
案例介绍
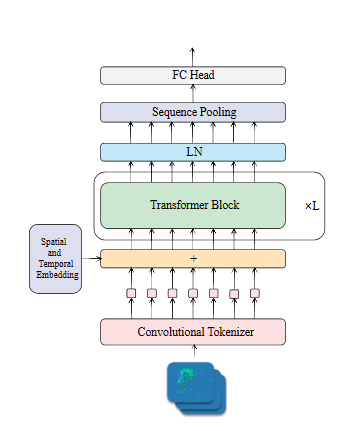
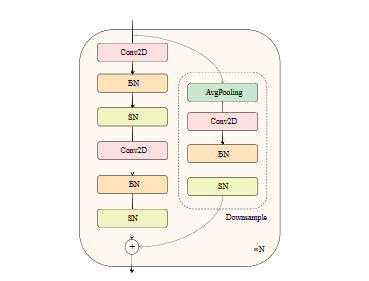
- Convolutional Tokenizer (CT) 模块,它可以将输入图像或视频转换为一系列的token,作为Transformer的输入。这个模块可以提高模型的数据利用率和训练稳定性。
- Spatio-Temporal Attention (STA) 模块,它可以在Transformer的每一层中同时考虑空间和时间维度的信息,从而更好地捕捉脉冲信号的特征依赖关系。
- Spikeformer Encoder,它是一个由多个STA模块堆叠而成的编码器,可以对token进行多层次的特征提取和融合。
- Spikeformer Decoder,它是一个由多个STA模块堆叠而成的解码器,可以对编码器的输出进行进一步的处理和分类。
案例图片
相似案例推荐
其他人才的相似案例推荐
-

后台管理系统
项目介绍:独立开发的基于 vue+mysql+express
-

废钢料堆及抓钢机三维展示项目
程序开发引擎采用的是Unity 2020.1.0f1 (64
-

基于深度学习的边缘提取
基于深度学习模型完成对目标边缘细节的提取,相比较于传统的si
-

基于深度学习的边缘提取
基于深度学习模型完成对目标边缘细节的提取,相比较于传统的si
-

基于Sam的图像标注工具
基于Sam模型可以快速完成对样本的标注,完美支持roi区域的
-

数字城市
这是之前在青岛学校做的毕业项目(水印没去) 这个项目主要是
-

标注平台
标注平台:多边形语义分割等 提交校验 CDS系统角色分为
-

城市AI中枢系统
算法相关的后台管理程序的集成,包括AI中枢管理系统 主要作用
-

重大危险源管理系统
在本项目中负责重大危险源所有后端的开发工作。具体到上传下载导
-

巡察系统
在此项目中主要进行后端系统的开发,用户添加问题推送至需要完成
-

巡察系统
在此项目中主要进行后端系统的开发,用户添加问题推送至需要完成
-

知心购cms管理系统
该项目是对于知心购商品和订单的管理,用户角色的管理,对应商品
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

