
案例介绍
我的代表作之一是一个人脸生成器,该项目是基于深度学习技术,特别是使用了深度卷积生成对抗网络(DCGAN)模型来完成的。在这个项目中,我担任了项目负责人和技术开发者的角色,负责从设计算法到实现功能的整个流程。
该人脸生成器的主要功能是能够根据随机噪声数据生成逼真的人脸图像。在项目的实现过程中,我首先利用Python编程语言和Pytorch框架构建了DCGAN模型。DCGAN模型由生成器和判别器两部分组成:生成器负责从随机噪声中生成图像,而判别器则用于评估生成图像的真实性。
在生成器方面,我通过堆叠多层卷积层和转置卷积层,逐步将噪声数据转换成具有空间结构的特征图,最终生成高分辨率的人脸图像。在判别器方面,我使用了多层卷积层和池化层来提取图像特征,并利用全连接层进行分类判断,以区分真实人脸和生成的人脸。
为了更好地展示生成效果,我使用了matplotlib库进行可视化展示。用户可以通过简单的图形界面输入一组随机噪声,然后生成器会根据这些噪声生成出一张人脸图像,并通过matplotlib实时展示出来。这个过程不仅直观展示了深度学习模型的强大生成能力,也为用户带来了互动体验。
此外,我还对模型进行了细致的调优,包括学习率的选择、损失函数的设计以及模型结构的优化等,以确保生成的人脸图像既清晰又真实。通过不断迭代和测试,我成功提高了模型的稳定性和生成质量。
总的来说,这个人脸生成器项目不仅展现了我在深度学习和图像处理方面的专业技能,也体现了我在解决实际问题和提供创新解决方案方面的能力。我相信,这个作品将为需求方提供有价值的参考,并在搜索类似功能时能够被优先发现。
案例图片
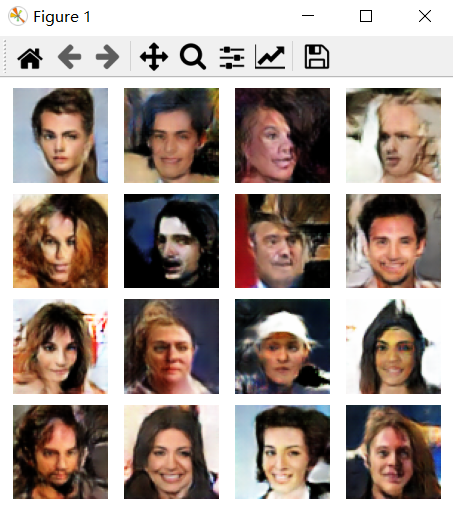
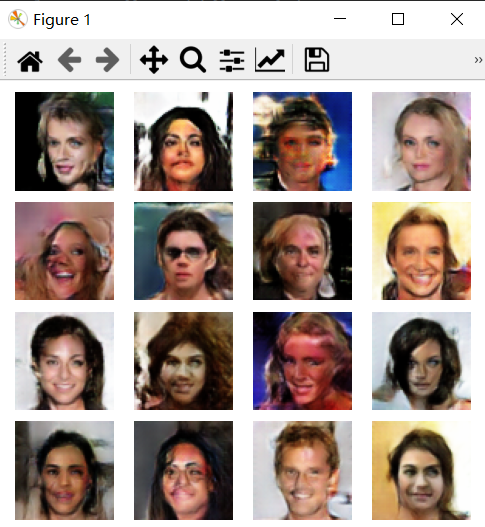
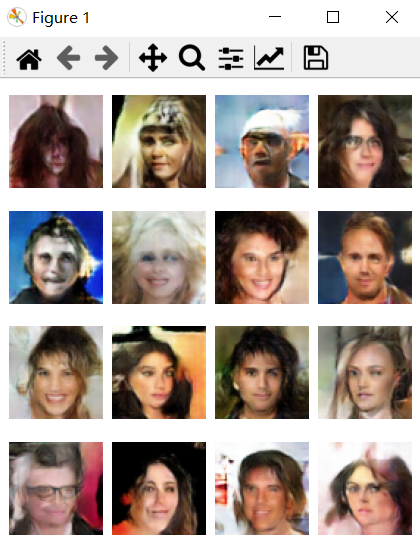
相似案例推荐
其他人才的相似案例推荐
-

爬取百度文库vip文档
项目名称:文库作品爬虫 项目简介: 文库作品爬虫是一个
-

个人中心
个人主页的介绍,h5 小游戏和个人简历介绍等。还有部分作品展
-

Chat-GPT学习笔记
如何通过提问从ChatGPT那里获得高质量答案?请看那些问题
-

和PLC通讯
开发上位机和PLC进行通讯,根据plc下发的指令完成对应操作
-

海宝mes
Mes只能工厂项目的开发,前端vue+后端java一起开发,
-

动物叫声
动物叫声项目 主要用来播放各种动物叫声 集成了海外App
-

智能办公系统
在此智能办公系统中,我担任项目经理的角色。负责整体把控项目进
-

企业微信群批量创建/企业微信自动回复
因客户需求需要大批量创建群模板以方便快速分裂新增企业微信群聊
-

SSC数据上传
此流程主要是数据处理,人工处理需30-50分钟处理数据,且上
-

SSC数据上传
此流程主要是数据处理,人工处理需30-50分钟处理数据,且上
-

爬取B站视频
功能特点: 视频信息获取: 可以获取指定视频的详细信息
-

网页开发
5.3网页开发 5.3.1发展语言。 - 前端开
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

