
案例介绍
项目名称:文库作品爬虫
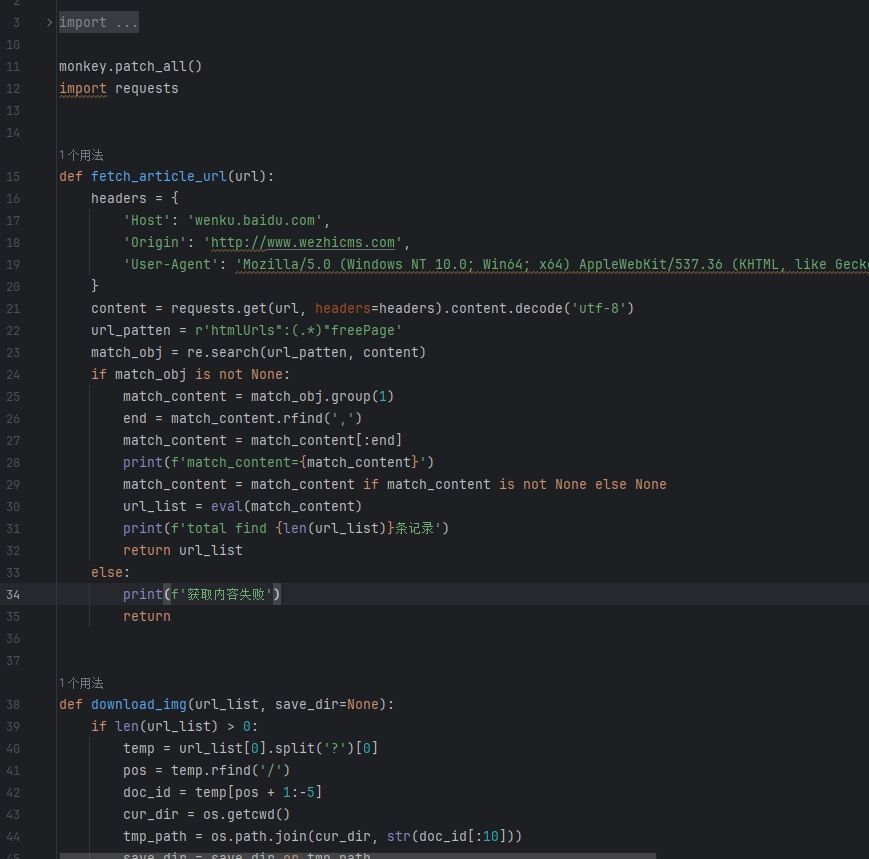
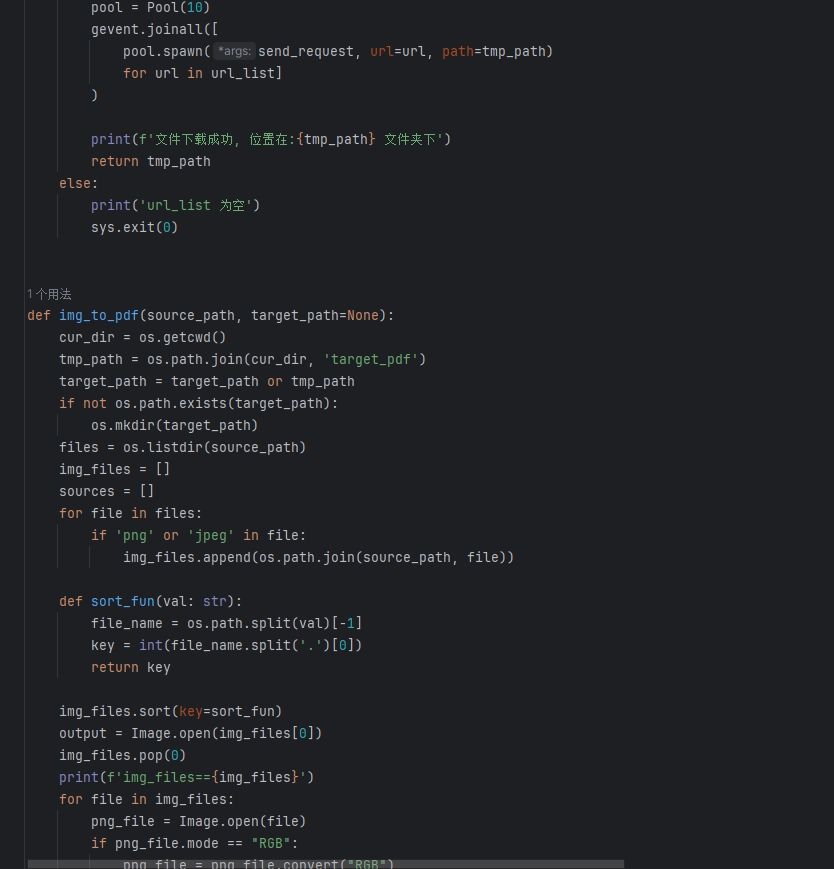
项目简介: 文库作品爬虫是一个用于从特定文库网站爬取作品信息并保存到本地的Python爬虫项目。该项目旨在帮助用户获取文库网站上的文学作品、学术论文、演讲稿等内容,并提供便捷的数据存储和管理功能。
项目特点:
目标网站: 本项目针对特定的文库网站,例如知网、豆丁文库等。
爬取内容: 爬取的内容包括作品标题、作者信息、发布日期、关键词、摘要内容等。
数据存储: 爬取的作品信息可以保存为文本文件、CSV文件或数据库(如SQLite、MySQL等),方便用户进行后续的数据处理和分析。
用户界面: 可以考虑添加简单的用户界面,方便用户输入爬取参数(如关键词、起止时间等)并查看爬取结果。
使用技术:
爬虫框架: 使用Python爬虫框架,例如requests和Beautiful Soup组合,实现对目标网站的信息抓取和解析。
数据存储: 使用pandas库将爬取的数据保存为CSV文件,或使用数据库模块将数据存储到SQLite或MySQL数据库中。
用户界面: 使用tkinter或PyQt等库创建简单的GUI界面,提供用户输入和结果展示功能。
使用方法:
用户打开爬虫项目,并输入目标网站的URL地址。
用户可以设置爬取的参数,如关键词、时间范围等。
