
案例介绍
担任角色:负责人与核心开发(共3人)
项目介绍:催收和客服场景有大量电话语音识别需求,阿里云服务调用成本高,并且存在数据安全与专有名词识别效果差的问题,所以自研语音识别服务。项目采用微服务架构,主要包含前处理服务、语音识别服务和加标点服务。
主要职责:
(1) 调研kaldi和wenet框架,最终选择wenet端到端的框架作为语音识别的服务。
(2) 训练语音识别模型,达到上线的效果;实现模型微调,缩短模型的训练耗时。
(3) 优化C++版本的语音识别服务代码,提供语音识别服务。
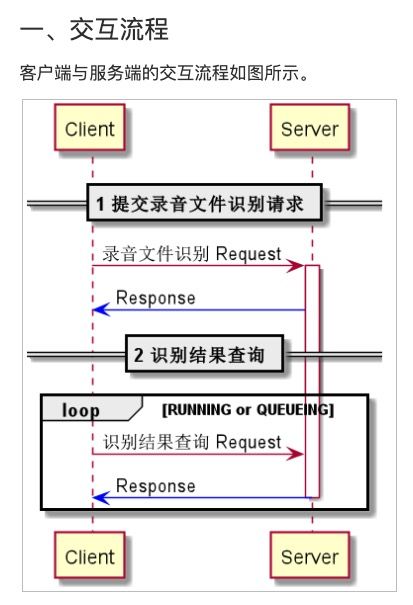
(4) 对标阿里语音识别服务的参数和异步调用流程,使用grpc开发前处理服务,支持音频数据的并发、流式传输。输出接口文档。
(5) 进行单元测试、压力测试、保障性能和服务的稳定性;并解决开发过程中遇到的功能、性能问题。
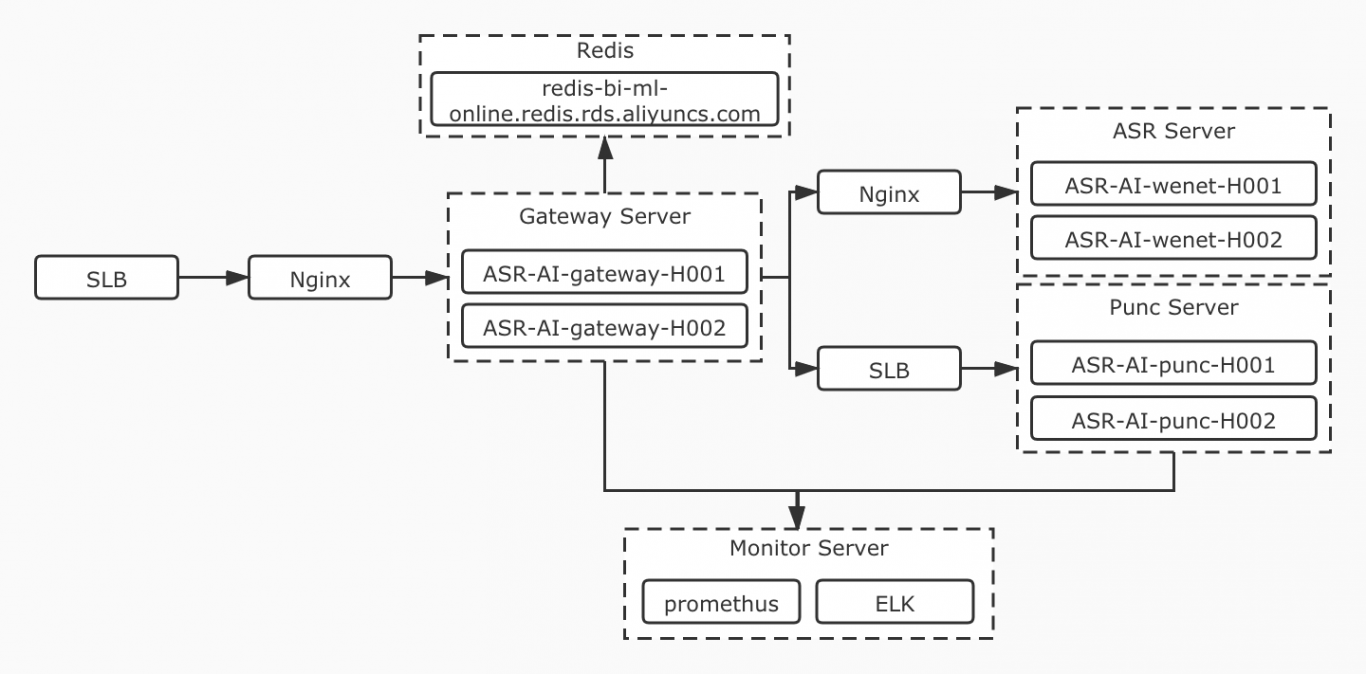
(6) 输出服务日志到ELK平台;并用prometheus、Grafana实时监控服务的QPS、可用性、P99指标。
(7) 使用docker部署服务,Jenkins发布上线,nginx进行负载均衡,搭建高并发高可用服务。
主要业绩:
(1) 经产品测算,使用自研语音识别服务替换阿里云的服务后,每年可节省48万的服务费用。
(2) 目前线上使用的语音识别模型的字错率为5.32%,而阿里云的语音识别服务的字错率为7.29%。
(3) 优化工作:
-- 发现wenet C++版服务代码中的bug: grpc返回的解析结果只有一个。解决bug并提交patch。
---- 相关链接: https://github.com/wenet-e2e/wenet/commit/f54d0ef14901037ad39790bca2df668c1c4d7ab0
-- 模型训练代码中,不支持<unk>标签(unknow),修改代码解决该问题。
-- 解决负载均衡异常的问题:经排查是阿里的SLB对grpc支持不好导致,改用Nginx后解决该问题。
(4) 语音识别服务平台如期上线,目前服务已经稳定运行一年,未出现bug。
案例图片
相似案例推荐
其他人才的相似案例推荐
-

图像人工智能
些项目为内部技术关公的DEMO案例,主要实现图像人功能智能的
-

bus通讯检测
负责复杂前台设计及后台推理算法的实现; 统筹项目组内成员的
-

书籍管理系统
是用Django框架搭建的书籍管理系统,主要实现的是书籍的增
-

厦门景点前20推荐
该作品所涉及的网站是“到哪去旅游”,爬取的是厦门的旅游景点信
-

MES
用于汽车零部件制造业的生产管理,包括工单、工位、巡检、安全、
-

硅钢页面开发
1.Vue.js是用于构建交互式的 Web 界面的库。
-

文字转语音
实现过语音转文字,文字转语音项目,熟悉transformer
-

检测分割关键点车辆识别
熟悉深度学习各种算法,有多年安防行业实战经验,人机非检测,人
-

运维合集
1、参与项目技术方案制定,进行相关的设计和开发工作; 2、
-

JSON自定义解析
一个JSON解析的高级工具,可以自定义一些函数,在JSON解
-

嵌入式设备Android研发
嵌入式设备发射激光线照射到物体表面,Android通过图像识
-

博微易数
专为支撑企业经营决策推出的低门槛、高效率的大数据可视化自助式
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

