
案例介绍
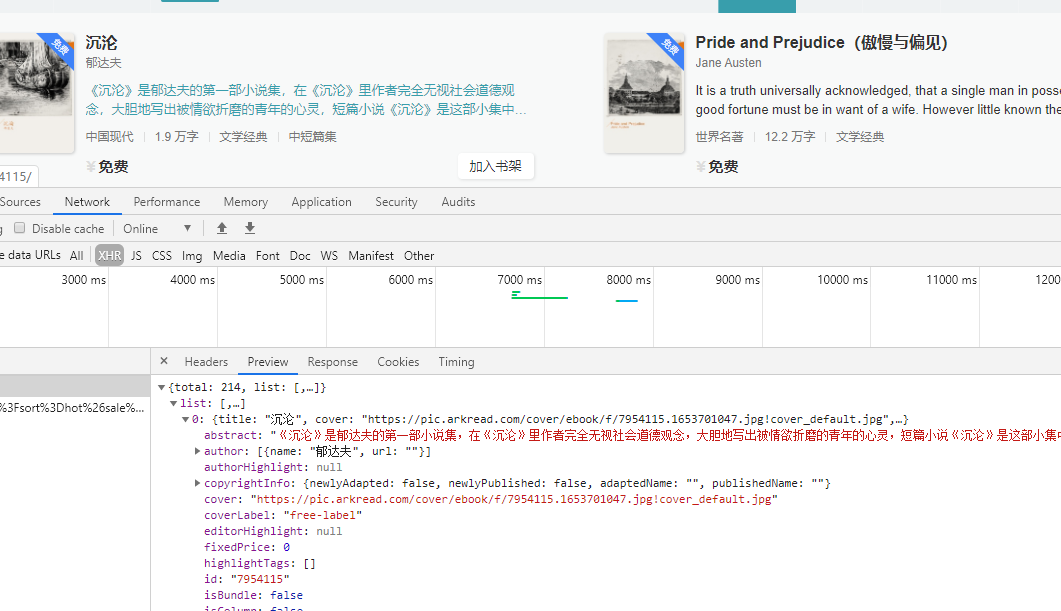
项目描述:爬取各个大型图书网站,如新华书店图书网,在线网上图书一号店等。获取它们图书的名称,简介,购买量,评
论量,评论数据,价格等,存入数据库。
项目技能:requests,Xpath,json,Redis,MongoDB ,协程,re
项目职责:
1.使用 requests 模块,发送 http 请求,使用协程进行爬取网页,提高爬虫效率
2.分析需要爬取的数据,发现在 ajax 请求中,数据格式为 json 。使用 re 模块在返回的 response.content 中匹配需求数据,获取
到数据
3.自定义 get_ua 函数,,调用 get_ua 随机获取 user-agent ,对 request 对象来进行包装,应对反爬
案例图片
相似案例推荐
其他人才的相似案例推荐
-

PIXIV 插画批量下载器
PIXIV 插画批量下载器,它使用 Python 编程语言、
-

网络漫画下载器
该项目使用 PyQt 和爬虫技术开发的网络漫画下载器。该应用
-

联通邮箱,联通云盘
沃邮箱 项⽬描述 联通沃邮箱APP升级版是中国联通2022年
-

没有作品不知道上传什么啊
百度指数查询工具是择云软件工作室开发的一款可以批量采集百度指
-

视频下载工具
项目需求:由于视频录像机在远程,且视频录像机工具下载不支持定
-

资源发布平台
发布文件和下载文件,独立开发,具体功能有人员管理,权限管理,
-

知识库
项目介绍:是一个以文件储存为核心、更方便更简易的存储库;
-

python和C++下载网页全部内容
使用python或者软件,对一个网页的全部内容进行下载,包括
-

移动云云空间
移动云云空间是以企业协作管理场景为入口,聚合海量应用,助力企
-

MES云计算平台
MES云计算平台只要是将维护好的生产数据包括权限等下发到各个
-

企业云盘
多种存储方式、支持分享文件;单个、批量操作文件、文件夹 在
-

油管自动下载及B站自动上传视频
个人搬运国外优质内容用, 通过python+selenium
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

