
案例介绍
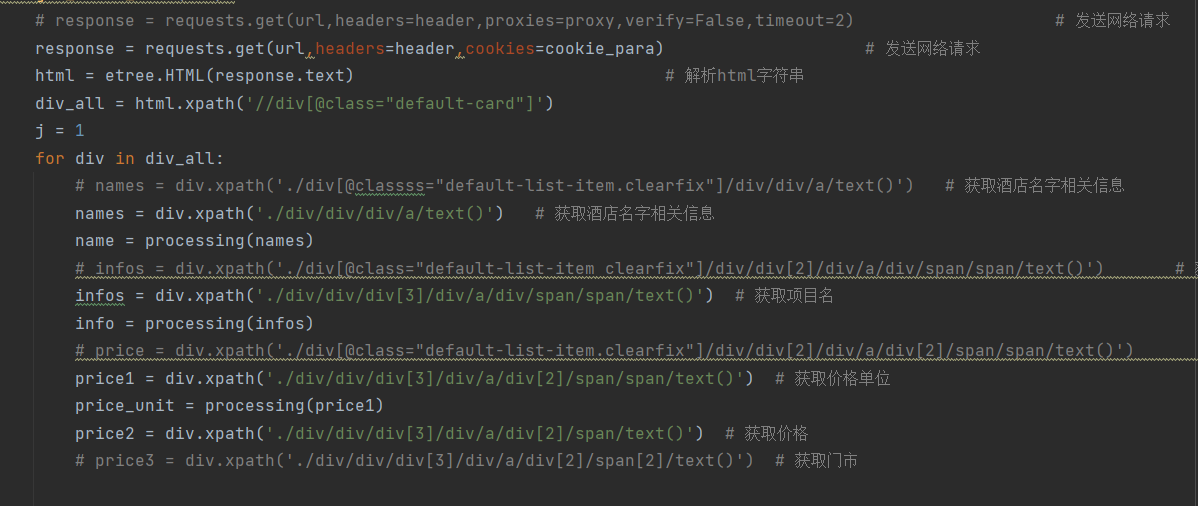
分析了目标电商网站的页面结构,确定了商品信息的存储位置和格式。我发现商品信息主要存储在HTML的某个特定标签内,包括商品名称、价格、销量等。使用Scrapy框架编写了一个爬虫脚本。脚本首先通过requests库发送网络请求,获取网页的HTML源代码。然后,利用BeautifulSoup库解析HTML代码,提取出商品信息。最后,将提取的数据保存到本地文件或数据库中。
案例图片

相似案例推荐
其他人才的相似案例推荐
-

广告监测系统
1. **广告投放监测系统:** 我主导了一个广告监测系统的
-

软件开发、爬虫、数据分析
使用python技术制作成小工具(任何定制)从各种网站和在线
-

前端开发
将客户提供的内容制作成epub、mobi等格式的电子书并使用
-

多相机二维码条形码DM码识别和图片管理
作为生产线上的工具,设置3个镜头对产品进行拍照扫码(DM码)
-

行业管理/会员管理系统网站开发
对平台用户进行管理。类似于店中店和代理模式,总的机构可以创建
-

公交维保系统
公交系统平台 项目介绍: 公交机务系统是重庆公交集团的多
-

房天下超级
本项目一人独自完成,涉及到了逆向和滑块验证dddocr ,d
-

ERP
该项目为公司自主研发的办公软件,用于公司内部进行日常办公使用
-

OA及用友NC
目前就职的公司,主要使用用友NC6.5,U9等产品。包含了人
-

东方物业星
给物业提供问卷系统 web端创建问卷设置内容及可答问卷人群筛
-

数据清洗
这是一个多元线性回归模型的结果,使用了对数变换的自变量和因变
-

模型建立
我曾从事Python程序开发辅助工作,其中包括一项数据建模项
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

接收人才推送

联系需求方端客服