
案例介绍
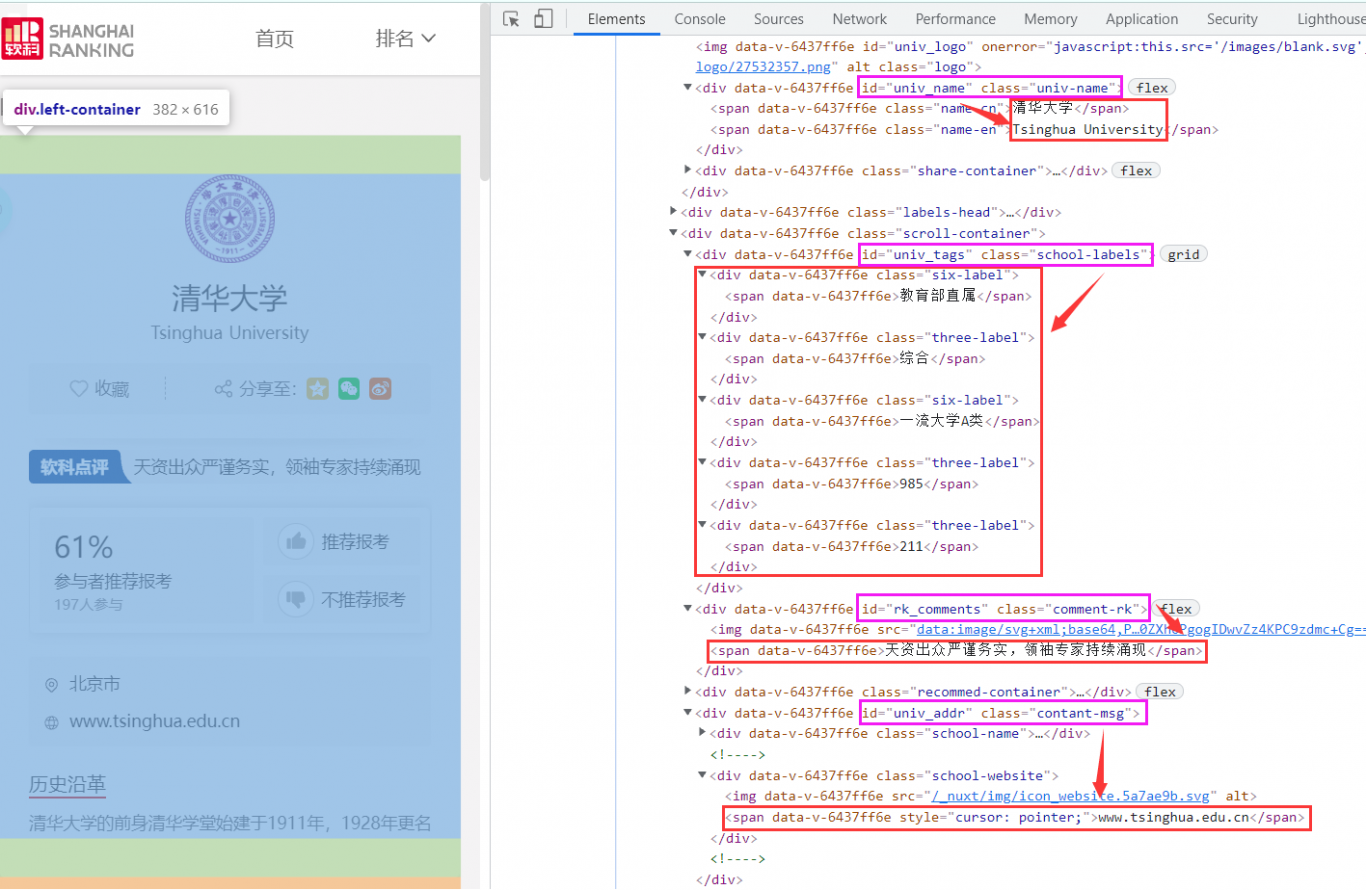
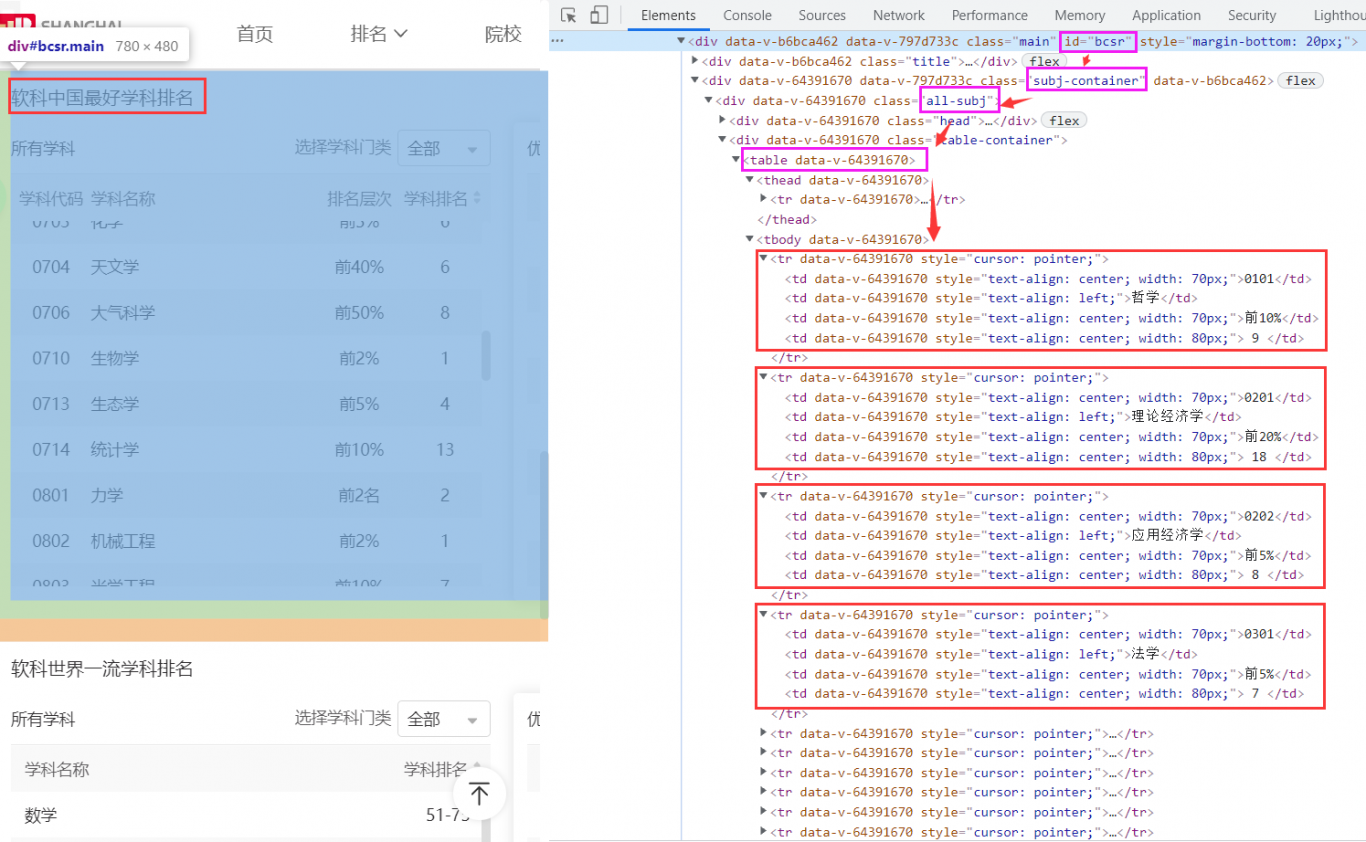
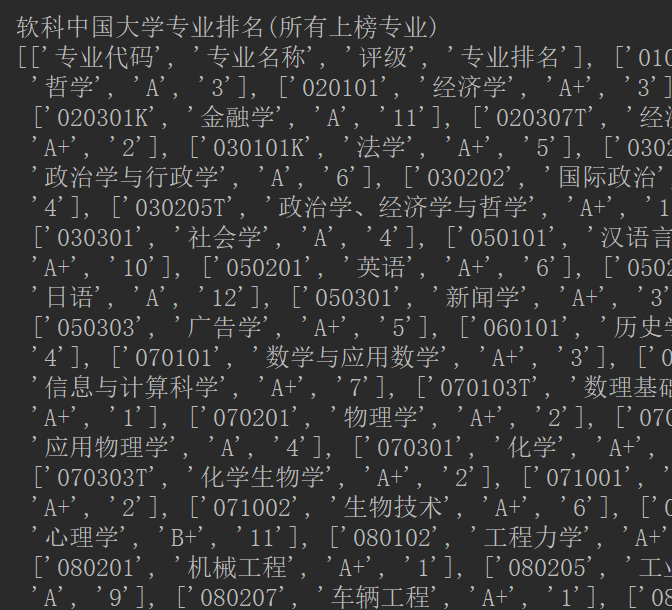
示例1:利用爬虫爬取最好大学网清华大学页面的信息:https://www.shanghairanking.cn/institution/tsinghua-university。主要爬取的内容包括:院校基本信息(学校中英文名称、学校官网网址、学校标签、软科点评)、大学排名、在校生毕业生信息、院校满意度、软科中国大学专业排名、软科中国最好学科排名、软科世界—流学科排名、推荐院校等信息。