
案例介绍
我曾完成过一个基于Scrapy的淘宝信息爬虫项目,旨在从淘宝网站中抓取商品信息以供进一步分析和应用。以下是该项目的主要介绍:
**1. 目标与需求分析:**
- 确定爬取的目标是淘宝商品信息,包括商品名称、价格、销量、评价等。
- 制定爬虫的策略,如设置搜索关键词、选择商品分类等。
**2. Scrapy爬虫架构设计:**
- 使用Scrapy框架创建项目,并定义Spider,设置起始URL和爬取规则。
- 利用Scrapy的Item定义数据模型,明确需要抓取的字段。
- 制定Pipeline,用于数据清洗、存储或进一步处理。
**3. 页面解析与数据提取:**
- 通过XPath或CSS选择器定位目标页面的各个元素,如商品标题、价格、销量等。
- 处理页面的动态加载,可能需要使用Selenium等工具模拟用户行为,确保获取完整的信息。
**4. 反爬虫处理:**
- 设置合理的爬取速度,避免对目标网站造成过大压力。
- 使用随机User-Agent和代理IP等手段,降低被封禁的风险。
**5. 数据存储与导出:**
- 利用Scrapy提供的Pipeline将爬取到的数据存储到数据库中,如MongoDB。
- 实现数据导出功能,生成CSV或JSON文件,以便后续分析使用。
**6. 定期更新与扩展:**
- 设置定时任务,定期更新商品信息,保持数据的实时性。
- 可以考虑扩展爬虫,爬取更多的商品信息或关联信息。
**7. 文档与测试:**
- 撰写清晰的文档,包括项目结构、爬虫使用方法等。
- 进行充分的测试,确保爬虫在不同情况下的稳定性和可靠性。
这个淘宝信息爬虫项目展示了我的Scrapy框架应用能力、对反爬虫机制的处理经验以及数据存储和导出的实践经验。
案例图片

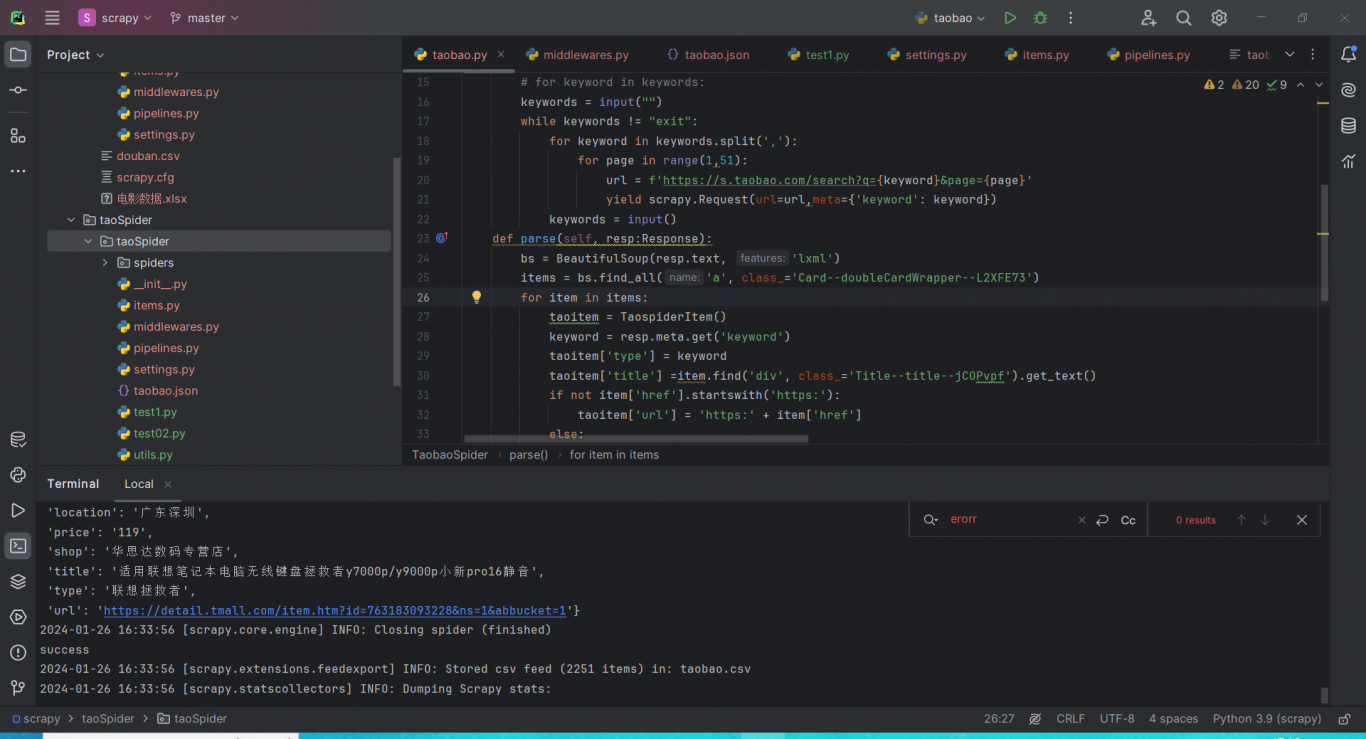
相似案例推荐
其他人才的相似案例推荐
-

数据开发
1. 采集并 ETL 各种数据源的数据,如 Mysql、Xm
-

软件案例
项目:汽车 VCU 控制器的开发 项目内容:使用 ETA
-

某外资银行数字可视化平台
我曾在汇丰银行担任服务提供商一职,这段时间里积累了与全球团队
-

订餐小程序
这个一个小程序,后台框架springboot +maven+
-

鑫海码头智能照明系统
这是码头照明系统的智能管理平台,主要是springboot项
-

索德项目管理系统
项目介绍:该系统是一套用于管理项目的软件或工具集,旨在帮助项
-

python爬虫
该程序功能为对付费类图片网站进行批量图片爬取,在编写中使用了
-

前端网页设计
该项目为前端个人网页设计 在该项目中使用了前端三件套的技术
-

广软小圈
项目描述:此项目是一款在线校园小程序,学生可以绑定学号查询校
-

通过chrome插件集成数据爬取功能
1. 获取目标网站的要获取数据; 2. 模拟请求,并请求接
-

数据平台
内容: 项目背景:面向数据分析师、数据开发、业务开发等用户
-

数据平台
内容: 项目背景:面向数据分析师、数据开发、业务开发等用户
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

