
案例介绍
基于Python的豆瓣读书的爬虫,方便大家搜罗各种美美书!
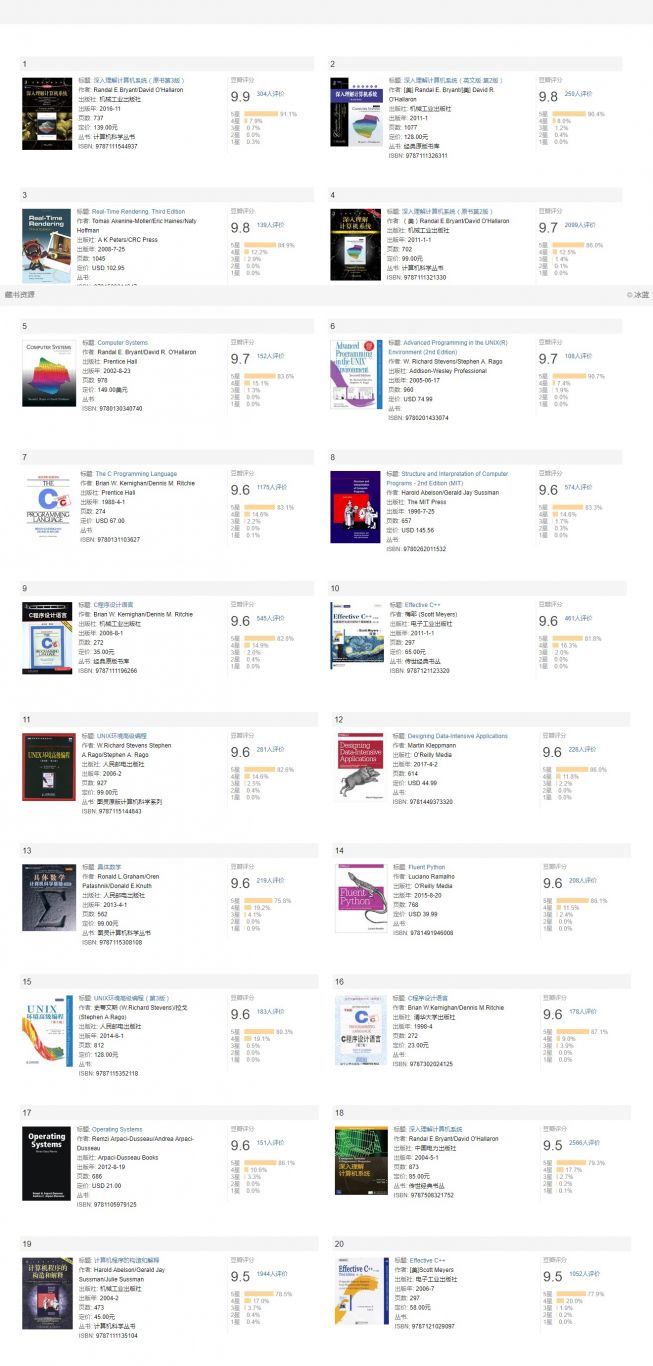
爬了一遍豆瓣图书数据,爬下了3000000+条目,这次爬的时候特意爬取了每个图书页面中的“喜欢读XX的人也喜欢条目XX”,最近对数据进行了处理和可视化做了这个新的WebApp。该App每本书作为一个节点包含评价人数、评分、被链接数(类似Google的RankPage算法根据网页被链接的数目来排网页的重要性,一般越好的书籍被链接的数目也越多)、链入的图书节点、链出的图书节点等信息。
实现功能
1 可以爬下豆瓣读书标签下的所有图书
2 按评分排名依次存储
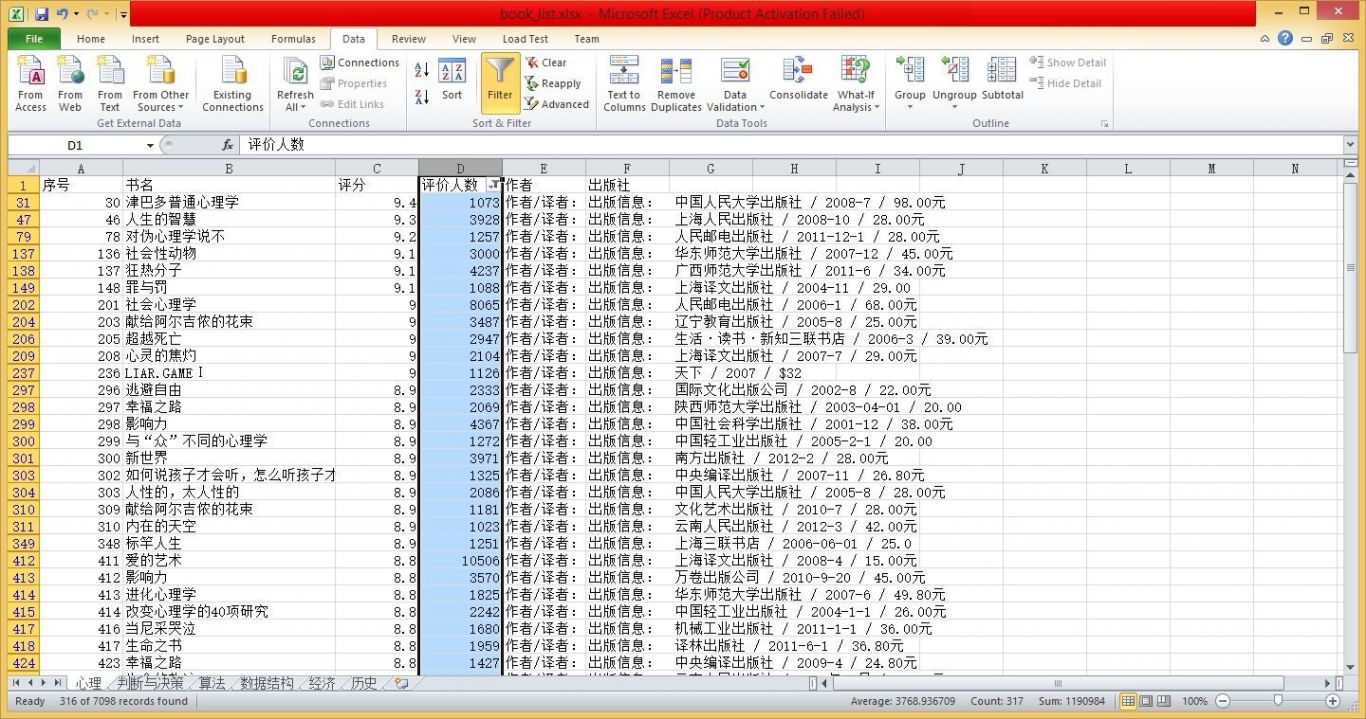
3 存储到Excel中,可方便大家筛选搜罗,比如筛选评价人数>1000的高分书籍;可依据不同的主题存储到Excel不同的Sheet
4 采用User Agent伪装为浏览器进行爬取,并加入随机延时来更好的模仿浏览器行为,避免爬虫被封(更新于 2015-5-20)
案例图片