爬虫开始工作,抓取符合条件的作品信息并保存到本地文件或数据库中。
用户可以在界面上查看爬取结果,并进行数据处理或导出操作。
案例图片
相似案例推荐
其他人才的相似案例推荐
-

个人中心
个人主页的介绍,h5 小游戏和个人简历介绍等。还有部分作品展
-

Chat-GPT学习笔记
如何通过提问从ChatGPT那里获得高质量答案?请看那些问题
-

和PLC通讯
开发上位机和PLC进行通讯,根据plc下发的指令完成对应操作
-

海宝mes
Mes只能工厂项目的开发,前端vue+后端java一起开发,
-

动物叫声
动物叫声项目 主要用来播放各种动物叫声 集成了海外App
-

全自动化学发光免疫仪
内容: 1.编写仪器(化学发光免疫分析仪)的控制逻辑程序
-

人脸生成器
我的代表作之一是一个人脸生成器,该项目是基于深度学习技术,特
-

智能办公系统
在此智能办公系统中,我担任项目经理的角色。负责整体把控项目进
-

企业微信群批量创建/企业微信自动回复
因客户需求需要大批量创建群模板以方便快速分裂新增企业微信群聊
-

SSC数据上传
此流程主要是数据处理,人工处理需30-50分钟处理数据,且上
-

SSC数据上传
此流程主要是数据处理,人工处理需30-50分钟处理数据,且上
-

网页开发
5.3网页开发 5.3.1发展语言。 - 前端开
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