本实验利用selenium爬虫技术通过驱动谷歌浏览器,完全模拟浏览器的操作,来拿到网页渲染之后的结果。这种技术的优点在于不需要预先考虑Ajax方式动态加载的数据,只需要对渲染之后的页面信息直接进行爬取并分析即可。
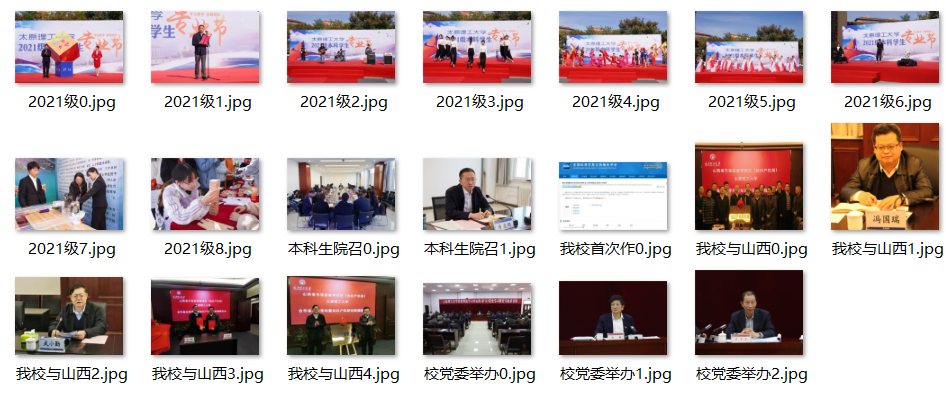
示例2:利用爬虫爬取太原理工大学新闻页面的信息,目标网址为:http://www2017.tyut.edu.cn/。主要爬取的内容包括:每篇新闻的内容信息,图片信息,并将每篇文章的第一句作为本篇文章的摘要。本实验利用selenium爬虫技术通过驱动谷歌浏览器,完全模拟浏览器的操作,来拿到网页渲染之后的结果。
案例图片

