
案例介绍
利用scrapy框架爬取百度百科网站10000条数据 2023-06至2023-07 代码开发
项目介绍:
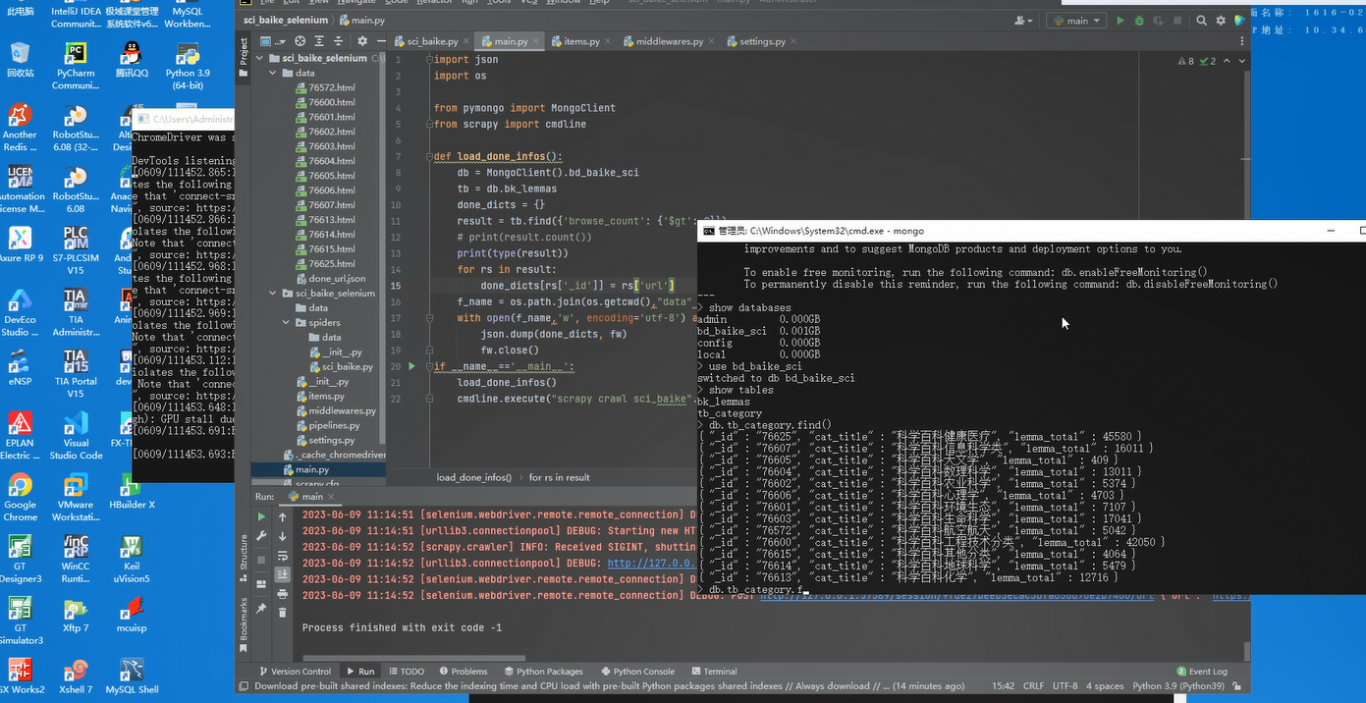
利用python的scrapy框架爬取数据并分别把列表页和详细页存储到mongodb数据库中,并进行数据清洗和可视化输出
项目职责:
在项目中担任主要负责人
项目成果:
为公司提供高效的采集数据
案例图片

相似案例推荐
其他人才的相似案例推荐
-
")
浙江电科院检测管理系统(1到3期)
电网送检项目从入场到离场全过程功能开发 独立单人完成所有功
-

深征信数据抓取
地址:https://webapi.cninfo.com.c
-

全国建筑市场监管公共服务平台数据
监管局数据采集 地址:http://jzsc.mo
-

影刀&简道云开发
1.在公司独自负责影刀对各大电商平台的脚本开发 2.在外企
-

安易采
安易采是一款专门面向政府采购询价调查提供海量数据支撑的大数据
-

知图平台
在项目经验中此项目已有体现,如:下载,富文本,视频打点,权限
-

雷速体育信息抓取
标题:雷速体育信息爬取 地址:https://www.
-

类型网站同步操作
假设在网站A手工执行某个操作、工具自动在同类型的N个其他网站
-

中国机电招标管理系统
背景: 招标信息管理系统对业务流程的全覆盖管理,重
-

永洪BI
永洪BI内嵌了多种分析功能。通过子报表,分组计算表,交叉表,
-

某市智慧工地监管系统
1)工人实名制系统管控工人、班组、工人合同、工人考勤; 2
-

某省诚信系统
建设整个省建筑业企业的诚信体系目标。建筑企业诚信一体化建设管
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

接收人才推送

联系需求方端客服