
案例介绍
NTCIR-16 Real-MedNLP Subtask3 第二名,主要参赛人员
任务描述: 任 从给定的病历报告中,对病历文本中包含的多个疾病和药物的不良药物反应程度进行分类。
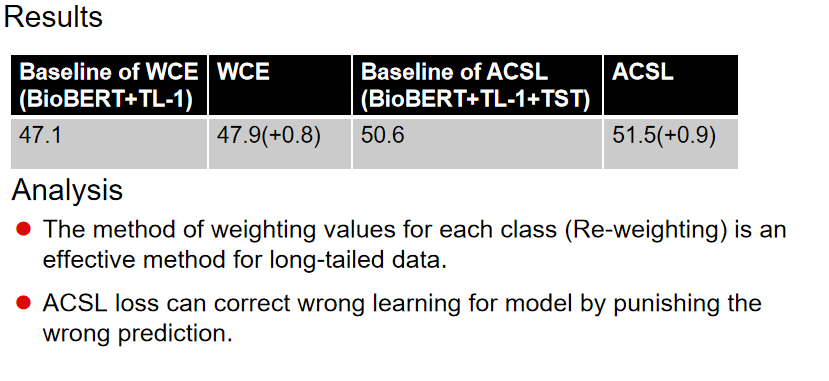
1. 针对样本不均衡(1300+/100-/100-/200-):1.重采样(重复少类样本);2.重加权(加权交叉熵损失、Focal loss
等);3.提出的两阶段训练方法(第一阶段正常交叉熵训练,使模型学习原始数据分布;第二阶段加权交叉熵训练,
消除数据类别比例对模型预测的影响)。
2. 针对数据量较少:第一是课程式学习方法(1.构建一个疾病、药物分类的数据集;2.构建一个完形填空的任务,候选
答案是正确答案以及三个错误答案;任务难度渐进式提升,模型学习一些先验知识);第二是数据增强(EDA以及
Embedding层的数据增强)。
3. 特征增强: 特 通过提示句的形式将疾病、药物对应的类别和属性特征输入到模型中,引导模型学习类别和属性特征。
4. 模型集成 :将训练得到的不同模型进行投票,概率平均等集成方法。
案例图片

相似案例推荐
其他人才的相似案例推荐
-

三维可视化
webgl在线预览
-

数据采集
校区照明控制
-

无无
.net工程师,C#。.net工程师,C#。.net工程师,
-

洛阳鉴定站管理系统
项目所用技术:Vue2 +uniapp+ WebPack +
-

矩阵乘法并行计算优化
项目描述:在Linux下通过修改算法和协调主从核的数据量来提
-

工商调查系统
该项目是国家发改委承办的一个全国企业调查系统,具有查询企业信
-

爬取大众点评商铺地址、评分等相关信息
爬虫:爬取大众点评某个城市某类美食的所有商家相关的有市场价值
-

提取所有股票的信息进行数据分析
爬虫:爬取所有股票的相关信息,主要包括:最新价,涨跌幅、涨跌
-

nuoya
项目概述:从pdf格式的年报中抽取出年报所涉及的公司以及公司
-

盐城海洋灾害辅助决策系统
盐城海洋灾害辅助决策系统主要为盐城自规局实现中国沿海和盐城近
-

南航大型仪器设备共享管理平台
南京航空航天大学大型仪器设备共享管理平台提供仪器设备信息共享
-

港口智能照明系统
本系统是为港口客户提供的智能照明系统客户端服务平台,平台的主
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

