
案例介绍
1、故障发现与登记:
通过监控系统自动报警、用户报障或其他途径发现故障。
登记故障信息,包括故障发生时间、地点、现象描述、初步影响范围、受影响的服务或系统、报障人联系方式等。
2、故障响应与初步处理:
值班工程师接收到故障信息后立即响应,并尝试初步诊断和处理。
根据故障严重程度,可能需要按照预先设定的故障分级预案进行操作,如P1/P2/P3/P4等级别划分,紧急程度依次降低。
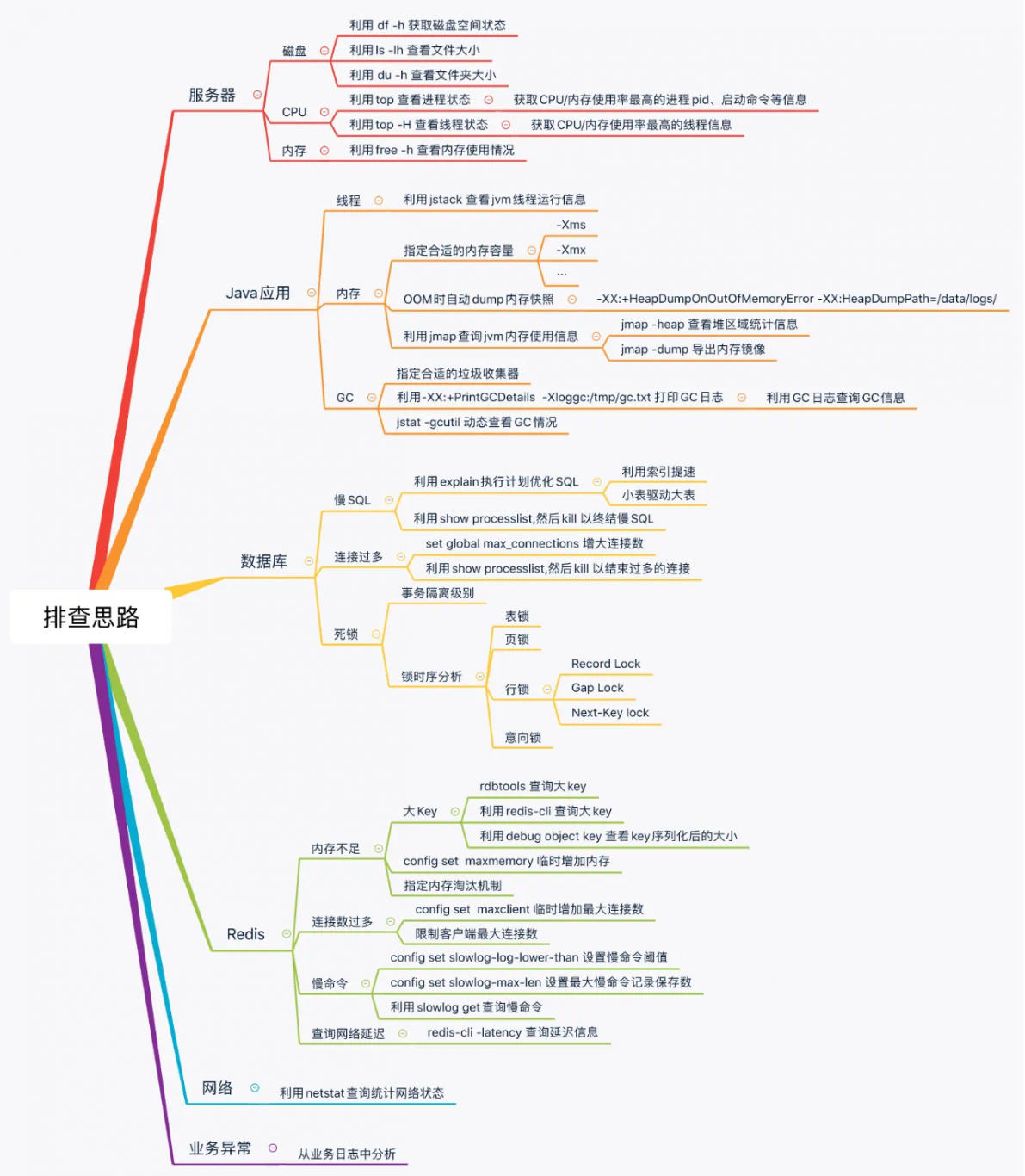
3、故障排查定位:
联系相应领域的运维工程师进一步排查故障,利用日志分析、性能指标监控、系统状态检查等手段定位故障点。
如果故障涉及到多个系统或团队,可能会涉及到跨部门协作和资源调度。
4、应急处理与服务恢复:
若故障符合预案条件,则执行预设的应急预案,尽快恢复业务运行。
制定临时解决方案,以减轻故障对业务的影响,同时考虑是否有冗余资源可以切换或回滚至安全状态。
5、根源分析与解决:
定位故障的根本原因,防止故障复发。
对于复杂问题,可能需要召开故障分析会议,形成故障报告,记录问题细节、分析过程和修复方案。
6、故障修复与验证:
实施修复措施,并在修复后验证服务是否恢复正常。
验证其他关联服务是否受到影响,确保整个系统稳定运行。
7、故障处理总结与改进:
记录完整的故障处理过程,总结经验教训,更新运维文档和应急预案。
分析潜在风险点,提出改进建议,完善运维体系和流程。
8、反馈与沟通:
向相关人员(包括内部团队和外部用户)及时通报故障处理进展和最终结果。
对于严重影响服务质量的故障,可能还需要向管理层汇报,并对外发布故障公告和服务恢复声明。
在整个过程中,强调时效性、准确性和有效性,遵循“先恢复服务,后分析原因”的原则,以保障业务连续性和用户体验。
案例图片
相似案例推荐
其他人才的相似案例推荐
-

2000+节点k8s集群搭建及维护
1. 负责使用 ansible 自动化部署集群 2. 负责
-

Prometheus+Thano监控系统
1. 负责整体技术架构选型及部署实施 2. 使用 Go 开
-

菜谱推荐小程序
担任前端后端开发 1.教导人们如何做菜。菜谱推荐 2.用
-

菜谱推荐小程序
担任前后端开发 1.教导人们如何做菜。菜谱推荐 2.用户
-

蚂蚁智科数据保护伞
1、支持阿里云公有云或专有云提供的数据安全访问系统,基于阿里
-

区域块
请查看我们的 github。 https://github
-

C-SMART
以智慧工地大屏BI和人员一码通(人员管理的后台应用)为承载,
-

智慧农业
智慧农业通过智慧农业大数据平台,实现园区内虫情、孢子、气象、
-

微服务项目云原生改造
原有微服务项目部署在私有云的虚拟机上,为了降低机器和运维成本
-

端到端监控平台自动巡检机器人
在中移信息技术有限公司,基于磐匠IPA平台+python独立
-

kuesphere/k8s
1、负责devopt工具链建设包括不限于代码管理、构建、持续
-

监控/日志/数据库
1、负责devopt工具链建设包括不限于代码管理、构建、持续
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

