
案例介绍
1.项目背景
需要实时更新上述两个网站最新披露的数据,两个网站存在很多可用信息,爬取量大,时效性要求较高
2.技术手段以及实现思路
a.考虑数据量大,主要为结构化数据,使用mysql数据库,pymysql便于操作,代理池proxypool提供代理数据避免ip封禁b.针对两个网站的项目,建立两个scrapyproject,两个项目实现思路一样。考虑以后会新增其他数据需求,start_requests里面使用主域名。针对不同数据需求分析页面,在生成的新请求里面调用不同的parse函数
c.设置异常处理情况,遇到异常时,记录异常信息保存到本地便于后期分析,setting里面注释钓默认的中间件
d.以上架构综合考虑了反爬虫机制,易于修改代码后增加后期数据需求,容错机制等
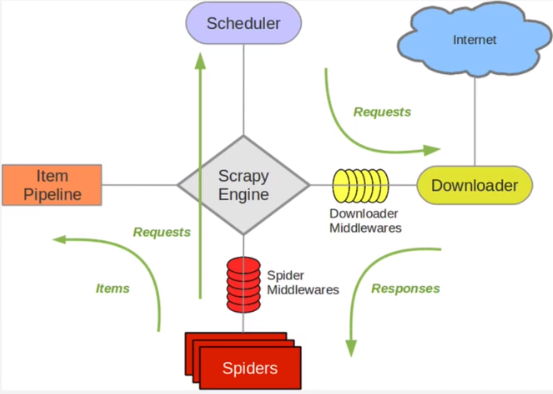
案例图片

相似案例推荐
其他人才的相似案例推荐
-

某省政府采购网招标项目采购项目爬虫
使用python及第三方库对某省政府采购网招标项目采购项目爬
-

低代码开发
建议低代码实现业务流程。 使不会编程的人也能轻松制作页面和
-

监控系统
主要功能包括:系统监控、服务器监控、中间件监控、日志监控、日
-

某大厂B端业务
负责某大厂后台数据分析业务,能够从海量数据中(每天千亿级别日
-

SCRM平台
项目描述: 1. 需求阶段: 根据公司目标、⾏业动态、客
-

研发管理系统
管理内部软件项目的立项、变更、发版、归档,包含用户管理、部门
-

OAM分布式事务自助服务
项目二:OAM分布式事务自助服务 开发环境: Intel
-

基因注释库项目
项目:基因注释库项目 开发环境: IntelliJ ID
-

西安地铁智慧运维系统
西安地铁智慧运维系统,主要对地铁设备维护,工单管理,地铁设备
-

制造采购产品线数据报表
1.Flink采集的离线实时业务库数据,相同mysql业务库
-

融锋运营管理平台
项目描述:融锋科技主营电子保函服务。基于大数据的企业电子保函
-

全景画像
全景画像是平安特殊资产管理业务使用的查询客户的一款数据分析工
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

