
案例介绍
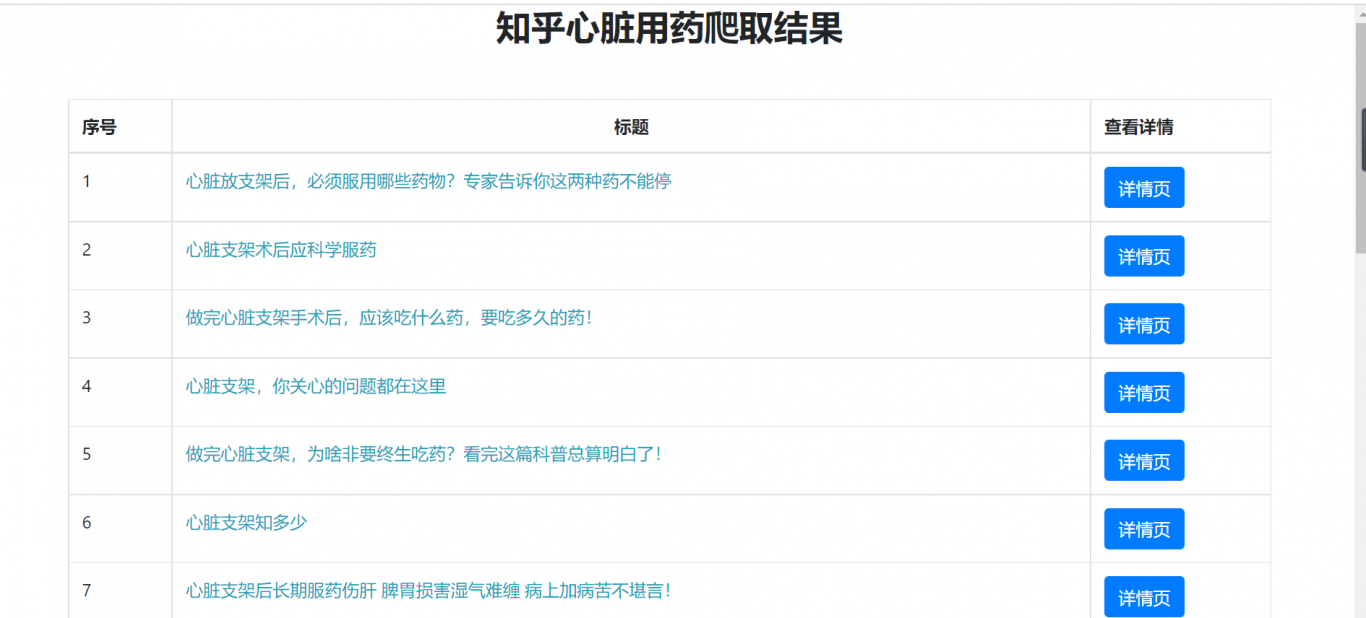
此作品对知乎的心脏用药的相关结果做了一个总结,一共10页,每页20条信息。我是开发者角色,其中我使用selenium的动态网页爬取技术打开知乎网页,然后又使用beautifulsoup进行了页面解析。然后我又使用了前端的vue框架和bootstrap的技术给获取的信息进行了分页处理,在每个详情页又使用了js技术获取下一条或者上一条信息和返回列表功能.
1. 通过webdriver实例化一个浏览器对象【谷歌浏览器】
2.遇到selenium能被知乎识别的反爬问题,使用自己打开的一个浏览器,绕开反爬
再用selenium接管这个浏览器这样就可以完成反爬的处理。
3. 通过urllib模块输入相关问题,然后直接通过selenium,下拉网页到最后
4. 通过beautifulsoup的语法获取相关超链接和标题
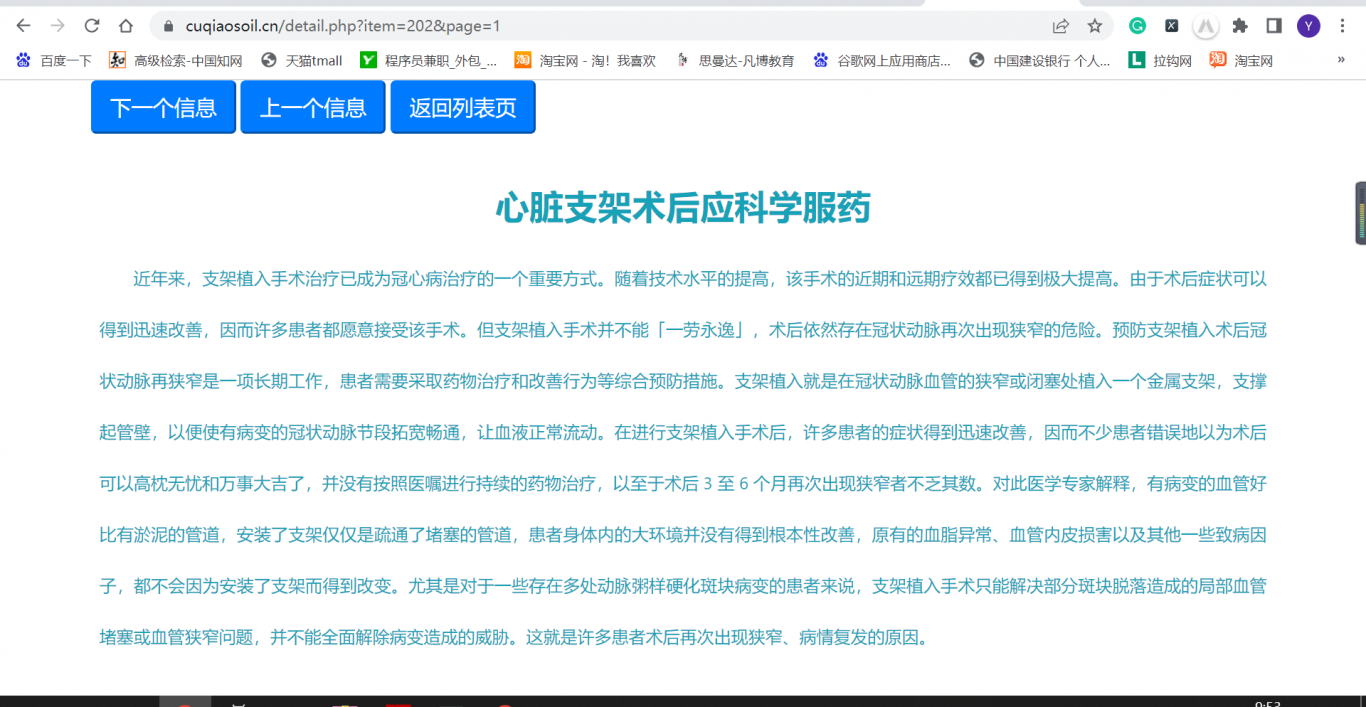
5. 通过requests模块向这些超链接发送请求,然后获取返回页面的源码后用xpath语法获取需要的数据,
然后存入mysql数据库
6.建立前端的vue-cli脚手架,通过bootstrap和vue的相关指令生成前端页面
7.通过pdo和数据库连接返回所需的数据,然后和vue框架进行前后端的交互
