python网页制作

案例介绍
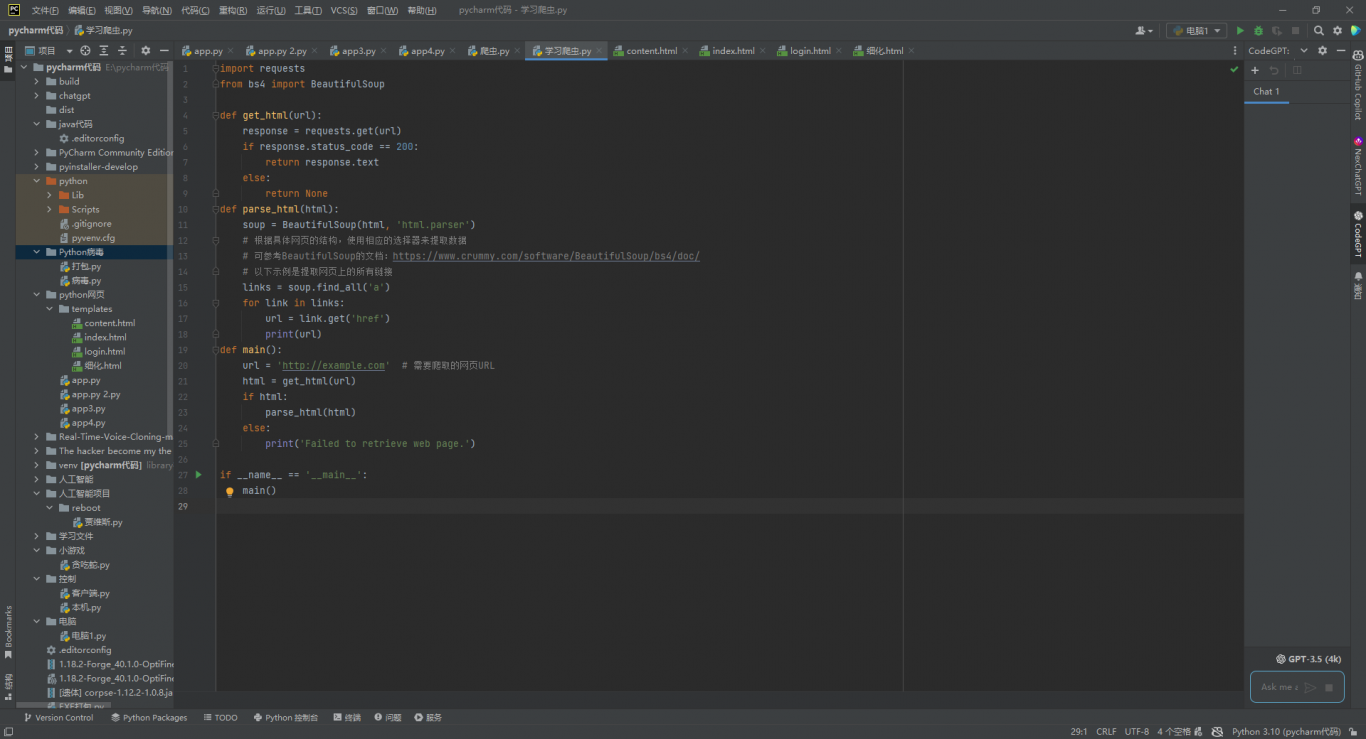
import requests
from bs4 import BeautifulSoup
def get_html(url):
response = requests.get(url)
if response.status_code == 200:
return response.text
else:
return None
def parse_html(html):
soup = BeautifulSoup(html, 'html.parser')
# 根据具体网页的结构,使用相应的选择器来提取数据
# 可参考BeautifulSoup的文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/
# 以下示例是提取网页上的所有链接
links = soup.find_all('a')
for link in links:
url = link.get('href')
print(url)
def main():
url = 'http://example.com' # 需要爬取的网页URL
html = get_html(url)
if html:
parse_html(html)
else:
print('Failed to retrieve web page.')
if __name__ == '__main__':
