
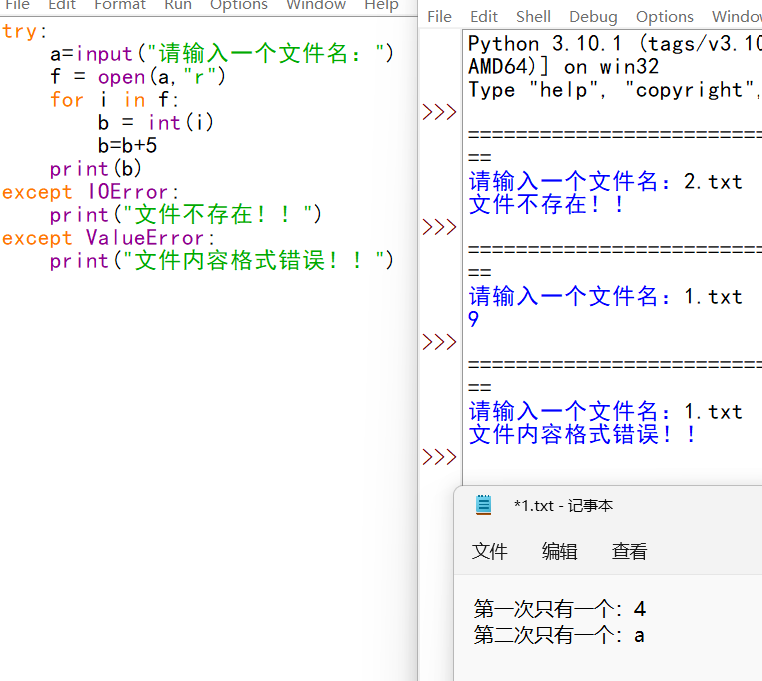
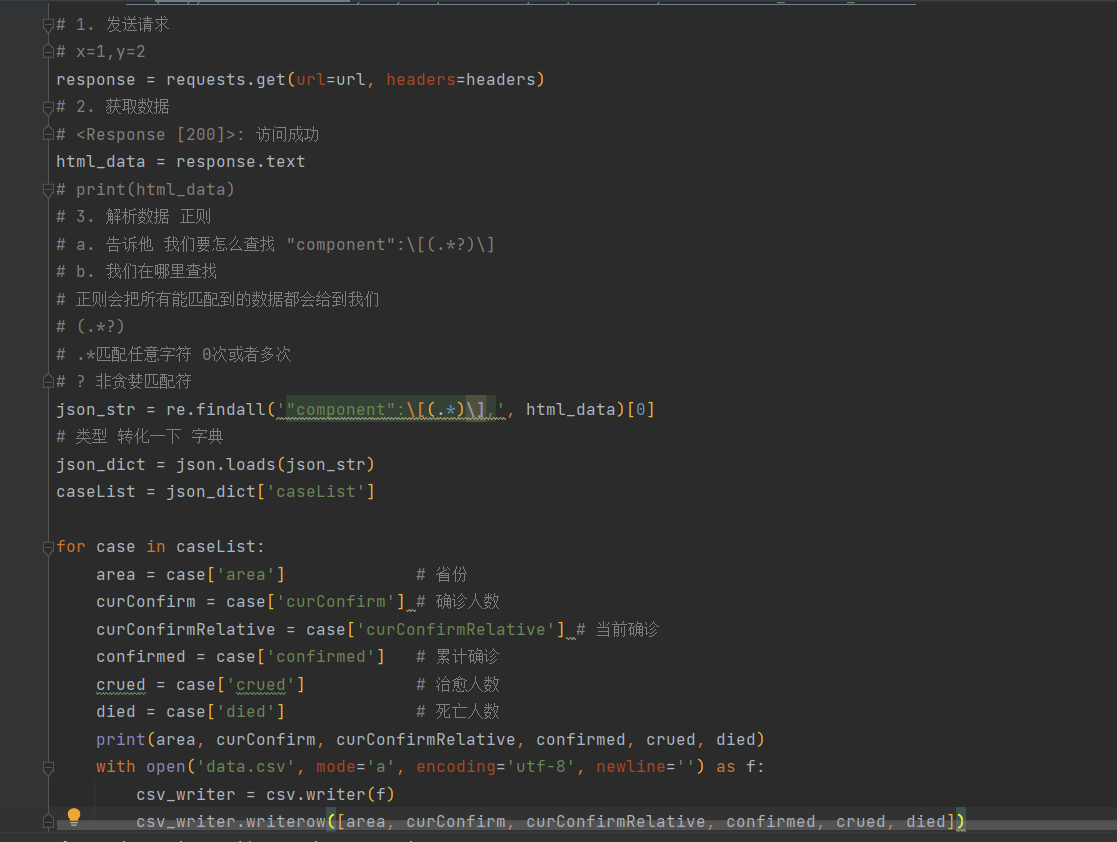
案例介绍
这个项目是通过scrapy-redis搭建分布式爬虫爬取企业信用信息网公布栏,爬取列表页每一项下的子页获取数据
我的职责
首先爬取首页后通过xpath匹配每个的信息块的span后构建请求,并通过scrapy.Request发送请求,用xpath匹配需要的信息。
同时循环创建下一页请求的form表单,通过scrapy.FormRequest发送POST请求。所有爬取的信息缓存到redis数据库中,
最后通过编写python脚本将redis数据库中数据读取出来加入mysql数据库。
其他爬取的网站:搜狐新闻、豆瓣、腾讯新闻网
案例图片
相似案例推荐
其他人才的相似案例推荐
-

有因直播
提供Pass直播服务,依赖阿里云直播流服务,提供商户对应的云
-

商场采购销售一体化商城管理
现代商场管理往往涉及众多的方向内容,本系统用于为商场事务汇总
-

汽车4S店后台运营中心
这个项目是应用于后台运营的管理,主要模块:用户管理:对已注册
-

大数据收入系统
搭建企业级数据仓库、用户画像、feed流推荐系统、app运营
-

大数据后台
搭建企业级数据仓库、用户画像、feed流推荐系统、app运营
-

用户画像
BI分析系统,管理层在线查看报表来对日常运营以及确定app开
-

数据处理
根据文本完成,完成数据整理,归类然后保存为 sqlite 数
-

ocr文字识别
软件可以通过读取pdf文件或图片,使用ocr完成文字识别,并
-

通用后端表格服务
一款通用的后端表格服务,采用Mongo作为配置源,配置元素有
-

通用消息通知服务
一个专门服务于企业平台内的消息通知服务,通过订阅Rabbit
-

数字化作战平台
数字化作战平台 项目介绍:基于 gis 开发地图 项目技
-

事件处理系统
项目名称:事件处理系统 开发周期:4 个月 开发模式:团
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

接收人才推送

联系需求方端客服