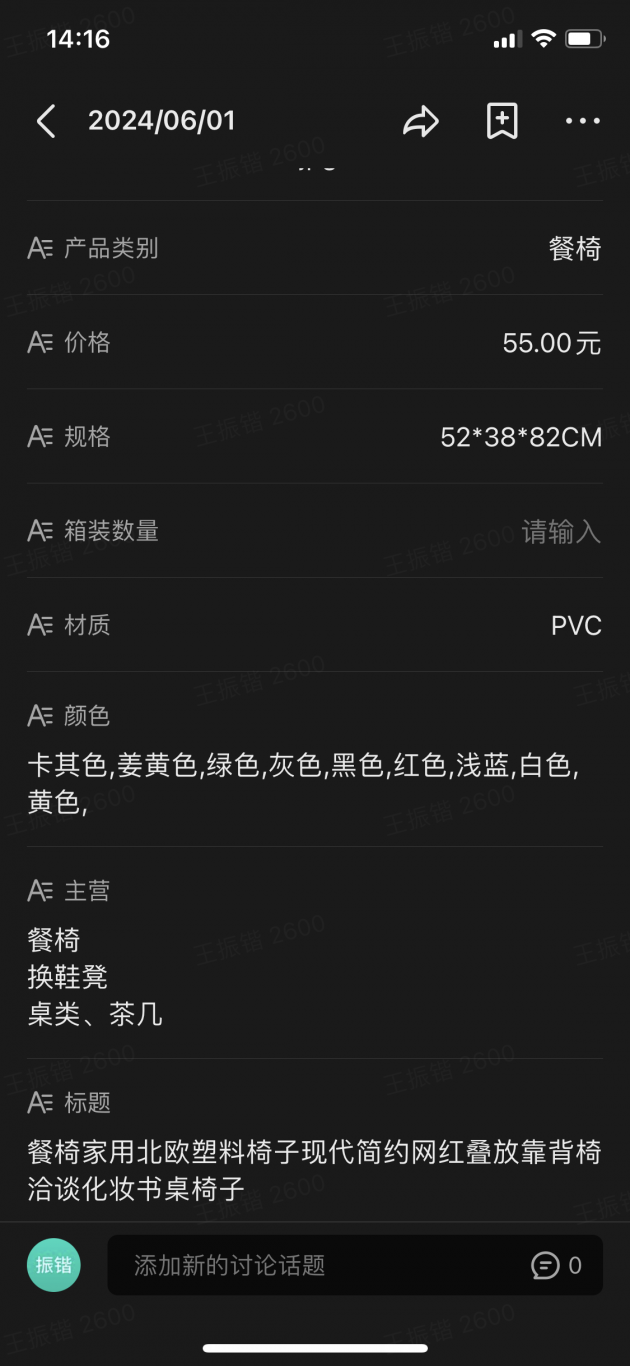
项目名称:电商网站数据爬取与分析
项目描述
本项目旨在爬取某电商网站的商品信息,并对数据进行分析。通过该项目,熟悉了Python爬虫技术、数据存储和基本的数据分析方法。
项目目标
爬取某电商网站的商品列表和详细信息。
存储爬取的数据到本地数据库。
对爬取的数据进行清洗和分析,生成可视化报告。
项目技术栈
编程语言:Python
爬虫框架:Scrapy
网页解析:BeautifulSoup、lxml
数据存储:MySQL、CSV
数据分析与可视化:Pandas、Matplotlib、Seaborn
辅助工具:Selenium、Requests、正则表达式
项目步骤
1. 需求分析与目标网站选择
分析电商网站的结构,确定需要爬取的数据,包括商品名称、价格、评分、评论数等。
选择合适的目标网站,并研究其HTML结构和反爬机制。
2. 爬虫设计与实现
Scrapy框架搭建:创建Scrapy项目,定义爬虫类和Item类。
发送请求:使用Scrapy的Request发送HTTP请求获取网页内容。
网页解析:结合BeautifulSoup和lxml解析HTML文档,提取商品信息。
数据存储:将爬取的数据存储到MySQL数据库和CSV文件中,方便后续分析。
3. 数据清洗与分析
数据清洗:使用Pandas对数据进行清洗,包括处理缺失值、重复数据和异常值。
数据分析:计算商品的平均价格、评分分布等基本统计信息。
数据可视化:使用Matplotlib和Seaborn生成数据的可视化图表,如价格分布图、评分分布图等。
4. 反反爬措施
请求头设置:在HTTP请求中设置User-Agent等头部信息,模拟浏览器访问。
IP代理:使用IP代理池,避免因频繁访问被封禁。
请求延迟:设置合理的请求间隔,防止被网站检测为爬虫行为。
项目成果
成功爬取了目标电商网站的数千条商品数据。
数据存储在MySQL数据库和CSV文件中,便于进一步分析和处理。
生成了多份数据分析报告,包括价格分布、评分分布和热销商品分析等。
通过数据可视化图表直观展示了商品的基本信息和市场趋势。
案例图片

相似案例推荐
其他人才的相似案例推荐
-

大唐阀井小程序
使用uniapp独自进行开发、使用户和管理员更加方便的对阀井
-

大唐阀井小程序
使用uniapp独自进行开发、使用户和管理员更加方便的对阀井
-

大唐钢瓶小程序
使用uniapp进行开发、从头到尾都是独自开发、是陕西大唐给
-

鋆汽配
多商户B to B to C电商系统 支持网页端和小程序,
-

PaaS电商云平台
工业级PaaS云平台+SpringCloudAlibaba+
-

购物平台
负责前端项目,主要负责物流的前端页面 编写、逻辑处理、以及前
-

秀峰商城
秀峰商城集商品浏览、购物车、在线支付、订单管理于一体,提供丰
-

ofashion-迷橙
OFashion迷橙是全球时尚小众精品购物网站,轻松海外购入
-

快巴出行
快巴出行是一款专注于城际出行的移动服务平台,为乘客提供定制客
-

唐煦优选saas商城
项目名称:唐煦优选saas商城 项目所用技术: 前端:v
-

器格商城
技术栈:Vue3+TypeScript+UniApp+uVi
-

合规信息监控平台
项目背景:目前合规工作统计范围广泛,人工跟踪效率低下,且纸质
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

接收人才推送

联系需求方端客服