8.将相关的vue框架和后端的php文件上传到阿里云服务器
案例图片

相似案例推荐
其他人才的相似案例推荐
-

云芯管家
我的职责:负责个人中心页面及功能,设备信息页面及功能,sim
-

3D应用
负责的角色:前端开发工程师(独立负责) 主要完成项目搭建、
-

trialos
这是帮一个门户网站+产品平台。门户采用ssr做的服务端渲染,
-

客户管理系统
一、样本数据模块 主要是通过网络或者串口接收仪器端发送过来的
-

女性健康类工具产品
女性健康类工具,为用户提供生理健康自检、健康报告汇总、生理检
-

devops部署
1.负责整套流程的搭建和部署。 2.服务部署的高可用。
-

主数据平台
作品详情:统一公司系统公用数据,避免数据重复治理与不一致;
-

慢病购药系统
作品功能: 1. 慢病购药系统。 2. 包括药品列表,药
-

小药箱
作品功能:小药箱是一个H5应用,把药品组合成不同的套餐包的形
-

成研5G隔离探视项目
随着社会的发展,5G与VR技术的高速发展。VR视频通过5G直
-

5G远程医疗项目
为实现医疗机构的远程教学需求,产品面向医疗机构客户,提供集学
-

重金属检测
从环境污染方面所说的重金属,实际上主要是指汞、镉、铅、铬、砷
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

