
案例介绍
用电影网站https://spa2.scrape.center/做示例
我们仔细观察每部电影的URL和Ajax请求API,
例如点击《霸王别姬》,观察URL的变化
可以看到,电影详情页的URL和首页的不一样,
在图2-13 中,URL里的detail后面 直接跟的是id,是1、2、3等数字
但是这里变成了一个长字符串,看着是由Base64编码而成,
也就是说详情页的URL中包含 加密参数,所以我们无法直接根据规律构造详情页的URL
然后,依次点击列表页的第一页到第十页,观察Ajax请求,
可以看到,这里接口的参数多了一个token字段,而且每次请求的token都不同,
这个字段看着同样是由Base64编码而得
更棘手一点的是,API具有时效性,意味着把Ajax接口内URL复制下来,
短期内是可以访问的,但过段时间就访问不了了,会直接返回401状态码
之前我们可以直接用requests构造Ajax请求,但现在Ajax请求接口中带有token,
而且还是可变的。
我们不知道token的生成逻辑,就没法直接构造Ajax请求来爬取数据,怎么办呢?
先分析出token的生成逻辑,再模拟Ajax请求,是一个办法,
可这个办法相对较难,
此时我们可以用Selenium绕过这个阶段,直接获取JavaScript最终渲染完成
的页面源代码。再从中提取数据即可
之后我们要完成如下工作。
通过Selenium遍历列表页,获取每部电影的详情页URL
通过Selenium根据上一步获取的详情页URL 爬取每部电影的详情页
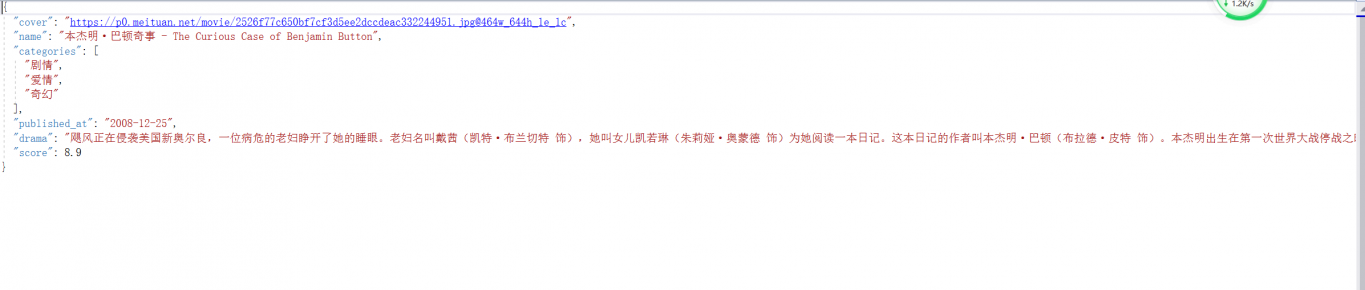
从详情页中提取每部电影的名称、类别、分数、简介、封面等内容
职责:
准备Chrome浏览器并配置好ChromeDriver。
成功运行python和用selenium打开Chrome浏览器。
爬取列表页,详情页,数据存储。
案例图片

相似案例推荐
其他人才的相似案例推荐
-

乐视视频
乐视视频 APP。主要功能有视频播放(跳过片头片尾、视屏截图
-

当贝OS
当贝大屏系统OS 开发者 2021.07-2022.01
-

腾讯视频
腾讯视频(Tencent Video)于2011年4月上线,
-

手机影像小程序
项目名称:手机影像社区 项目描述:手机影像是一款手机图片视
-

冬奥奖牌榜
主要功能: 奖品帮首页:中国奖牌置顶、中国获奖视频、总
-

多媒体视频处理系统发明专利
专利号 ZL201910100464.2《基于并行和边缘计算
-

爬取电影网站
我们仔细观察每部电影的URL和Ajax请求API, 例如点
-

CUDA C++高性能图像视频超分辨率
程序的主要功能是把低分辨率、模糊的图片和视频提高分辨率与去模
-

直播带货系统
直播带货系统集自有商城、直播带货、短视频带货、连麦、主播PK
-

易屏信息发布系统
易屏是一套信息发布系统,暂时的主要作用于公司的出售的显示屏设
-

视频播放器
一个基于Exoplayer二次开发的一个播放器,优化了播放器
-

好看视频
负责商业侧广告 SDK 开发,开发 feed 流广告,视频前
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

