
案例介绍
An Efficient Method of Supervised Contrastive Learning for Natural Language Understanding 第一作者
论文背景 论 :对于文本分类任务,目前主流的方法:预训练语言模型+微调的范式,常常采用交叉熵损失函数。模型输
出置信度在0.5左右的样本,是对于模型分类比较困难的样本。针对这个问题,利用监督对比学习有效地提升了模型
对于困难样本的分类准确率。
• 主要内容 主 :1.通过融合交叉熵损失函数以及提出的监督对比学习损失函数,尽可能地最大化类间方差和最小化类内方
差,提升类别特征区分度。2.通过在隐层状态上的数据增强方法来提升模型训练的鲁棒性,同时增强模型泛化能力。
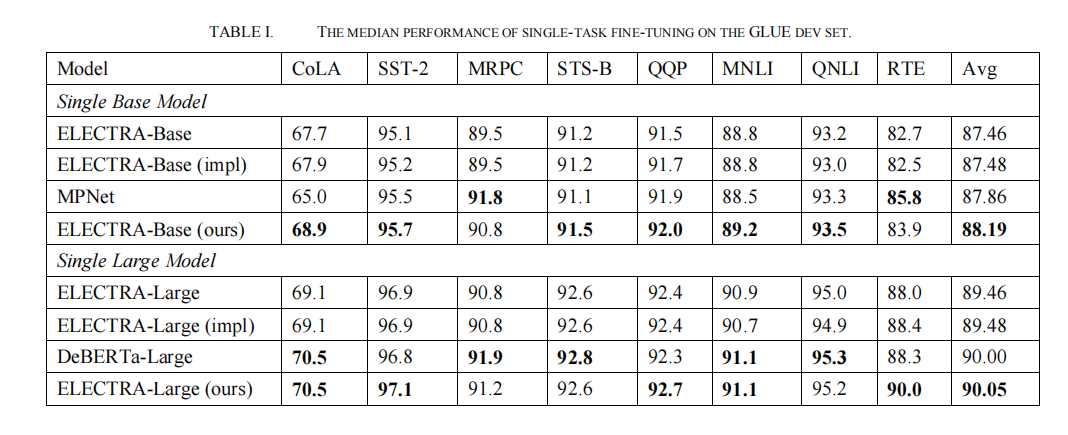
• 实验结果 实 :1.使用ELECTRA模型在GLUE benchmark的8个数据集上均有显著提升。2.与传统的交叉熵损失函数以及
其他的对比学习损失函数比较,在分类效果(tSNE可视化)、泛化能力等指标上,均有更好的表现。
案例图片

相似案例推荐
其他人才的相似案例推荐
-

三维可视化
webgl在线预览
-

数据采集
校区照明控制
-

无无
.net工程师,C#。.net工程师,C#。.net工程师,
-

洛阳鉴定站管理系统
项目所用技术:Vue2 +uniapp+ WebPack +
-

矩阵乘法并行计算优化
项目描述:在Linux下通过修改算法和协调主从核的数据量来提
-

工商调查系统
该项目是国家发改委承办的一个全国企业调查系统,具有查询企业信
-

爬取大众点评商铺地址、评分等相关信息
爬虫:爬取大众点评某个城市某类美食的所有商家相关的有市场价值
-

提取所有股票的信息进行数据分析
爬虫:爬取所有股票的相关信息,主要包括:最新价,涨跌幅、涨跌
-

nuoya
项目概述:从pdf格式的年报中抽取出年报所涉及的公司以及公司
-

盐城海洋灾害辅助决策系统
盐城海洋灾害辅助决策系统主要为盐城自规局实现中国沿海和盐城近
-

南航大型仪器设备共享管理平台
南京航空航天大学大型仪器设备共享管理平台提供仪器设备信息共享
-

港口智能照明系统
本系统是为港口客户提供的智能照明系统客户端服务平台,平台的主
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

