
案例介绍
对国际物流来说,其单证种类繁多、同类单证版式多样、单证内容复杂,业务变化快,前前后后涉及上百种的单证处理工作。而且货物运输途径多个国家地区,货物经手多家公司,同类单证中混杂着多种语言、格式还不统一。随着业务的扩张发展,单证的复杂程度仍会持续上升。
上述的实际业务场景对智能文档识别技术提出了更高的要求,通用算法遇到这些情况效果会大打折扣,如何在复杂情况下保证识别准确率成为业界亟待突破的瓶颈。
相关的难点特征:
第一,混合多国语言
由于在同一页文档中经常出现多国拉丁字符混合、如英语西班牙语、英语德语、英语法语等非常相近的字符文字和语言的混合,这对于文档字符识别和语义识别,自动分类、信息准确抽取会造成很大的挑战。
第二,特殊字段解析
智能文档识别不仅是一个OCR文字识别的问题,更是一个语义理解的问题。对于国际物流文档,经常需要将大段收发货人描述中精准解析企业名称、地址、税号、邮编等字段,同时要求能够支持全球地址和特性字段,是NLP技术面临的难题。
第三,不规范复杂表格
国际物流单据上经常需要对批量货物进行描述,商品名称,海关编码,毛重,体积,包装形式和数量。多类型的字符信息经常需要在跨行跨列的不规范混合子表场景下要做到信息项目的准确数据结构还原,目前还没有特别成熟的通用技术方法。
第四,多场景、多任务交叉
对于国际物流跨公司跨实体的信息流运作过程,往往需要对多种表单整合识别、比对,最后形成确切的指令流程,这就需要在多场景的文档识别理解需求中建立起背后的行业知识图谱的支撑,才能有效完成批量任务级别高精准的实际业务落地。
以上这些问题和挑战都需要新一代的OCR和NLP多模态深度学习并结合领域知识图谱的应用形成更为智能的文档识别技术来解决,最终实现消除繁琐低效的手工数据输入、肉眼信息核对、大幅降低运营管理成本、提升服务响应能力的国际物流产业服务升级目标。
智能文档识别技术作为人工智能应用中商业推广落地较快的领域,正成为人工智能新基建落地应用的“头雁”,已成为人工智能新基建对外提供的重要智能化服务能力之一。人工智能融入实体经济的过程,也将为智能文档识别产业生态引入丰富的人才、技术、场景等要素。
案例图片
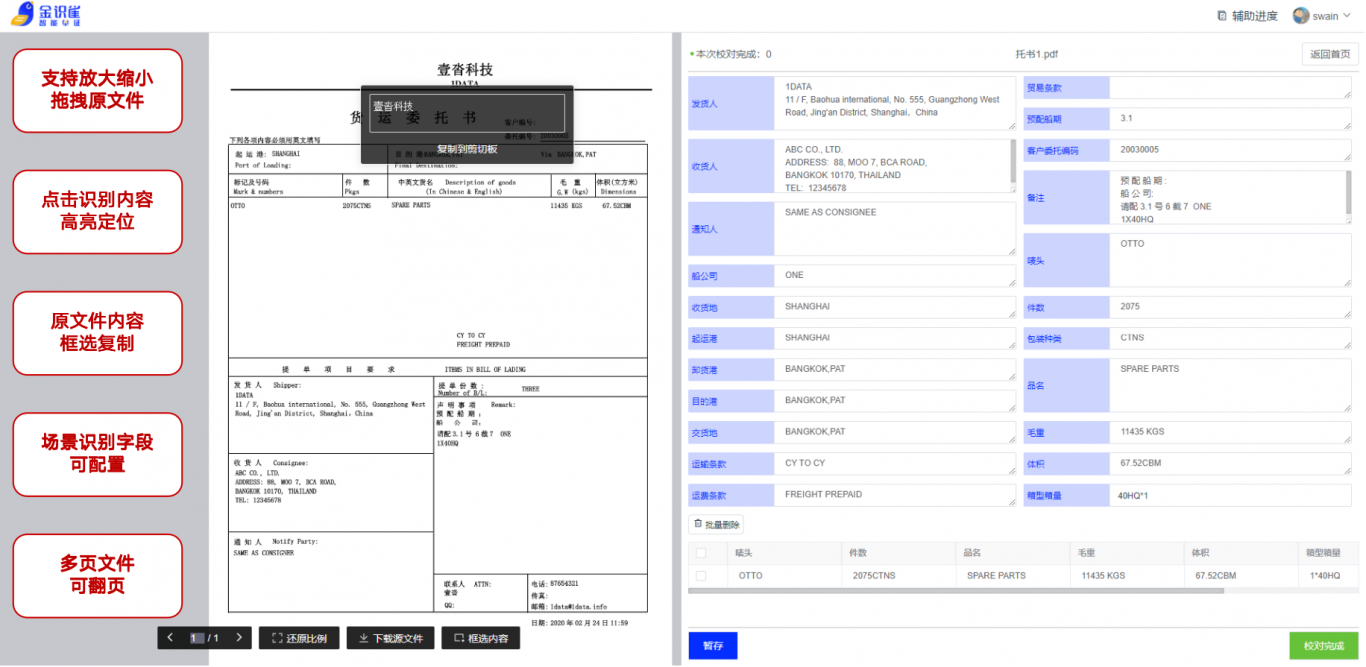

相似案例推荐
其他人才的相似案例推荐
-

国家基础地理信息中心官网
负责后端Java代码编写,针对需求对CMS管理系统进行针对性
-

中国长城遗产门户网站
负责后端Java代码的编写以及CMS内容管理系统的定制化修改
-

集团客户管理系统
主要为中国移动县市分公司开发集团客户管理系统,包含集团客户信
-

嗨,汉朔管理平台
嗨,汉朔管理平台 简介: 产品立足于集成公司各项业
-

宽带系统
1.系统监控:通过切面统计注入开发,记录用户登陆相关日志。
-

运维系统
1.用户模块包括用户的注册,管理,用户权限管理等。 2.字
-

Dynamics365 erp
1.主要负责 Dynamics365 Finance and
-

erp
由于客户所属行业不同,供应商类型不一致,需分散在多平台管理客
-

MES系统
mes系统,记录整个产品由下单-评审-生产制造控制和质量控制
-

MES系统
MES(生产实施管理系统),参与系统的业务需求分析、开发、部
-

云枢-低代码平台
云枢是一款与阿里云深度融合的专有云产品,集成了私有云产品的及
-

东田邻里中心
一款提升邻里生活便捷的小程序, 主要功能是宝宝服务(午饭托管
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

