
案例介绍
项目简介:
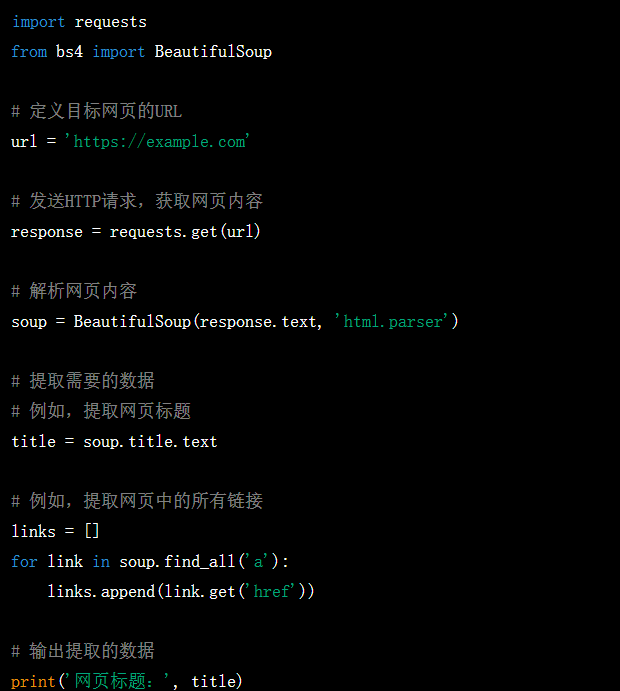
这个项目是一个简单的数据爬取页面,旨在从指定的网站上爬取数据并展示在用户界面上。用户可以输入关键词或选择特定的数据源,然后点击按钮进行数据爬取,并在页面上查看结果。
项目功能:
数据源选择:用户可以选择要从哪个网站或数据源爬取数据,例如新闻网站、社交媒体、在线商城等。
关键词搜索:用户可以输入关键词来过滤爬取的数据,只展示与关键词相关的内容。
数据展示:爬取的数据以列表、表格或其他形式展示在用户界面上,包括标题、摘要、发布日期等信息。
数据详情:用户可以点击数据项,查看详细的数据信息,例如文章内容、评论等。
数据导出:用户可以将爬取的数据导出为CSV、Excel或其他格式,以便进一步分析和处理。
技术栈:
编程语言:Python
爬虫框架:例如Beautiful Soup、Scrapy等
前端技术:例如HTML、CSS、JavaScript等
数据库:例如MySQL、MongoDB等(可选,用于存储爬取的数据)
数据导出:例如CSV、Excel等格式的文件处理库
项目价值:
提供了一个简单易用的界面,方便用户进行数据爬取,无需编写复杂的代码。
支持多种数据源的选择,满足不同用户的需求。
可以应用于各种场景,例如新闻舆情分析、社交媒体监测、竞品分析等。
提供数据导出功能,方便用户将爬取的数据导入到其他应用进行进一步处理。
对于初学者或没有编程经验的用户,可以作为一个学习和实践数据爬取的入门项目。
以上是简单数据爬取页面项目的简介,它可以帮助用户方便地从指定网站上爬取数据并进行展示和导出,具有一定的实际应用价值和学习价值。
案例图片

相似案例推荐
其他人才的相似案例推荐
-

厦门大学校门进出管理
项目描述: 厦门大
-

夏信用卡发布系统
1.根据需求进行评审以及与业务人员洽谈确定需求。 2.根据
-

园林通小程序
园林通 项目简介:园林通是一款专业的园林服务软件,使用方法
-

园林通
园林通 项目简介:园林通是一款专业的园林服务软件,使用方法
-

澳客后台管理系统
使用Vue2+Vue Antd Admin实现后台管理系统。
-

TDM试验数据管理系统+一体机
用于航天电机二级保密单位,对航天电机 自检,压力检测,军检,
-

华为镜像
2015至2021年间,负责华为项目,制作华为全球采购惠普电
-

万豪镜像项目
2016至今,负责万豪酒店集团项目,制作万豪酒店中国采购的惠
-

勤坊众创空间数字化赋能平台
1.根据UI规范结合element完成项目的整体搭建以及布局
-

新疆山洪调查评价应用平台
新疆山洪调查评价应用平台是专门为新疆雨量天气打造的一款实时监
-

新疆山洪调查评价应用平台
使用Element-ui进行骨架搭建和基本布局 使用P
-

mytokencap数据爬取
爬取这个网站的数据,通过抓包找到接口可以发现同样有参数进行了
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

