
案例介绍
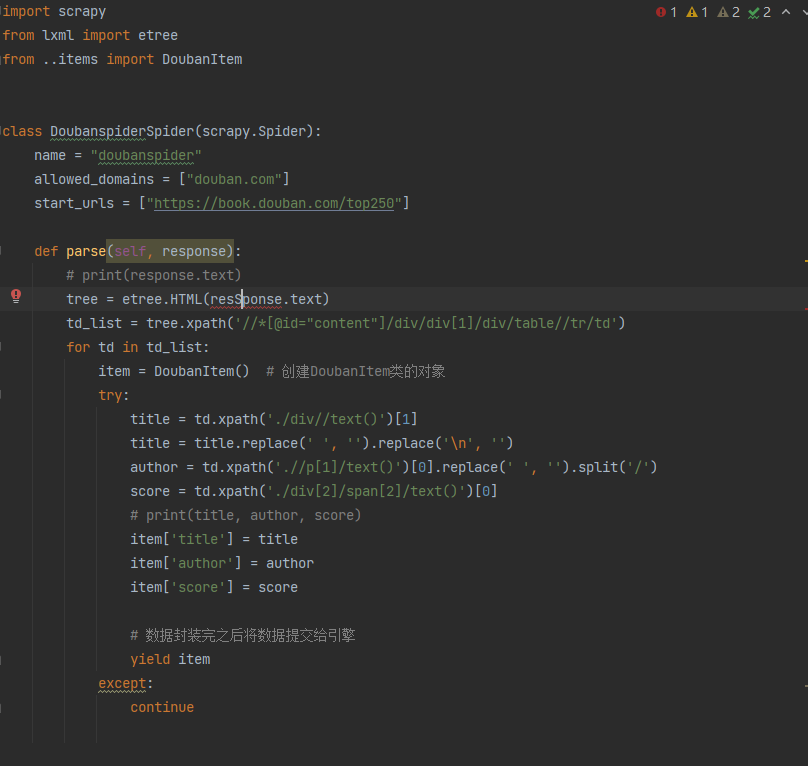
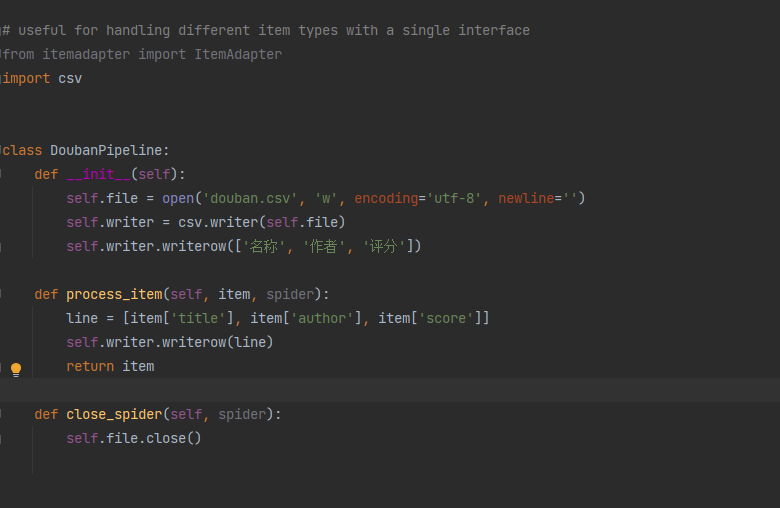
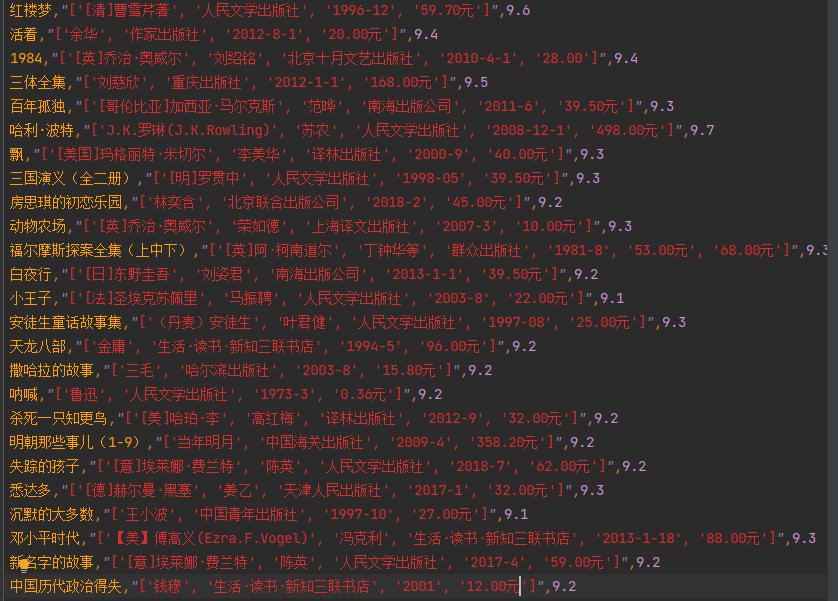
该项目是一个基于Python的网络爬虫应用,旨在获取豆瓣图书网站的图书信息,包括书名、作者、评分、出版社、价格等。
该项目的主要功能包括:
1.网络请求:通过发送HTTP请求,获取豆瓣图书网站的HTML页面内容。
2.数据解析:使用Python的HTML解析库(如BeautifulSoup)对HTML页面进行解析,获取需要的图书信息。
3.数据存储:将获取到的图书信息存储到本地文件或数据库中。
案例图片
相似案例推荐
其他人才的相似案例推荐
-

报告生成
基于数据分析,呈现多样式报告,通过分析多维度指标,一键生成日
-

数据分析
当突发舆情事件时,可以回溯突发舆情事件相关数据信息,宏观分析
-

黄龙资源管理平台
黄龙资源管理平台是对黄龙景区各类资源的统一管理后台系统,主要
-

标注后台管理系统
vue3 + nodejs完成的定制化系统 常用的
-

足彩分析系统python
本套系统为本人完全自主开发系统,拥有绝对的版权。由于对系统的
-

足彩分析系统java
本套系统为本人完全自主开发系统,拥有绝对的版权。由于对系统的
-

音乐爬取
这一款爬虫,里面搜集了几乎所有可以爬取的中文网址,从知乎豆瓣
-

数字化营销官网
LTD营销SaaS 通过“重新定义网站”,帮助企业解决数字经
-

官微名片小程序
这款小程序属于智能化社交名片,创建自己的名片分享给别人后进行
-

电子档案管理系统
该项目通过采用vue框架实现web前端项目的开发,开发内容根
-
智能工厂管理系统")
(MES,WMS)智能工厂管理系统
项目四:(MES,WMS)智能工厂管理系统 (2022.05
-
智能工厂管理系统")
(MES,WMS)智能工厂管理系统
项目三:(MES,WMS)涂料公司管理系统 (2021.10
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

接收人才推送

联系需求方端客服