
案例介绍
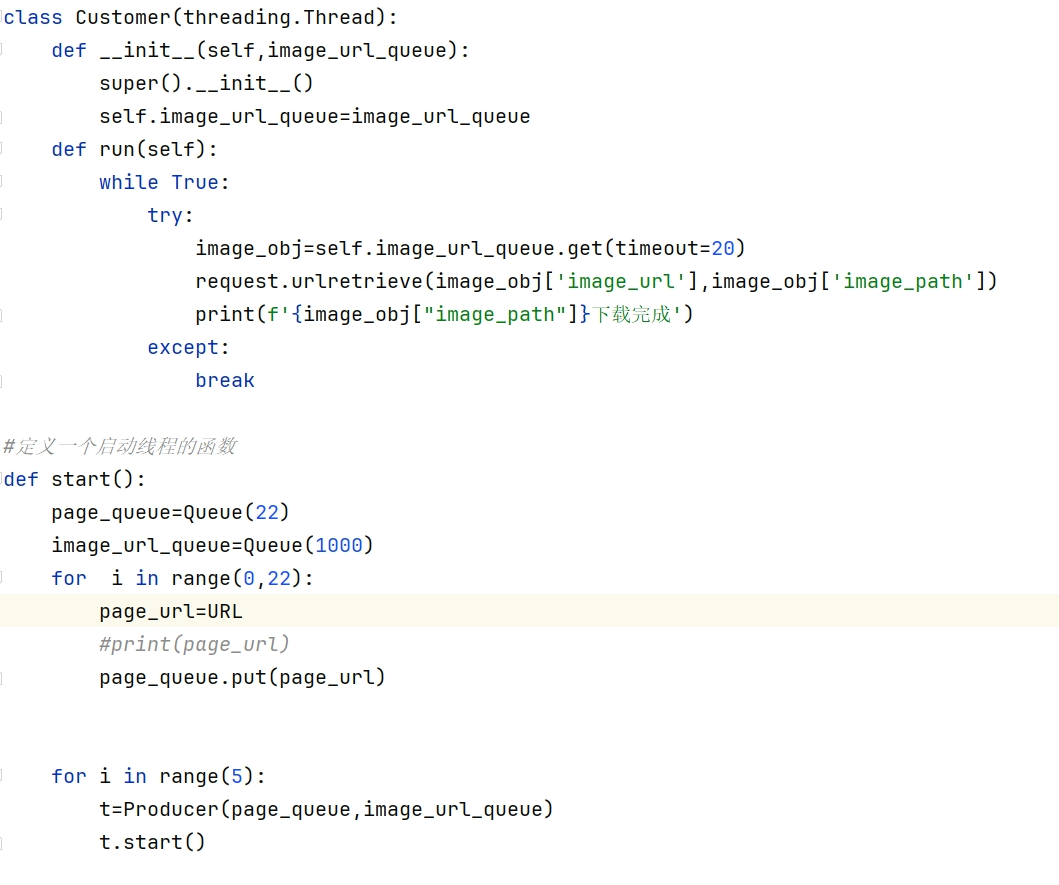
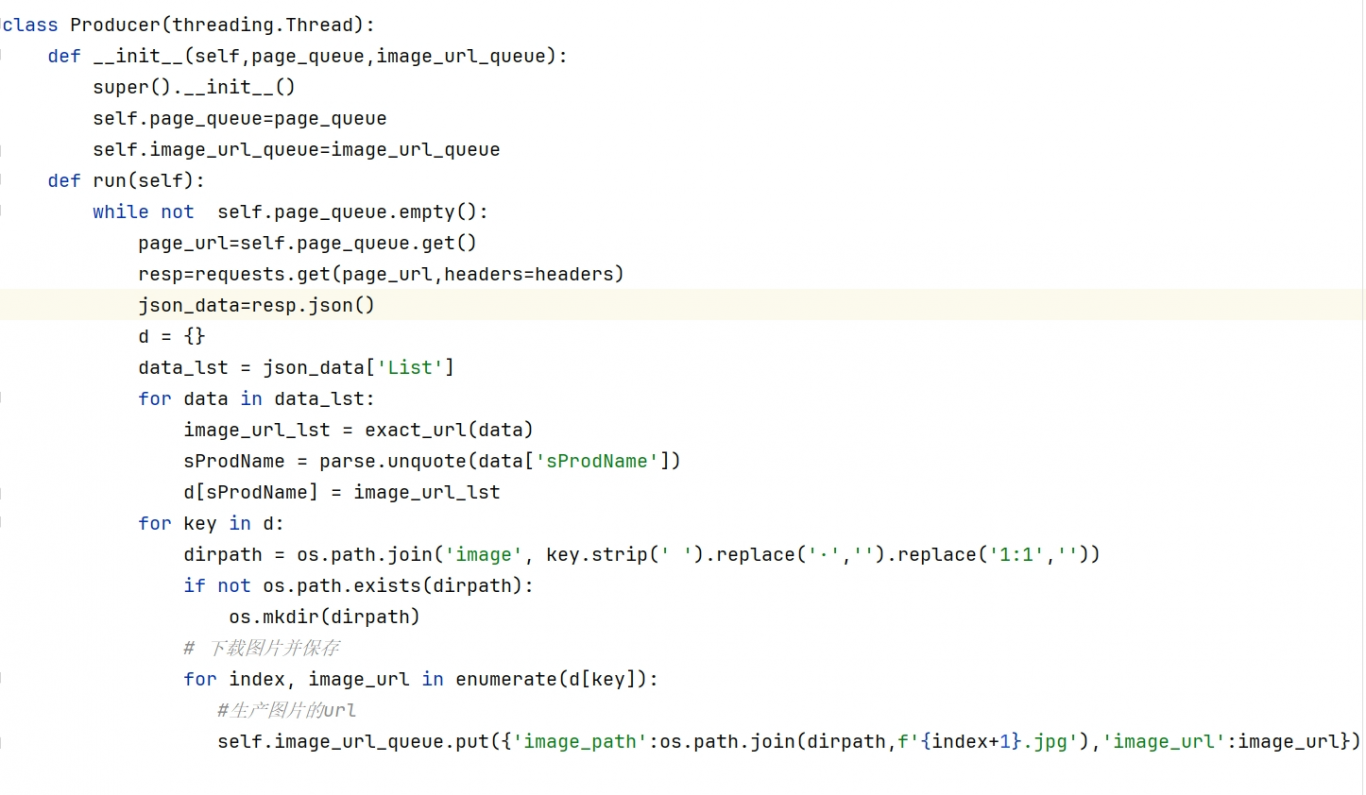
首先,我具备扎实的Python编程基础,能够熟练运用requests、BeautifulSoup等库来编写爬虫程序。通过对目标网站的HTML结构进行深入分析,我能够精准地定位到图片资源的位置,并提取出图片链接。同时,我也非常注重爬虫程序的效率和稳定性,通过合理的请求频率控制和异常处理机制,确保在爬取大量数据的同时,不会对目标网站造成过大的负担。
其次,我具备丰富的数据处理和分析经验。在爬取到图片数据后,我会对图片进行必要的预处理和分类存储,以便后续的分析和使用。如果需要进一步分析图片内容或特征,我也会运用图像处理技术和深度学习算法来提取相关信息。此外,我还能够利用Python的数据分析库对爬取到的数据进行统计分析、可视化展示等,帮助贵公司更好地理解和利用这些数据。
最后,我非常注重数据安全和隐私保护。在爬取和使用数据的过程中,我会严格遵守相关法律法规和道德规范,确保数据的合法性和隐私性。同时,我也会采取必要的技术手段来保护数据的安全性和完整性,防止数据泄露或被滥用。
案例图片

