
案例介绍
项目名称:通过selenium爬虫爬取百度文库
项目描述:
项目介绍
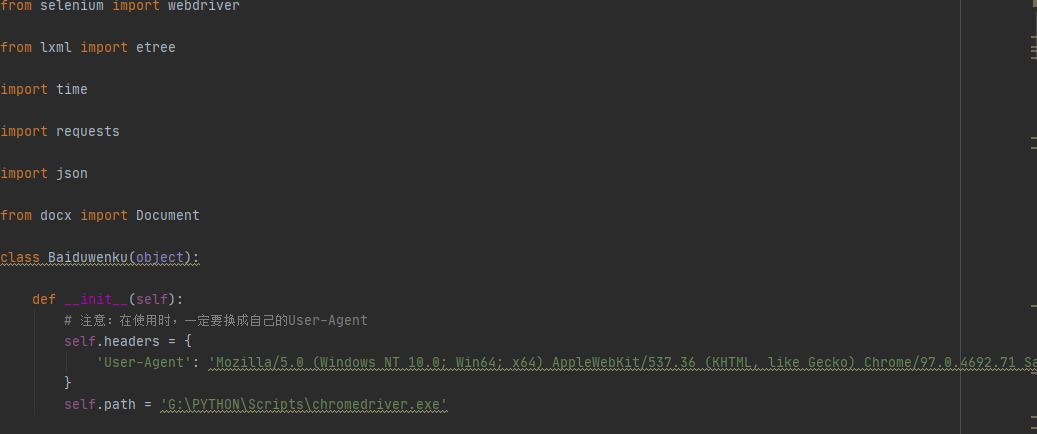
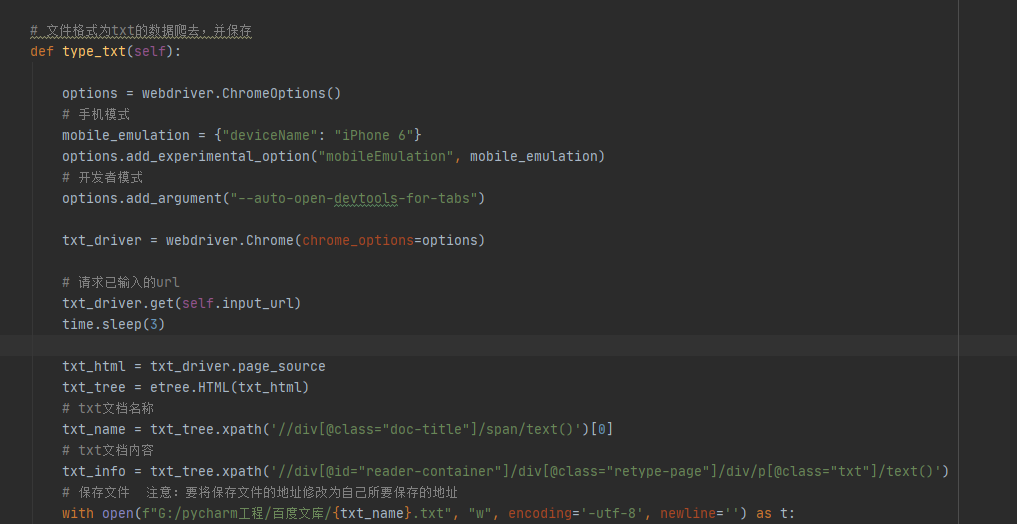
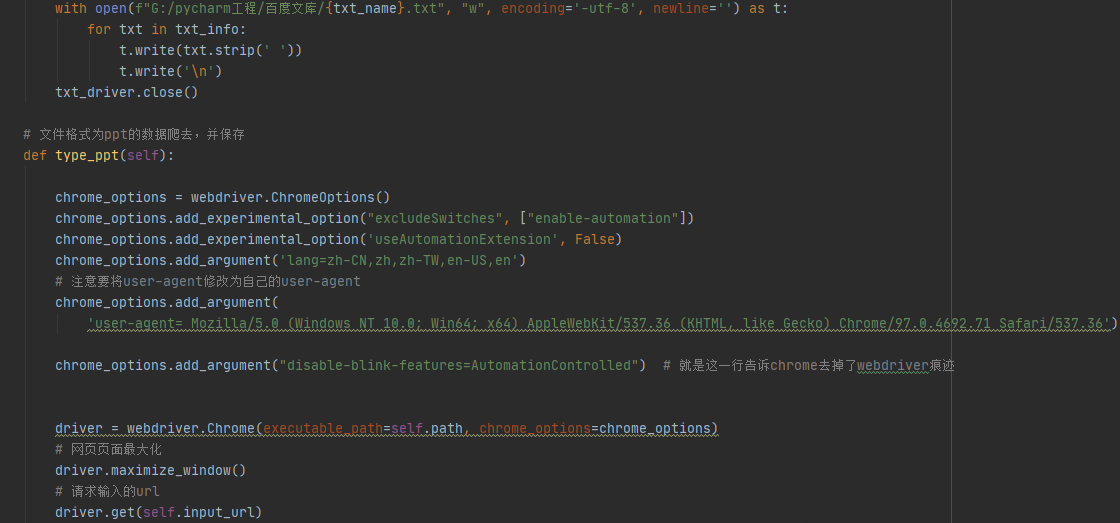
对百度文库页面分析时,发现需要登录后才能看到相关文本内容,源码页面无所需内容,为此需要selenium并携带登录cookie内容,对百度文库相关信息进行爬取,爬取内容格式包括txt,PDF,PPT,Word等。爬取结果分别存储为txt,jpg,Word等格式。
我的职责
1,采用selenium携带cookie,发起请求。
2,通过selenium携带cookie,防止因为页面抓取不到产生数据不全的现象。
3,通过selenium获取来保存cookie,以应对基于cookie的反扒策略
4,使用xpath进行页面解析,解析出的数据通过docx模块存储于doc文件中
案例图片



相似案例推荐
其他人才的相似案例推荐
-

统一支付对账
此系统是用于医院支付系统配置,管理,对账一体的一个系统。包含
-

绿城AI数字化运营项目
项目名称:绿城 AI 数字化运营项目 项目描述:绿城 AI
-

互联网舆情项目
前台主要为一些数据的可视化分析,以呈现数据的效果为主;后台多
-

pubmed文献爬虫及PDF下载
完成在pubmed网站上的文献信息搜索、下载及PDF搜索自动
-

日志系统
Laravel项目可用。 添加各种类型日志,支持制定参数,
-

数据分析报告
据分析报告是通过对项目数据全方位的科学分析来评估项目的可行性
-

港口综合管理系统
项目主要是对重庆海事事务的管理,功能囊括了行业端和企业端两大
-

西安市环境数据中心
系统简述:对西安高新区的大气数据,水质数据,噪声数据,污染源
-

园区管理系统
园区管理系统,后端采用Springboot、mysql、re
-

某某城市管理系统
本项目完成了系统拥有极丰富的数据展示能力,基于大数据处理平台
-

用户画像
BI分析系统,管理层在线查看报表来对日常运营以及确定app开
-

大数据后台
搭建企业级数据仓库、用户画像、feed流推荐系统、app运营
微信接收人才推送
关注猿急送微信平台,接收实时人才推送

