
案例介绍
利用扩散模型算法进行由文本到图像的可控的图像合成,能够有效降低计算机工作的资源消耗和负担并提升图像合成的可控性和生成效率。而目前已经研究成熟的主流的图像合成方法通常是采用GANs网络进行生成,在传统图像合成方法中使用对抗学习的方法,对空白的“噪声画布”进行“真假判别”,然后学习填充生成;在基于扩散模型的双阶段图像合成的方法中同样也包含一个由密集噪声图逐渐填充合成图像的过程[8]。这种密集的扩散过程常常带来问题:
1.产生大量的近似噪声图以来后处理;
2.大量计算资源损耗的问题;
3.区域设定的超参数问题。
4.模型生成较慢,无法像GANs,VAEs一样,只能一步一步地生成。
本文在已有的研究成果上,针对现有的问题主要进行了以下内容的研究:
1.Diffusion Models的数学原理。通过网上已有的扩散模型论文(期刊)对扩散过程和逆向扩散过程的原理进行研究,并对其中的数学公式进行逐步推导,作为后期扩散模型代码实现的基础。
2.扩散模型前沿算法模块的研究。阅读近年关于扩散模型的研究型论文,对新提出的模型的各个模块算法学习。
3.基于pytorch的图像扩散算法和网络模型的研究
实现图像的正向扩散和逆向扩散。利用python和numpy,对图像的正向扩散(由图像转为噪声图像)过程进行复现。
实现图像的逆向扩散过程。利用python和pytorch,构建网络模型,并基于网络模型和数学原理实现逆向的扩散过程。
4.基于CLIP的text-to-image的条件算法研究。通过CLIP模型算法解决文本的稀疏性,并将文本特征向量映射到图像中完成定向的约束。
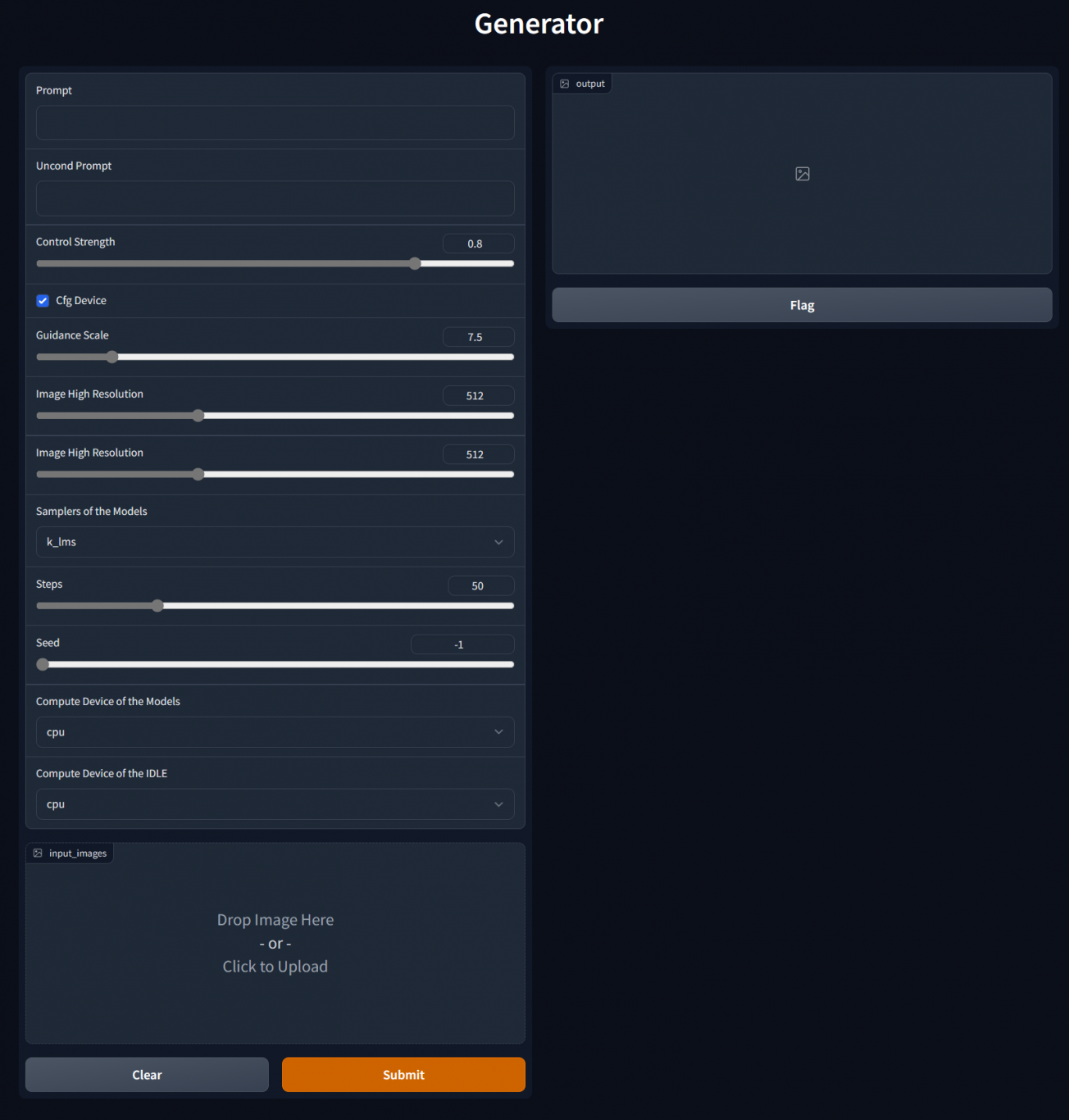
基于DDIM的图像生成系统的实现。将以上的模块和其他涉及的模块进行封装并通过前端页面的形式呈现。
案例图片


相似案例推荐
其他人才的相似案例推荐
-

文献检索系统
1)通过大数据收集文献资料,录入数据库中,形成文献资料库;
-

光伏MPPT项目
如图第一张和第二张是光伏MPPT驱动板子硬件原理图和PCB图
-

激光器驱动电源
前两张为激光器驱动电源的硬件部分原理图以及对应的PCB图,最
-

智慧农业
主要担任需求分析、数据库设计、后端平台的搭建、后端功能的开发
-

数字人平台
使用SpringBoot架构整合Mybatis可持续框架,该
-

数字人平台
使用SpringBoot架构整合Mybatis可持续框架,该
-

智能搜搜
ai聊天软件,现在只有pc端后续会陆续加入绘图,生成视频等一
-

元宇宙
11维空间”是基于UE4虚拟引擎开发的3D沉浸式数字世界,运
-

基于口罩人脸识别多平台签到系统
本文研究的内容是基于深度神经网络FaceNet算法和YOLO
-

商业隐私
因开发项目主要为政府类项目,并且多为内网才能访问,涉及隐私,
-

商业隐私
因涉及项目均为政府类项目,并且多为内网才能访问,涉及隐私故不
-

校园app点餐
这是一款校园点餐app独立开发 支持一卡通、扫脸支付、离
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