相似案例推荐
其他人才的相似案例推荐
-

android车载仪表
基于Android10.0车载仪表 简介:拥有经典、运动、前
-

激光打标软件
激光打标软件 主要应用行业为激光领域;是在深圳大族激光参与
-

Covid-19
搭配公开API获取最新疫情信息以及确诊病例,疑似确诊,治愈病
-

DoubanParser
通过Selenium和BeautifulSoup实现了对豆瓣
-

ZhihuParser
通过对知乎付费咨询所有的讲师的姓名,关注者,咨询价格,已咨询
-

Z-LibraryParser
实现了对Z-Library的热门书籍,最新书籍的书名,简介,
-

程序化广告系统
该系统主要负责下游媒体流量主的对接及上游广告主广告内容对接
-

汽车针阀上料设备
汽车针阀上料设备,软件部分集成了机器视觉和运动控制两个功能模
-

标签定位和检测
光伏组件的标签定位贴合以及标签的瑕疵检测,与客户mes通讯获
-

人脸口罩检测系统
此次人脸口罩检测系统主要是应用在商场、地铁站等人流量多的地方
-

海关数据
海关发布日的下载及其麻烦,下载部分完全是我个人做的。
-

海关下载
海关发布日的下载和自动化实现十分麻烦,下载基本是我负责开发的
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

