爬取豆瓣热映上的电影信息

案例介绍
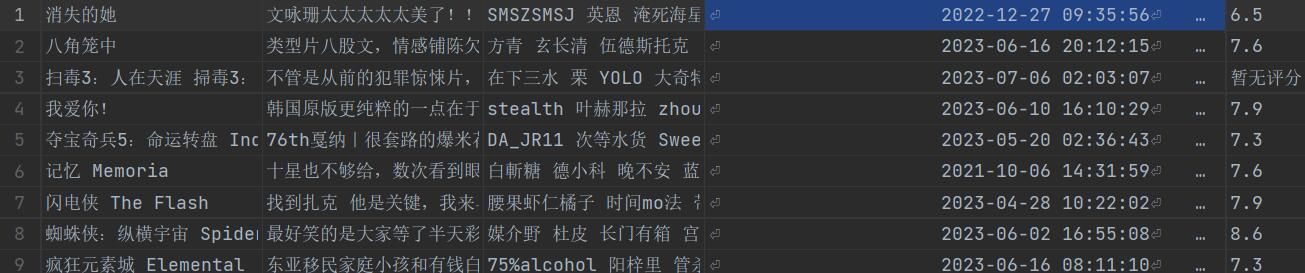
通过使用Selenium库来模拟浏览器操作,访问豆瓣电影网页,并点击“全部正在热映”按钮,进入热播界面。然后,使用XPath解析网页源代码,获取热播电影的链接地址,并将地址保存到data_href列表中。DATA(href)函数通过遍历href列表中的电影链接地址,使用requests库发送GET请求获取电影页面的源代码。然后,使用lxml库的XPath解析功能,提取电影的相关信息,包括电影名称、评论、评论作者、评论时间和评分。将提取的信息以列表的形式保存到data_movies列表中。最后,使用csv库的writerow()方法将每行数据写入CSV文件。
案例图片

相似案例推荐
其他人才的相似案例推荐
-

炉温曲线的优化设计
在回焊炉电路板的焊接生产过程中, 使回焊炉中的各个部分保持生
-

高压油管的压力控制
燃油发动机在现实生活中有着广泛的应用,而燃油进入和喷出高压油
-

农商行履责记实
项目描述: 该系统采用spingboot+mybatis+
-

农商行营销平台
项目描述: 该系统采用spingboot+zookeepe
-

永辉数据采集
项目经验 新闻采集系统 •这是一个专门针对新闻这一类网页
-

饿了么数据采集
•App项目:负责美团,饿了么,拼多多,永辉超市等app的逆
-

大语言模型微调与rag应用
利用网络爬虫构建数据集, 导入论文集完成向量化,构建本地LL
-

智慧云平台
“智慧云平台”是针对电器销售、售后服务行业的专业管理云平台,
-

厂家工单信息抓取
利用爬虫技术,实时获取各家电厂家下发给售后服务商的工单,支持
-

主数据码平台项目
主数据码平台项目: 本项目主要是为了将数据快速生成不同的一
-

主数据管理项目
主数据管理平台: 系统主要有模型管理、规则管理、数据发送、
-

后台管理项目
色彩风格操作风格全全自己设计,将各个后台管理项目集中一处练习
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

接收人才推送

联系需求方端客服