相似案例推荐
其他人才的相似案例推荐
-
")
理论物理研究:量子几何偶极子(QGD)
• 发现并定义了量子二体问题中的基于量子几何属性的区别于Be
-

得到结算台,购物车开发
完成购物车,结算台,活动的,消息推送的开发,成功应对了每次大
-

国际象棋教学
实用的国际象棋教学工具。 主要功能包括: 1、国际象棋教
-

全品学堂
全品学堂是一个学习平台。学堂精心制作了涵盖小、初、高各年级的
-

个人录制的bilibili教学视频
个人利用闲暇时间录制的技术视频,包括Django、Flask
-

好生源
1.项目描述:教培行业招生的裂变营销系统,校精灵旗下多款 S
-

小荧星小程序
项目介绍: 这个项目是一个使用 uniapp 加 vue 加
-

墨客
App是一款在线书法教程软件,包括用户系统,课程展示系统,作
-

体简-体育教学
这平台是4人完成,我主要负责产品设计、后台架构 涵盖 小程
-

灵梦天文台
项目概述:项目为灵梦天文台,是学习科普类平台,供用户学习和了
-

创意时光
项目名称:创意时光 项目简介: 创意时光是一个基于HT
-

双端队列与kmp算法
双端队列(Deque)与KMP算法是计算机科学中两个重要的概
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

