
案例介绍
本节详细介绍了推理感知预训练方法以及预训练的模型结构,并设计提出了针对
预训练任务的数字掩盖算法。之后介绍了预训练阶段的模型结构和损失函数,最后在
应用到本文研究任务即结构化数据到逻辑文本生成时提出了两阶段 Prefix-tuning 的方案,
大大减少训练的参数量以及模型的存储开销。
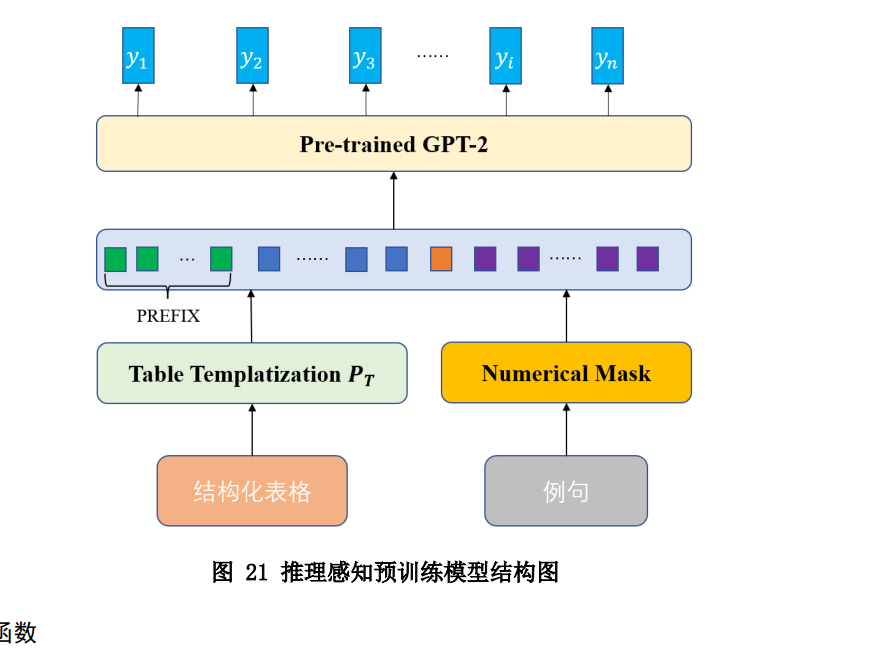
4.2.1 预训练任务
推理感知预训练任务是一项数值预测任务,该任务是经典掩蔽语言建模目标
(Masked Language Model)的变体,但旨在提高预训练语言模型的数值推理技能。该
任务包括输入 C 和相应的输出 D,即目标序列。C 由一对文本序列 C1 和 C2 组成,它
们用特殊字符分隔。C2等同于 D,但包含可从 C1推断出的被掩盖的数字。任务是通过
从 C1 的内容正确预测被掩盖的数字来重构 C2 的原始内容。
案例图片

相似案例推荐
其他人才的相似案例推荐
-

基于深度学习的手势识别方法的实现
项目描述 : 针对移动端设备对于深度学习模型的计算量和模型大
-

爬取各大平台数据
爬取各大平台并进行数据清洗数据去重,对数据进行excel表格
-

爬取各大平台数据
熟练爬取网页合法信息并进行数据清洗数据筛选数据去重,并保存E
-

ICL选片及技术拱高
ICL是一家专注于生物医学领域的科技公司,致力于将人工智能技
-

BMC的FPGA芯片原型验证
主要从事的是FPGA原型验证工作,对amba总线以及pcie
-

无线室内单元
这两张照片作为例子,其中一个可以是全室外单元,接收无线信号,
-

暂无
111111111111111111111111111111
-

暂无
111111111111111111111111111111
-

近邻服务平台
项目主体模块: 1.公告管理:后台公告列表、添加公告、修改
-

贵宾管理系统
航空项目贵宾管理系统 主要功能模块: 1.贵宾管理:安检
-

服务器kvm搭建
x86服务器管理、国产鲲鹏 Arm服务器管理、VMware
-

爱车钥匙运营项目
爱车钥匙平台是一款好人好车开发的与ETC商户运行的平台,涉及
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

