
案例介绍
import requests
from lxml import etree
import re
def xiangqi(data):
html_=requests.get(data['link'])
# print(html_)charset=utf-8"
# print(html_.text)
cr=re.findall('charset="(.*?)"', html_.text)
c=cr.count('gbk')
if c<2:
html_.encoding='gbk'
else:
html_.encoding='utf8'
content=''.join(etree.HTML(html_.text).xpath('//p[@class="one-p"]//text()|//div[@class="content_area"]/p/text()')).replace('\n','')
if content:
return content
url='https://i.news.qq.com/trpc.qqnews_web.pc_base_srv.base_http_proxy/NinjaPageContentSync?pull_urls=news_top_2018'
source=requests.get(url).json()
data={}
for i in source['data']:
data['title']=i['title']
data['link']=i['url']
# print(data)
content=xiangqi(data)
data['content'] = content
print(data)
案例图片
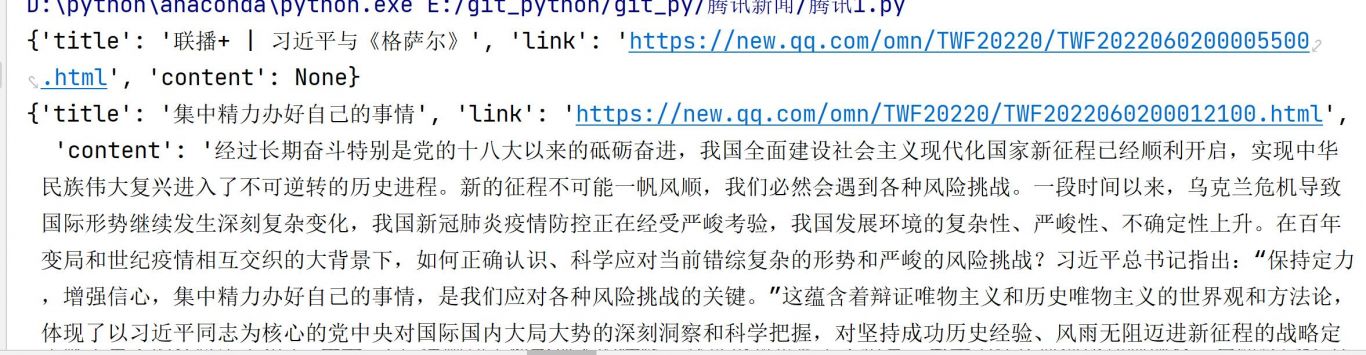

相似案例推荐
其他人才的相似案例推荐
-

工业mes行业
拥有6年的工业互联网平台开发设计经验,参与其中重要功能的设计
-

艺术学院师生优秀作品库管理系统
项目介绍:该项目基于vue+springboot+mybat
-

掌握微信小程序及各类软件开发
您的需求我们已大致了解,我们是专业的软件开发、运维团队,sp
-

密钥管理系统
使用jni调用底层C库使用密码机生成密钥,通过sm2加密算法
-

管理系统
该项目主要是对用户关注的一些关键词进行大数据的分析。 该项
-

安全保障管理系统
巡查管理借助于比较传统的人工管理手段。设备明细使用电子、书面
-

淘宝爬虫
作品介绍:该作品输出想要爬取的商品名称后,点击按钮可以获取淘
-

大众点评爬取
作品功能:该代码爬取大众点评上相应的商家信息以及商品的过往评
-

爬取过英雄联盟官网 英雄对应信息
https://game.gtimg.cn/images/l
-

直播详情实时分析
对平台直播数据完成实时的数据分析,最终暂时在页面,负责整个实
-

金数据
金数据-在线表单编辑工具,数据收集统计平台,产品主要功能有第
-

重点车辆驾驶人
该项目是为客户单位工作人员提供的实时监管平台,主要业务是在客
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

