
案例介绍
项目名称: 基于爬虫和大数据的结合
开发周期: 3个月(2023-2-2023-3)
项目描述:
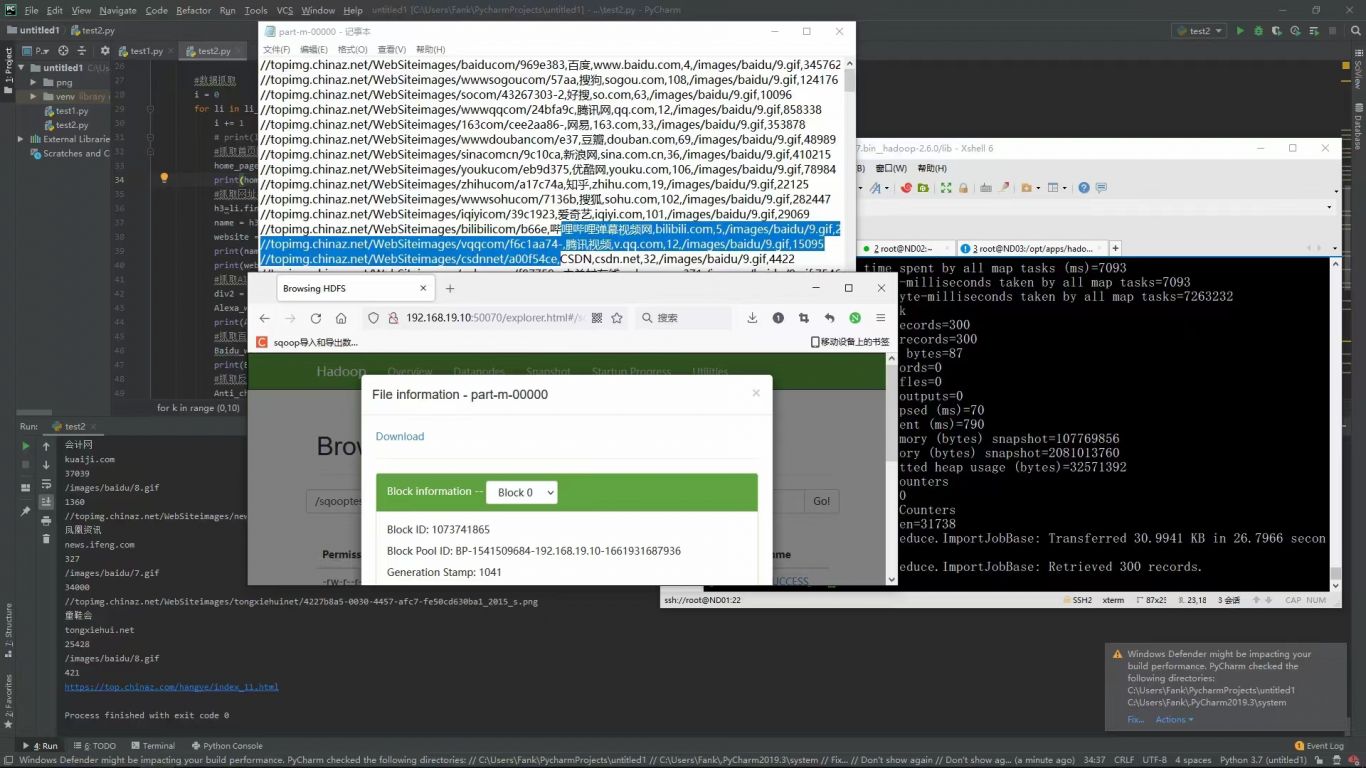
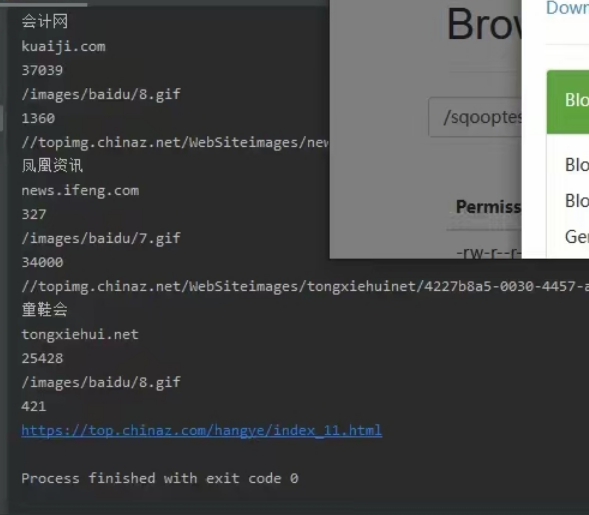
爬虫将数据导入到mysql数据库中,通过sqoop将MySQL中的数据导入到Hadoop的hdfs中,Hadoop集群运用hive进行sql数据库查询,使用hdfs将数据存储在节点,并实现提取出用户留存率,日创建用户和日活跃用户,用户地址,各个年龄段的用户。通过一系列的数据筛选,提取,转换来调查用户需求,来描绘用户画像。
项目架构: Mysql + Sqoop + Hadoop +python爬虫
技术实现:
1. 使用爬虫将爬到的数据传入mysql里面。
2. 使用Sqoop将MySql的业务数据导入HDFS,将原本就保存在本地的了日志文件导入到HDFS
3. 使用Sqoop将MySql的业务数据导入HDFS,将原本就保存在本地的了日志文件导入到HDFS
3.使用SparkCore/SparkSql对数据进行清洗,最后将数据存到Hdfs,映射的到hive表;
3. 创建ODS、MI、DWD、WT、DIM、TMP层;
5. 将数据进行图表展示,发送给运营、产品、测试、管理层。
案例图片
相似案例推荐
其他人才的相似案例推荐
-

剧在小程序
剧在是一款与观剧相关的小程序,主要功能有搜购票、购买周边商品
-

威动智能影库
APP需配套威动智能影库v10等硬件产品使用 1、云端
-
")
mgtv-ODIN(频道服务)
全平台媒资中间件: 频道及点播基础数据服务 角色: 频道开
-
")
mgtv-LDV(播放计数)
全平台播放计数服务(视频点赞, 视频点踩, 播放次数累加/查
-

斗笠江湖游戏宣传视频
使用UE5为手游斗笠江湖制作的游戏买量宣传视频,甲方提供部分
-

小象直播elelive
小象直播elelive这款软件中有着非常多热门的直播资源,用
-

熊猫直播
秀场直播是以高颜值主播展示才艺为主的竖屏直播(星颜)和横屏直
-

ELK日志收集、分析系统
跟踪开源社区的热门项目elasticsearch。 在部门
-

自动化视频合成工具
这个工具是给一家做自媒体公司合成视频使用,在2023英雄联盟
-

聚合爬虫多功能检索软件
互联网视频音乐游戏小说等的整合爬取功能 卡密的核销与分发管
-

爬取豆瓣网站电影信息
通过python爬虫(requests)爬取豆瓣影视网站获得
-

爬取豆瓣网站电影信息
通过python爬虫(requests)爬取豆瓣影视网站获得
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

