
案例介绍
多模态AI(绘图、语音等)-搭建、接入和集成
多模态AI能够实现基于文本、语音、图片、视频等多模态数据的综合处理应用,完成跨模态领域任务。
1. 文本: 实现多轮对话、上下文记忆等功能,提供了多种选择的模型,包括GPT-3、GPT-3.5和GPT-4等,以满足不同需求。
2. 语音识别: 通过接收语音消息并回复文字或语音,支持多个语音模型,如Whisper、Azure、Google等,以提供准确的语音识别服务。
3. AI绘图: 利用简单的描述生成图片,提供了多个模型选项,包括Stable Diffusion、Replicate等,以实现快速而精确的AI绘图能力。
快速搭建: 轻松使用多模态AI,快速构建应用。
接入: 集成到现有项目中,提升智能处理能力。
集成: 定制化集成多模态AI,实现高效、准确的数据处理和应用。
通过多模态AI,实现文本、语音和图像的智能处理和应用。我们提供高质量、灵活的解决方案,满足您的多模态AI需求。
搭建、接入和集成多模态AI,为您的业务带来智能化和创新的机会!
案例图片


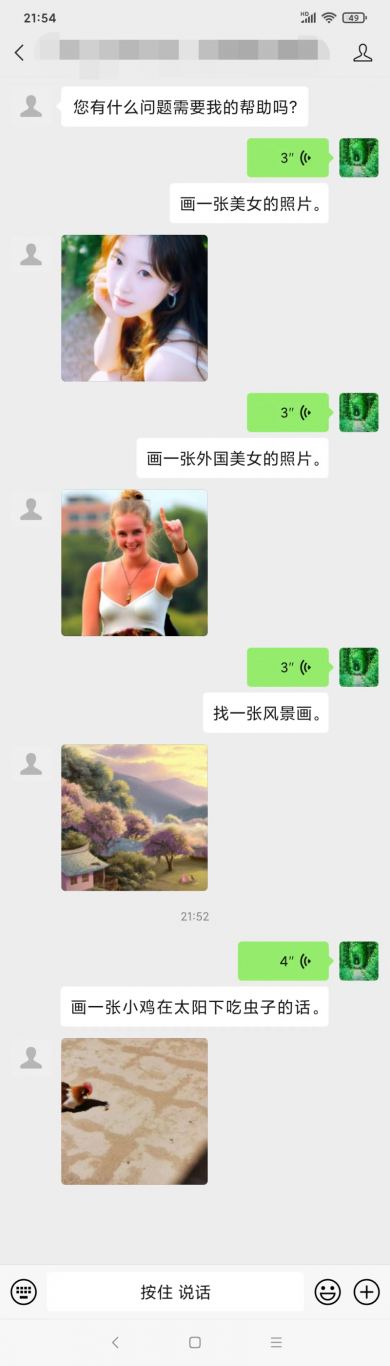
相似案例推荐
其他人才的相似案例推荐
-

智慧交通
统计片区内所有的路口,路口下的设备类型,路口单日流量数据以及
-

文件识别
选择上传文件、例如图片、可以提取到图片中的内容、并做对应的展
-

以图搜图
通过选择对应的图片进行图片的搜索、可以设置图片相似度,展示对
-

AI助手工具箱
该小程序由我独立完成。该项目是一个微信小程序,用户可在本小程
-

张家口光伏扶贫电站智能运维管理系统
项目涉及技术 :spring boot、Vue、elemen
-

省管新一代信息管理系统
国家电网为了更好的实现对员工信息化管理等工作,开发的信息化系
-

小程序商城
商城小程序 基本功能都有 商品展示 购物车 分销商 积分
-

小程序商城
商城小程序 优惠券 产品展示 产品分类 积分商城 快递物流
-

人脸识别服务
人脸识别服务,通过深度学习训练出模型,并部署在Android
-

爬取抖音直播间用户
爬取抖音卖房直播间的隐藏用户个人信息,可以添加他们主页好友,
-

智能聊天助手
项目后端技术采用go语言编写,使用了第三方web框架gin,
-

卫星测控软件开发
精通vue2,vue3也是有4个项目经验,使用logicfl
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