main()
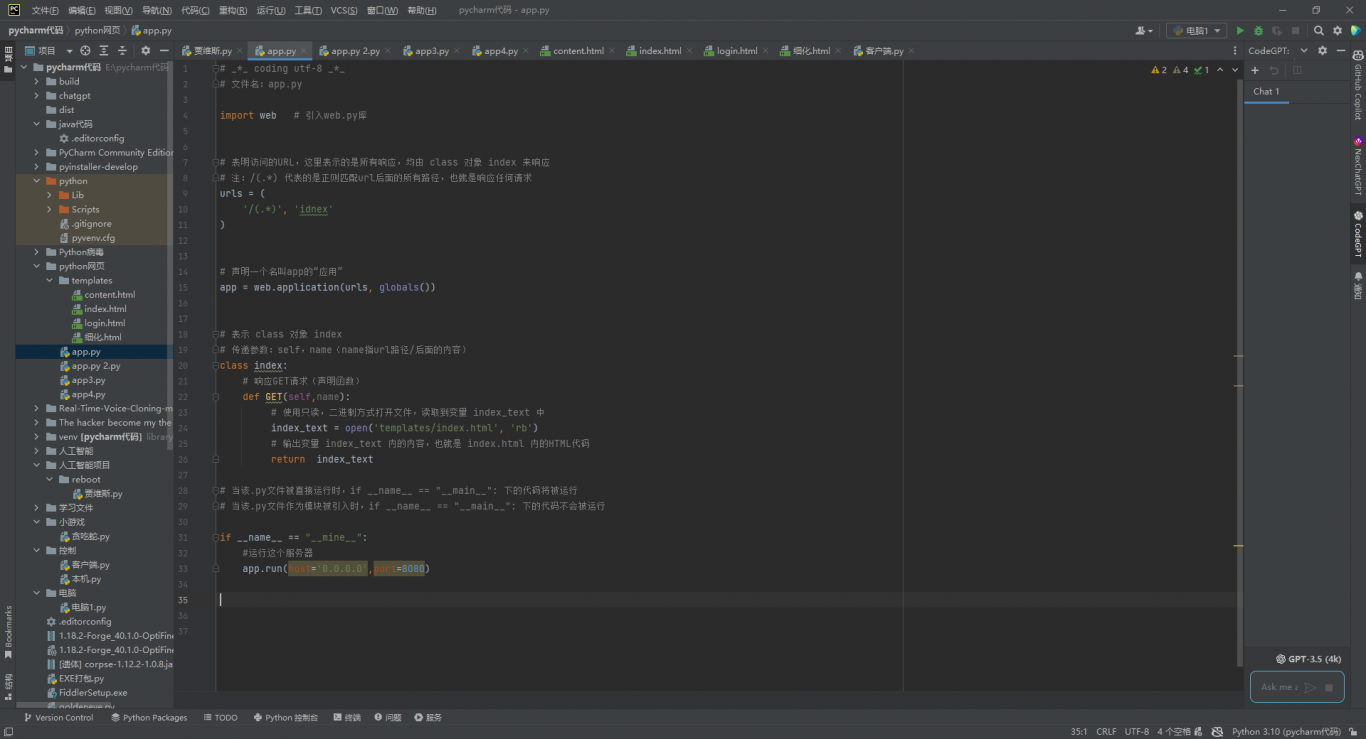
案例图片
相似案例推荐
其他人才的相似案例推荐
-

网易云信
云信短信中心 云信是网易推出的IM技术开发平台,对外提供包
-

OA,ERP,WMS,MIS,小程序
小程序,电商小程序,门店小程序;支持IPAD+APP收银支持
-

智能座舱
推动区域控制器和中央计算单元的功能定义、系统设计、软件开发和
-

某银行容器云基础平台
为银行 IT 部门搭建云基础设施,并开发管理运维平台,提高客
-

Tems
这个项目的整体框架是由我去搭建的,我负责出相关的后端接口,以
-

大数据可视化
后端平台基于湖仓基础应用以及自研高并发、大规模数据分布式存储
-

cmp云管平台
cmp云管平台设计开发。整合openstack、vmvare
-

DTS、DDS
DDS是一款提供公有云全托管MongoDB数据库的NoSQL
-

后园管店
后园管店是一个中后台管理系统,基于 create-react
-

云原生系统架构设计
1、将传统的单体应用迁移到云原生架构,以实现高可用性、弹性伸
-

后台开发
旨在建立一个综合的开发运维平台,用于支持应用程序的开发、测试
-

华为产品数字化项目
暂无具体数据展示,在该项目中主要负责项目管理以及开发,带6人
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

接收人才推送

联系需求方端客服