文本图片搜索系统

案例介绍
1. 项目概述
深度学习已经逐步从大模型演化为超大模型,数据源也从单模态向多模态发展,虽然前沿的学术进展较为成熟,各个模态数据之间打通也变得较为便利,本软件旨在解决跨模态数据之间的匹配问题,包括文本到图像以及图像到文本,用户可以直接在本软件平台上尝试多模态搜索的强大能力,也可以基于本平台二次定制化开发,更加贴合实际应用的业务场景。
2. 整体架构
本项目重点解决多模态数据之间的匹配问题,如以文搜文、以文搜图、以图搜图、以图搜文等通用应用场景。用户可以根据自己需求结合到实际业务场景中,比如智能客服场景下,需要根据历史问答库来为用户提问匹配最优答案,这就可以使用本软件的以文搜文功能,还比如前端UI设计师需要从素材库里找到想要的图片素材,这就可以使用本软件的以文搜图功能。
一、以文搜文
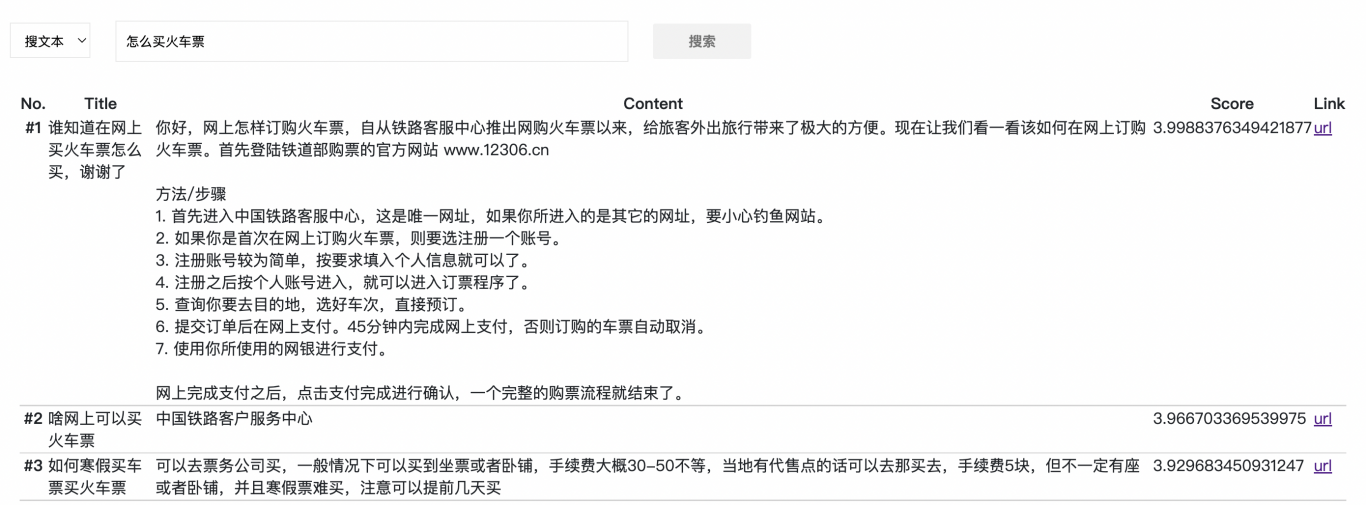
支持用户输入文本,多模态匹配平台会根据用户输入的文本跟百科库中进行语义匹配计算,然后返回用户关心的百科内容。
二、以文搜图
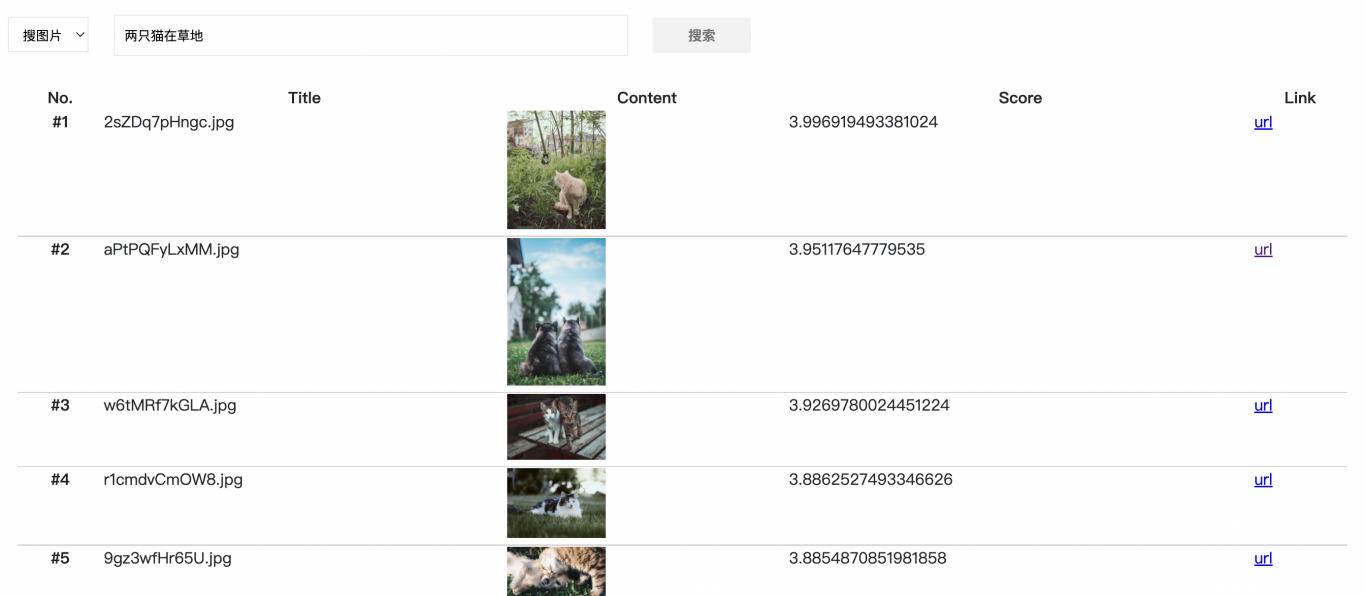
支持用户输入文本,多模态匹配平台会从图片库中进行语义匹配计算,然后返回用户想要查找的图片。
三、以图搜图
支持用户输入图片,多模态匹配平台会从图片库中进行语义匹配计算,然后返回跟用户输入近似的图片。比如输入猫,返回的图片也是猫相关的。
四、以图搜文
支持用户输入图片,多模态匹配平台会根据预先内置的 1000 多个文本标签,来计算用户图片跟文本标签的相似性,然后返回文本标签给用户。
3. 核心贡献
完成以文搜文、以文搜图、以图搜图以及以图搜文等四个多模态搜索模块,每个模块都使用了先进的NLP和CV预训练大模型,并且针对特定应用场景给出了 demo 验证样例,是一套从模型到前端搜索交互的完成系统。
4. 难点挑战
同模态和跨模态数据理解存在着极大的挑战,比如文字描述“狗”和真实图片中的“狗”在计算机理解看来天差地别,我在项目中使用了大规模预训练模型,能够透过数据模态形式来理解背后的语义,进而使得文本和图片之间相互搜索成为可能。
案例图片
相似案例推荐
其他人才的相似案例推荐
-

