新闻文本分类

案例介绍
项目主要目的为使用 人工智能技术对新闻进行分类,减少人力成本提高效率。
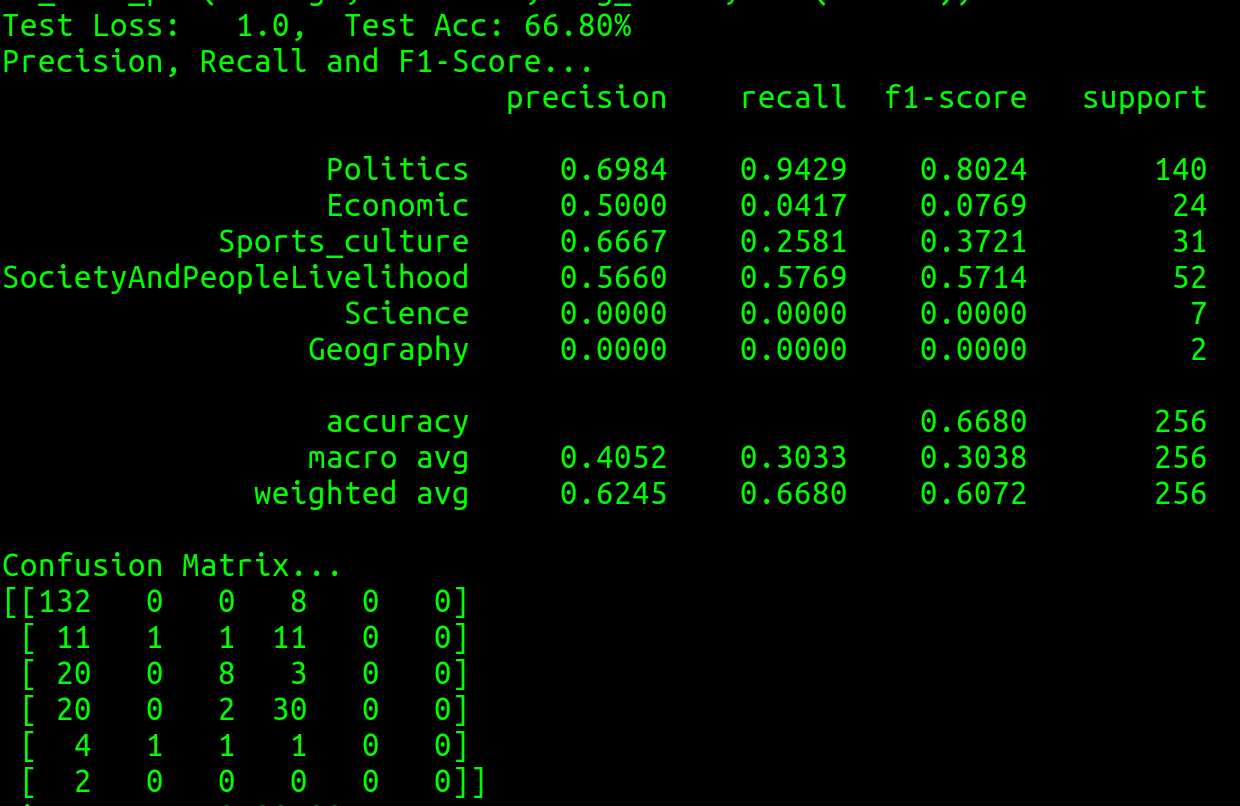
1. 模型主要分为以下5个步骤进行:数据爬取、数据选择与读取、数据摘要与清洗、模型选择、模型训练与评估、模型组合与预测效验。
2. 使用python及其相关科学库如:numpy、pandas等技术开发,选择的算法模型有:词袋模型BOW(Bag of Words)、词向量(Word Embedding)、神经网络,采用交叉验证的方式训练模型,来降低过拟合情况,最后对上述三个模型的结果组合加权平均。
3. 数据爬取主要使用Python requests库。
4. 使用Jieba中文分词库对中文进行分词处理,来完成数据选择与读取。
5. 独立完成TF-IDF算法对处理好的数据进行摘要与清洗。
6. 使用开源TestCNN和TestRNN模型对数据进行处理。
案例图片

相似案例推荐
其他人才的相似案例推荐
-

码友邦AI平台
自己开发的ai平台,支持 GPT 3.5、4.0、Kimi、
-

影刀墨滴文章自动发小豆芽RPA机器人
1、 登录发布者的墨滴软件; 2、点击软件右上角的复制
-

benders-cut算法应用
在这个项目中,处理了大量的数据,建立了超级复杂的数学模型,基
-

工业排产运筹优化算法项目
1.多维度变量(工序/工人/工位/机器,多维整数决策变量)
-

股票价格预测
这个项目通过分析亚马逊、多米诺披萨、网飞等股票的历史数据,使
-

YOLO目标检测任务
项目名称: 基于YOLOv8的实时目标检测系统 时间:
-

绿色国网内网后台管理系统工业企业能效助手
项目、绿色国网内网后台管理系统-电网项目-工业企业能效助手
-

虚拟人
我利用Unreal Engine(UE)开发了一个虚拟人项目
-

abc
以下是我几个出彩的项目,这些项目能够充分展现我的技术实力:
-

仕城办公
项目内容:仕城办公app是一款针对办公房产租赁市场提供服务的
-

车辆检测、车流统计
目标检测-车辆检测商用模型:基于 mmdetection 框
-

人脸关键点识别
目标识别-人脸关键点检测识别算法:采用前沿人脸检测libfa
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