相似案例推荐
其他人才的相似案例推荐
-

某企业的销售和采购业务对账明细报表
某贸易企业用户觉得ERP系统中现有的采购和销售对账单不够用,
-

某企业的销售和采购业务对账明细报表
某贸易企业用户觉得ERP系统中现有的采购和销售对账单不够用,
-

某集团企业的合并财务报表
某集团企业下属20多个子公司,在财务软件中每个子公司有各自的
-

赤兔养车
采用技术: vue3、axios、echarts 项目
-

智慧教育
我负责高新区大屏数据调研工作,深入分析业务需求,精准定位关键
-

智慧天津高新区
我负责高新区大屏数据调研工作,深入分析业务需求,精准定位关键
-

烟草车间信息化平台
车间信息化平台是以工厂MES系统作为基础环境,以MES数据源
-

设备故障信息管理平台微信小程序
为便于对生产设备的故障信息进行统一集中管理,为实现故障信息化
-

建设工程计价、建设工程合同管理平台
工程造价软件也就是工程建筑预算清单计价软件,清单计价是由投标
-

云IDE+开源社区
Cloud IDE 是浏览器版云端 IDE 产品,兼容 vs
-

大屏展示
项目描述:该项目包含大数据可视化一张图,涉及多个模块,共计6
-

公众号H5
项目名称:金融产品管理系统及公众号 项目描述:应甲方需求完
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