基于drg的医疗绩效分析
主菜单 病案首页基础质检 DRG入组评估 DRG绩效分析
-

自然语言处理的投标企业信用智能评价平台
企业信用服务平台的建设,数据获取、直至实现数据展示和优化的目
-

百度智能小程序
智能小程序,智能连接人与信息、人与服务、人与万物的开放生态,
-

百度智能小程序
智能小程序,智能连接人与信息、人与服务、人与万物的开放生态,
-

基于多任务学习的阀门空化检测和强度识别
随着智能制造的快速发展,数据驱动的机械健康管理已经受到越来越
-

基于对抗学习的异常声音检测
异常声音检测(ASD)是复杂工业系统中机械设备监测和维护的最
-

Xml编辑工具
开发了Xml编辑工具,支持各类型Xml文件的浏览、编辑、保存
-

Xml编辑工具
开发了Xml编辑工具,支持各类型Xml文件的浏览、编辑、保存
-

暂时没有
暂时没有暂时没有暂时没有暂时没有暂时没有暂时没有暂时没有暂时
-

暂时没有
希望理解希望理解希望理解希望理解希望理解希望理解希望理解希望
-

电梯安装管理
项目描述:本项目主要是为某电梯公司制作一套专属的电梯安装从电
-

全球鹰大屏
项目描述:本项目主要是为某电梯公司提供实时的大屏数据联动展示
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

接收人才推送

联系需求方端客服